最速下降法(Python实现)
最速下降法(Python实现)
使用最速下降法方向,分别使用Armijo准则和Wolfe准则来求步长
求解方程
\(f(x_1,x_2)=(x_1^2-2)^4+(x_1-2x_2)^2\)的极小值
import numpy as np
import tensorflow as tf
def fun(x): # 函数f(x)
# return 100 * (x[0] ** 2 - x[1]) ** 2 + (x[0] - 1) ** 2 测试用
return (x[0] - 2) ** 4 + (x[0] - 2 * x[1]) ** 2
def gfun(x): # 梯度grad
x = tf.Variable(x, dtype=tf.float32)
with tf.GradientTape() as tape:
tape.watch(x)
z = fun(x)
return tape.gradient(z, x).numpy() # 这里使用TensorFlow来求梯度,直接手算梯度返回也行
# return np.array([4 * (x[0] - 2) ** 3 + 2 * (x[0] - 2*x[1]), -4 * (x[0] - 2*x[1])])
def grad_wolfe(fun, gfun, x0): # 使用wolfe准则来求步长因子的最速下降法
maxk = 5000
k = 0
epsilon = 1e-5
while k < maxk:
gk = gfun(x0)
dk = -gk
if np.linalg.norm(dk) < epsilon:
break
rho = 0.4
sigma = 0.5
a = 0
b = np.inf
alpha = 1
while True:
if not ((fun(x0) - fun(x0 + alpha * dk)) >= (-rho * alpha * gfun(x0).T @ dk)):
b = alpha
alpha = (a + alpha) / 2
continue
if not (gfun(x0 + alpha * dk).T @ dk >= sigma * gfun(x0).T @ dk):
a = alpha
alpha = np.min([2 * alpha, (alpha + b) / 2])
continue
break
x0 = x0 + alpha * dk
k += 1
x = x0
val = fun(x)
return x, val, k
def grad_armijo(fun, gfun, x0): # 使用armijo准则来求最速下降法的步长因子
maxk = 5000
rho = 0.5
sigma = 0.4
k = 0
epsilon = 1e-5
while k < maxk:
g = gfun(x0)
d = -g
if np.linalg.norm(d) < epsilon:
break
m = 0
mk = 0
while m < 20:
if fun(x0 + rho ** m * d) < fun(x0) + sigma * rho ** m * g.T @ d:
mk = m
break
m += 1
x0 = x0 + rho ** mk * d
k += 1
x = x0
val = fun(x0)
return x, val, k
if __name__ == '__main__':
x0 = np.array([[0.], [3.]])
x, val, k = grad_armijo(fun, gfun, x0) # Armijo准则
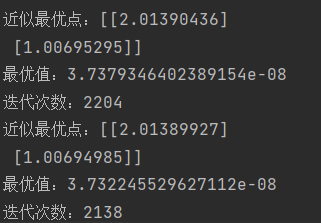
print('近似最优点:{}\n最优值:{}\n迭代次数:{}'.format(x, val.item(), k))
x, val, k = grad_wolfe(fun, gfun, x0) # Wolfe准测
print('近似最优点:{}\n最优值:{}\n迭代次数:{}'.format(x, val.item(), k))
运行结果:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号