课题day1-day2(ECharts与Json与Jsoup爬数据)
ECharts:Examples - Apache ECharts

第一步:快速入门,完成一个网页图表
第二步:idea创建JsonTest,选择Maven.webApp
第三步:编写idea代码
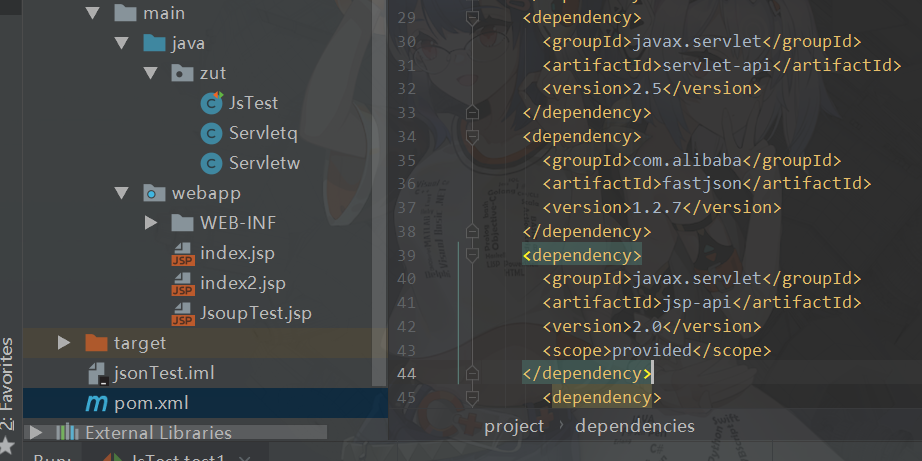
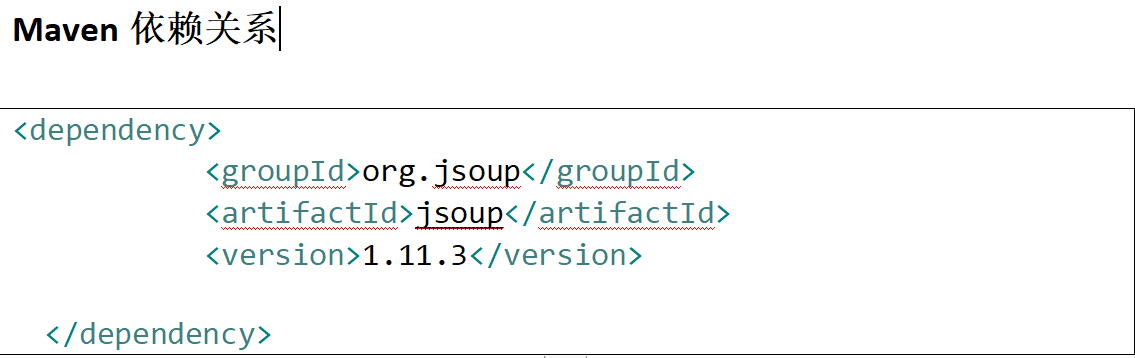
1.导入pom.xml依赖
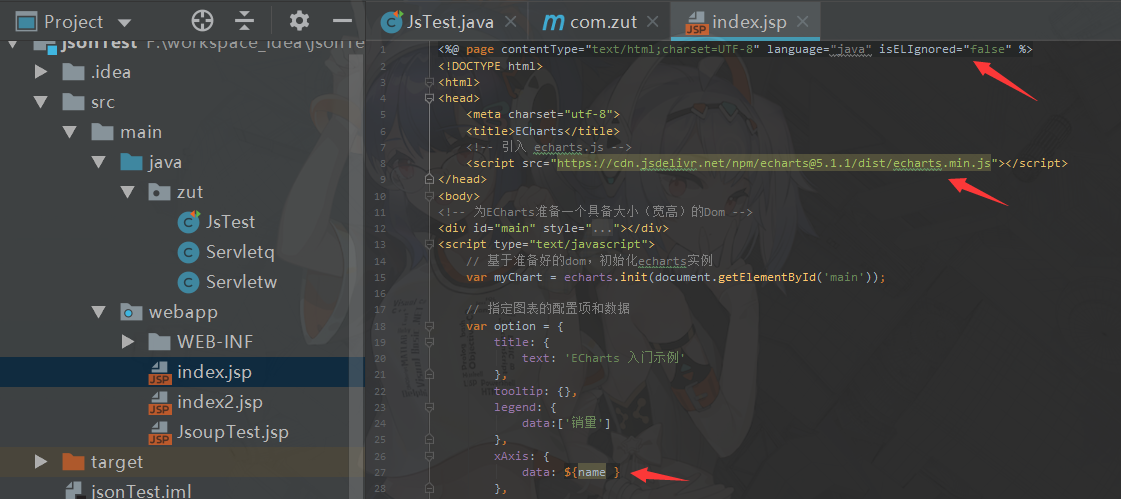
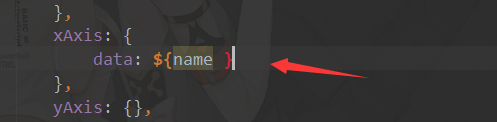
2.编写index.jsp,使用ECharts模板 <1> isELIgnored="false"使用EL表达式 <2>使用ECharts网页 <3>EL表达式传参
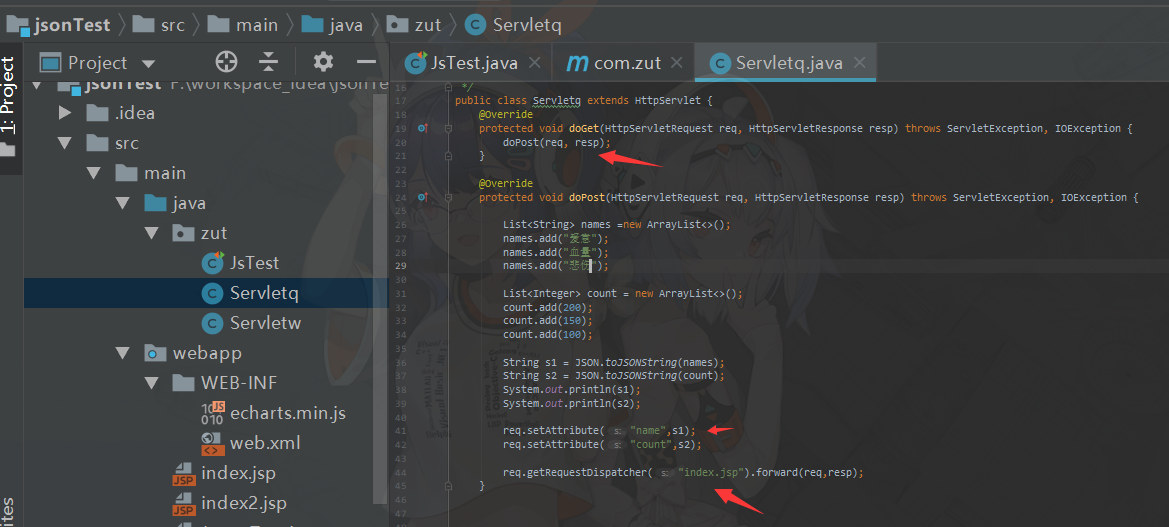
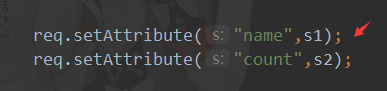
3.编写servlet<1>重写doGet,doPost <2>setAttribute() 方法添加指定的属性,并为其赋指定的值。<3>重定向
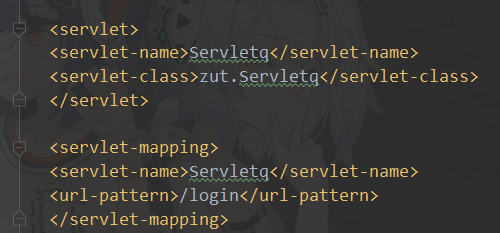
4.配置web.xml
5.执行中遇到的错误


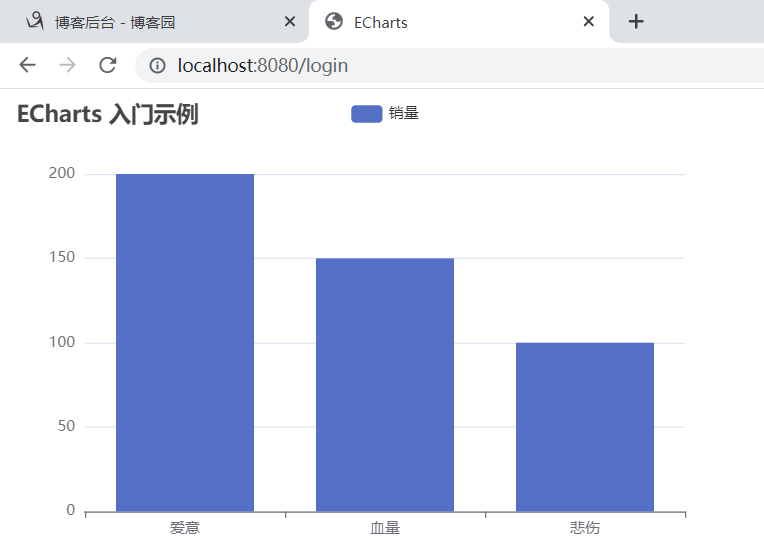
6.执行
第四步:使用Jsoup
Jsoup简介
jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。官网:https://jsoup.org/
主要功能
从一个URL,文件或字符串中解析HTML
使用DOM或CSS选择器来查找、取出数据使用DOM或CSS选择器来查找、取出数据
可操作HTML元素、属性、文本可操作HTML元素、属性、文本
注意:jsoup是基于MIT协议发布的,可放心使用于商业项目。
主要类:
- Jsoup 类提供了连接,清理和解析HTML文档的方法
- Document 获取HTML文档
- Element 获取、操作HTML节点
1.三种加载HTML的方法
|
@Test public void test1() throws IOException { //从URL加载HTML Document document = Jsoup.connect("http://www.baidu.com").get(); String title = document.title(); //获取html中的标题 System.out.println("title :"+title);
//从字符串加载HTML String html = "<html><head><title>First parse</title></head>" + "<body><p>Parsed HTML into a doc.</p></body></html>"; Document doc = Jsoup.parse(html); title = doc.title(); System.out.println("title :"+title);
//从文件加载HTML doc = Jsoup.parse(new File("F:\\jsoup\\html\\index.html"),"utf-8"); title = doc.title(); System.out.println("title :"+title); }
|
2.获取html中的head,body,url等信息
|
@Test public void test2() throws IOException { Document document = Jsoup.connect("http://www.baidu.com").get(); String title = document.title();
System.out.println("title :"+title); //获取html中的head System.out.println(document.head()); //获取html中的body //System.out.println(document.body());
//获取HTML页面中的所有链接 Elements links = document.select("a[href]"); for (Element link : links){ System.out.println("link : "+ link.attr("href")); System.out.println("text :"+ link.text()); } } |
3.获取URL的元信息
|
@Test public void test3() throws IOException { Document document = Jsoup.connect("https://passport.lagou.com").get(); System.out.println(document.head()); //获取URL的元信息 String description = document.select("meta[name=description]").get(0).attr("content"); System.out.println("Meta description : " + description);
String keywords = document.select("meta[name=keywords]").first().attr("content"); System.out.println("Meta keyword : " + keywords); } |
4.根据class名称获取表单
|
@Test public void test4() throws IOException { Document document = Jsoup.connect("https://passport.lagou.com/login/login.html").get(); //获取拉勾网登入页面的body //System.out.println(document.body()); //根据class名称获取表单 Elements formElement = document.getElementsByClass("form_body"); System.out.println(formElement.html()); //获取URL的元信息 for (Element inputElement : formElement) { String placeholder = inputElement.getElementsByTag("input").attr("placeholder"); System.out.println(placeholder); } } |
5.提取并打印表单参数
|
@Test public void test5() throws IOException { Document document = Jsoup.parse(new File("F:\\jsoup\\html\\login.html"),"utf-8"); Element loginform = document.getElementById("registerform");
Elements inputElements = loginform.getElementsByTag("input"); for (Element inputElement : inputElements) { String key = inputElement.attr("name"); String value = inputElement.attr("value"); System.out.println("Param name: "+key+" -- Param value: "+value); } } |
6.设置元素的html内容
|
@Test public void test6() throws IOException { Document document = Jsoup.parse(new File("F:\\jsoup\\html\\index.html"),"utf-8"); System.out.println(document.body());// <div id="div1"></div> System.out.println("*************"); Element div = document.select("div").first(); div.html("<p>Hello</p>"); // <div id="div1"><p>Hello</p></div> div.prepend("<p>Fiest</p>"); //<div id="div1"><p>Fiest</p><p>Hello</p></div> div.append("<p>Last</p>"); //<div id="div1"><p>Fiest</p><p>Hello</p><p>Last</p></div> System.out.println(document.body()); System.out.println("*************"); System.out.println(div.text());
System.out.println("*************"); //对元素包裹一个外部HTML内容 div.wrap("<div id=\"div2\"></div>"); //<div id="div2"><div id="div1"><p>Fiest</p><p>Hello</p><p>Last</p></div> System.out.println(document.body());
} |
7.设置元素的文本内容
|
@Test public void test7() throws IOException { Document document = Jsoup.parse(new File("F:\\jsoup\\html\\index.html"),"utf-8"); System.out.println(document.body());// <div id="div1"></div> System.out.println("*************"); Element div = document.select("div").first(); div.text("7 > 8 "); // <div id="div1">7 > 8 </div> div.prepend("Fiest "); //<div id="div1">Fiest 7 > 8</div> div.append("Last "); //<div id="div1">Fiest 7 > 8 Last</div> System.out.println(document.body()); System.out.println("*************"); System.out.println(div.text()); } |
8.爬取豆瓣即将上映电影页面数据[https://movie.douban.com/coming]
|
@Test public void test8() throws Exception{ Connection conn=Jsoup.connect("https://movie.douban.com/coming").timeout(5000); conn.header("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8"); conn.header("Accept-Encoding", "gzip, deflate, sdch"); conn.header("Accept-Language", "zh-CN,zh;q=0.8"); conn.header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36"); Document document = conn.get(); Element movie_eles_table=document.getElementsByClass("article").get(0); // System.out.println(movie_eles.html()); Elements trEles = movie_eles_table.getElementsByTag("tr"); int i=0; //循环出每一个tr for (Element trEle : trEles) { if(i==0){ i++; continue; } // System.out.println(trEle.getElementsByIndexEquals(1).text()+"\t\t"+trEle.getElementsByIndexEquals(4).text()); String[] tds_text=trEle.getElementsByTag("td").text().split(" "); // System.out.println(tds_text[tds_text.length-1]); System.out.println(trEle.getElementsByAttribute("title").text()+ "\t\t"+tds_text[tds_text.length-1].replaceAll("人", "")); }
} |
拿到数据结合echarts实现图表显示数据
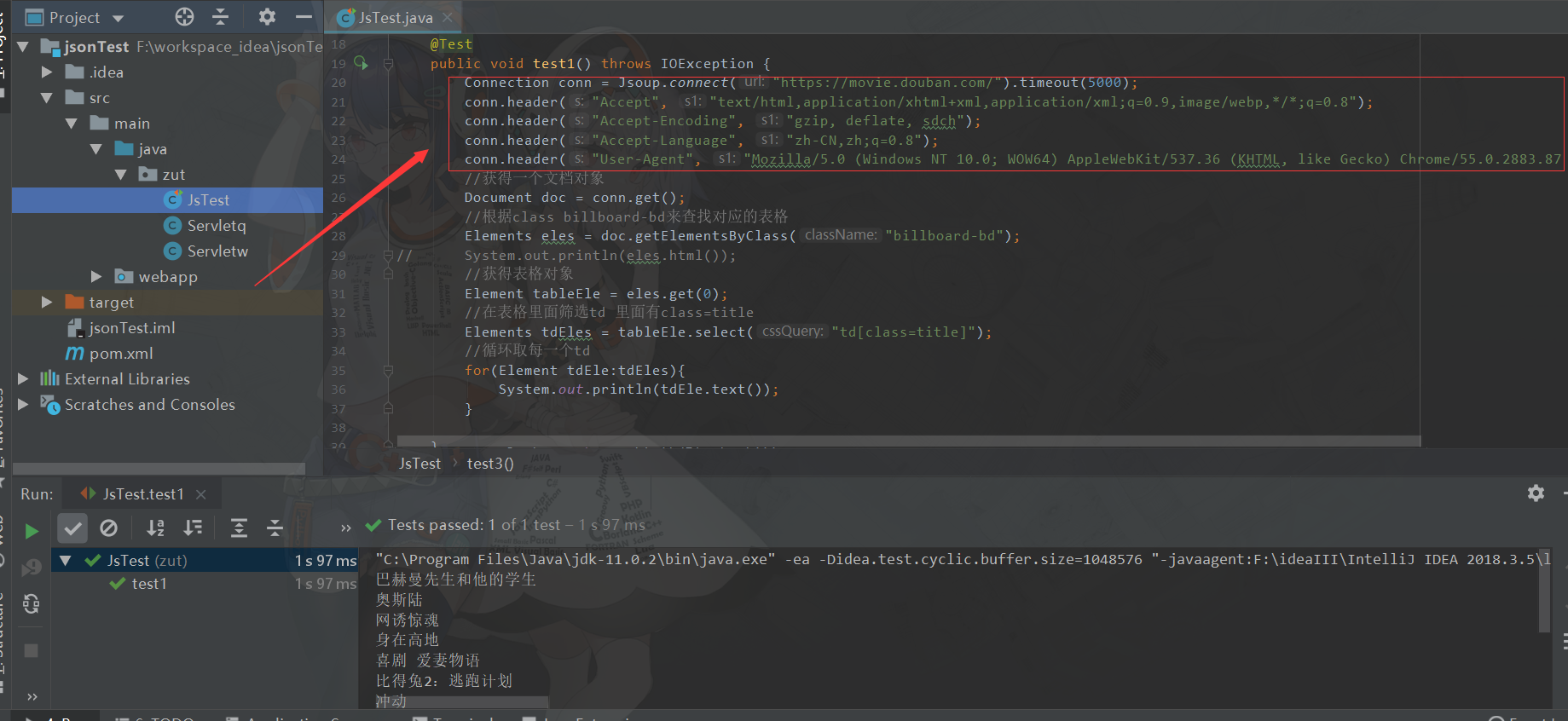
Connection conn = Jsoup.connect("https://movie.douban.com/").timeout(5000);
conn.header("Accept", "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8");
conn.header("Accept-Encoding", "gzip, deflate, sdch");
conn.header("Accept-Language", "zh-CN,zh;q=0.8");
conn.header("User-Agent", "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36");
解决403禁止访问问题。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号