K - Tree 2019icpc南昌K题 (树上启发式合并 dsu on tree)
题目链接:https://nanti.jisuanke.com/t/42586
题意:给一棵n个节点的树,编号1-n,每个点有点权w,问有多少组节点(x,y),满足:
1.x != y
2.x点不是y点的祖先,y点不是x点的祖先
3.x点和y点的最短距离<=k (看了题解才知道,up to k 原来是小于等于k的意思???)
4.设x和y点的公共祖先是z,val【i】表示 i 节点的点权,要求val【z】 * 2 = val【x】 + val【y】
思路:树上启发式合并(dsu on tree)
为了深刻记忆,所以趁着刚学会一点,分享下自己理解的树上启发式合并。(正好用这道题来讲讲)
先贴个流程,下面会详细说为什么,图搬运自大佬的博客:https://blog.csdn.net/qq_44341728/article/details/102825145

对于这个题目,先考虑暴力的做法
假设k = 3,所有点的点权为1,看下图
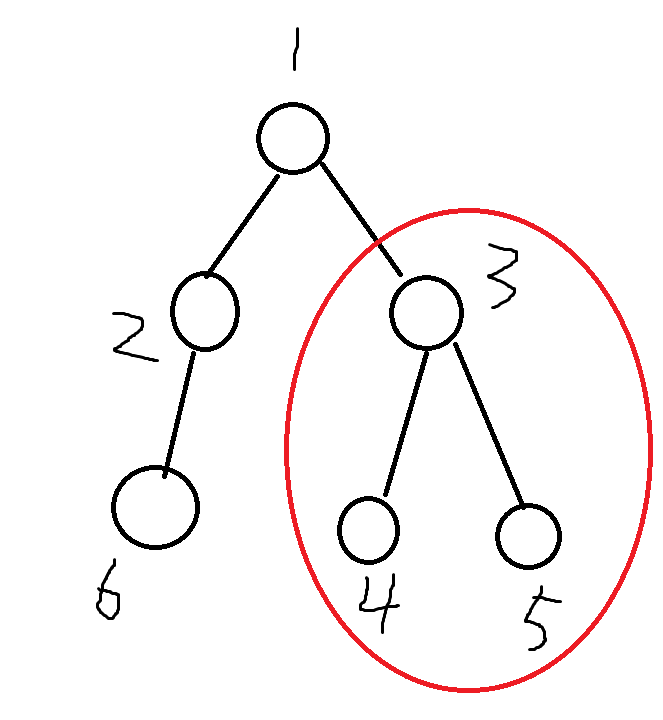
假设要算1号节点为公共节点的贡献,我们观察,2号节点和6号节点显然不能满足条件,因为他们在一条链上,但是2号节点和3,4,5号节点是可以凑出贡献的,也就是2号和红色圈圈住的子树的每一个节点都有可能凑出贡献。
这样就有了一个想法,如果我们知道红色圈住的子树的信息,我就可以直接算出左边每个点贡献(2节点和6节点)
这里用若干个线段树来维护信息,每个权值都开一棵权值线段树,维护某个权值在某个深度出现的次数。
举个例子(上面有假设所有点权值为1),假如1号节点深度为1,那么3号节点深度为2, 4,5号节点深度为3,那么对于权值为1的线段树,维护的信息就是:深度为2的点有1个,深度为3的点有2个。
算2号节点的贡献时,算出另一个匹配节点的权值应该是val【1】 * 2 - val【2】 = 1 * 2 - 1 = 1, 深度最大是: k + 2 * dep【1】 - dep【2】 = 3 + 2 - 2 = 3
所以就应该查红框的子树内,权值为1的线段树,深度区间在【1,3】的点有多少个,这里查到3个(即3,4,5号节点)。(关键)
PS:提一嘴深度最大值怎么算,假设z是x和y的最近公共祖先,则x和y的距离 = dep【x】 + dep【y】 - 2 * dep【z】,题目要求 x和y的距离<=k, 所以换个位置就是:dep【y】<= k + dep【z】 * 2 - dep【x】
算6号节点的贡献时,同理,应该查红框的子树内,权值为1的线段树,深度区间在【1,2】的点有多少个,这里查到1个(即3号节点)。
那么对于3号节点为根的子树来说,统计方法也一样,只要我知道2号节点为根子树信息,可以用一样的方法来算。
有人可能会问:那4号和5号节点怎么统计?他们会在算3号节点为公共节点的时候算,因为算最大深度的时候需要用到最近公共祖先,所以两个点若有贡献,那这两个点都应该在不同的子树上。
重点来了,暴力的做法就是对于每个节点,我都维护这个节点为根的子树的所有信息,即n个权值的线段树,显然空间爆炸,直接MLE
那么考虑在全局开n个权值的线段树,每个节点都用全局的线段树来维护信息,但也是空间爆炸。所以考虑动态开点,每棵线段树只开遍历到的点。
空间的问题解决了,然后考虑时间,因为只有全局的线段树,他是所有节点共享的,做答案统计的时候要确保使用的时候数据是对的。
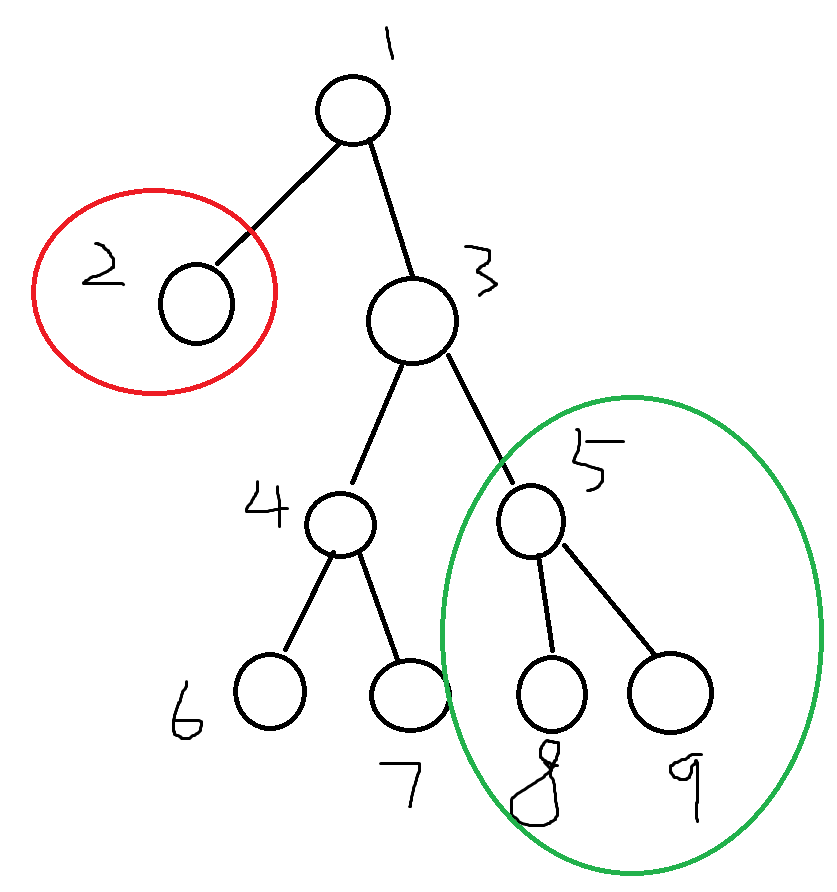
先来说明一下为什么会有数据对不对的问题,递归地往下跑,假如先跑到2号节点,把2号节点信息更新到线段树里面,然后递归回去跑3号节点子树。
当统计3号节点为根的答案时,假设已经跑完了以5号节点为根的子树,现在要计算4号节点的贡献,按照上面的思路,就应该找5号节点为根子树,查某个权值某个区间有多少个点。
关键的地方来了,因为2号节点的数据已经更新到线段树里了,如果不做处理直接查,那就会出问题,查的信息都不对了。
如果暴力的解决这个问题,就是每次使用线段树的时候,都先清空,然后跑对应的子树每个节点,更新到线段树上,最后再查询。
这么做显然n方,时间不允许,重点又来了,这里就正式开始介绍树上启发式合并了,他可以把时间优化到n*logn。(确实啰嗦了点,但为了照顾像我一样的小白,就决定说得仔细一些......)
注意到,当统计以3号节点为根节点的答案时,除了他子树包含的点,其他点都毫无用处,即2号节点的信息此时不应该出现在线段树里。
那么我们把2号节点的信息删掉不就行?当我统计完3号节点的答案后,我再把2号节点的信息加回线段树里面,这不就完美了。
然后再看看时间复杂度,如果先统计2号节点为根的子树,再统计3号节点为根的子树,那么操作就是:
跑2号节点为根的子树,期间把子树每个节点都更新到线段树上,跑完后在线段树上删除子树的每个节点(为了消除都其他子树的影响),然后跑3号节点为根的子树,期间把子树每个节点都更新到线段树上,跑完后发现1号节点的子树都跑完了,结束递归。那么发现,3号节点的子树信息就不需要删除了,也就是说,如果一个节点i有n个子树,可以选择一个子树只跑一次(加信息),其他子树都要跑三次(加信息(统计答案)+删信息(消除对其他子树的影响)+加信息(维护i节点子树的信息,递归出去要给其他节点用))
重点又双叒叕来了!
根据上面的分析,显然要选一棵最大的子树最后跑,会使得时间最优,这就是树上启发式合并的关键思想,并且这样就可以使得时间变为nlogn。
实际上就是先跑轻儿子及其子树,再跑重儿子及其子树。(重儿子:父亲节点的所有儿子中子树结点数目最多(size最大)的结点,轻儿子就是除重儿子之外的其他节点,树链剖分的内容)
树上启发式合并就学完了!除了换了一下遍历儿子的顺序,省了一次消影响(重儿子的影响不用减了),好像与暴力没其它区别了!!
但这个优化就让整个时间复杂度降到了严格 n*logn,而且可以如下证明:(证明也是搬运别人博客的:https://blog.csdn.net/qq_44341728/article/details/102825145)

代码:
#include<bits/stdc++.h> #define ll long long using namespace std; const int maxn = 1e5 + 7; int sz[maxn],val[maxn],dep[maxn],son[maxn]; int T[maxn],ls[maxn*200],rs[maxn*200],tr[maxn*200],cnt,n,k; ll ans; vector<int>E[maxn]; void dfs1(int u) {//预处理每个节点的大小sz,深度dep和每个节点的重儿子son sz[u] = 1; for (auto v:E[u]) { dep[v] = dep[u] + 1; dfs1(v); sz[u] += sz[v]; if(sz[v] > sz[son[u]]) son[u] = v; } } void update(int &rt,int l,int r,int pos,int c) { if(!rt) rt = ++cnt; // 注意,动态开点 tr[rt] += c; if(l == r) return ; int mid = l + r >> 1; if(pos<=mid) update(ls[rt],l,mid,pos,c); if(mid<pos) update(rs[rt],mid+1,r,pos,c); } ll query(int rt,int l,int r,int L,int R) { if(!rt) return 0; if(L<=l && r<=R) return tr[rt]; int mid = l + r >> 1; ll ans = 0; if(L<=mid) ans += query(ls[rt],l,mid,L,R); if(mid<R) ans += query(rs[rt],mid+1,r,L,R); return ans; } void add(int u) { update(T[val[u]],1,n,dep[u],1); for (auto v:E[u]) add(v); } void del(int u) {//删除u节点及其子树在线段树上的信息 update(T[val[u]],1,n,dep[u],-1); for (auto v:E[u]) del(v); } void gao(int u,int fa) { int d = k + 2 * dep[fa] - dep[u];//最大深度 int w = 2 * val[fa] - val[u];//另一个点的点权 d = min(d,n); if(w >= 0 && w <= n) ans += query(T[w],1,n,1,d); for (auto v:E[u]) gao(v,fa);//子树的每个点都要暴力统计 } void dfs2(int u) { // 树上启发式合并 for (auto v:E[u]) { // 1.先跑轻儿子及其子树,跑完后暴力删除 if(v == son[u]) continue; dfs2(v);//跑轻儿子v及其子树 del(v);//删除轻儿子v及其子树 } if(son[u]) dfs2(son[u]);//2.跑重儿子,不删 for (auto v:E[u]) {//3.把所有轻儿子都加回来 if(v == son[u]) continue; gao(v,u);//统计答案 (以u为根节点,其中一个点在v及其 子树) add(v); } update(T[val[u]],1,n,dep[u],1);//把自己也加上 } int main() { int x; scanf("%d%d",&n,&k); for (int i=1; i<=n; ++i) { scanf("%d",&val[i]); //每个点的点权val } for (int i=2; i<=n; ++i) { scanf("%d",&x); E[x].push_back(i); } dep[1] = 1; dfs1(1); dfs2(1);//关键看这里 printf("%lld",ans * 2); return 0; }

