

python爬虫requests使用代理ip
python爬虫requests使用代理ip
一、总结
一句话总结:
a、请求时,先将请求发给代理服务器,代理服务器请求目标服务器,然后目标服务器将数据传给代理服务器,代理服务器再将数据给爬虫。
b、代理服务器是经常变化的,使用代理服务器时传一个参数:proxy,是一个字典的形式。
import requests proxy={ 'http':'58.87.98.150:1080' } response=requests.get("http://httpbin.org/ip",proxies=proxy) print(response.text)
二、python爬虫requests使用代理ip
转自或参考:python爬虫(十) requests使用代理ip - 方木Fengl - 博客园
https://www.cnblogs.com/zhaoxinhui/p/12383760.html
请求时,先将请求发给代理服务器,代理服务器请求目标服务器,然后目标服务器将数据传给代理服务器,代理服务器再将数据给爬虫。
代理服务器是经常变化的
使用代理服务器时传一个参数:proxy。是一个字典的形式。
通过网址:httpbin.org/ip可以看到当前请求得ip地址:

再快代理官网,点击开放代理可以找到一个代理:

在选第一个ip时,报错超时,说明这个ip已经不能用了,再选第二个
import requests proxy={ 'http':'58.87.98.150:1080' } response=requests.get("http://httpbin.org/ip",proxies=proxy) print(response.text)
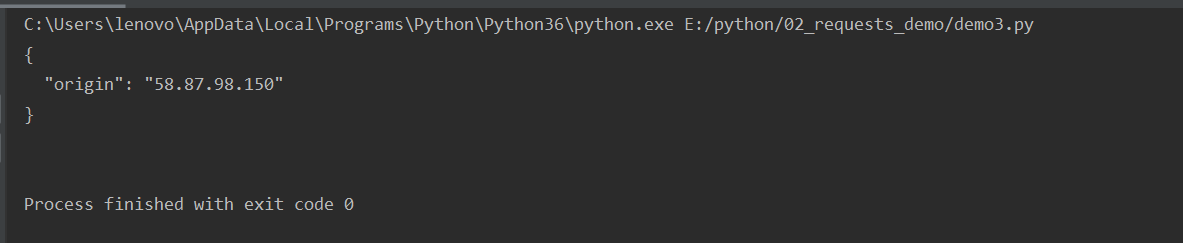
此时得结果就是代理ip

 浙公网安备 33010602011771号
浙公网安备 33010602011771号