Gradient Descent(梯度下降)
梯度下降
线性模型
\(\hat{y}=x*w\)来拟合学习时间\(x\)与考试分数\(y\)

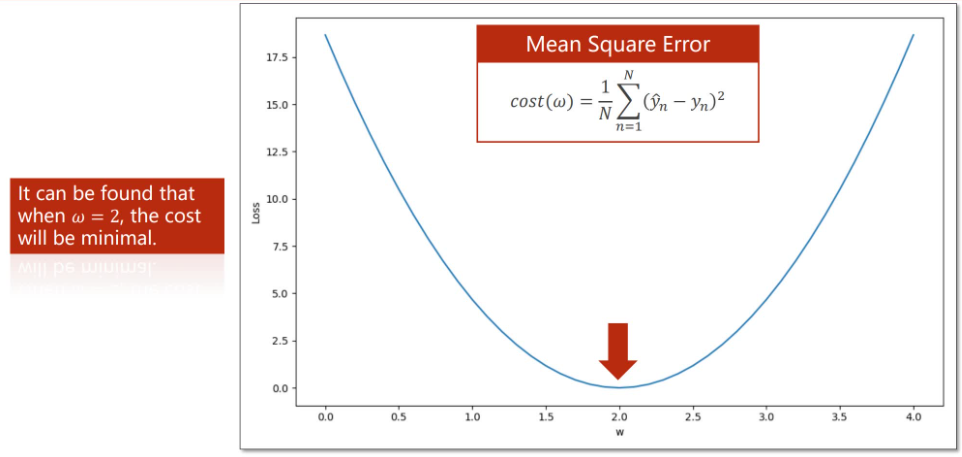
\[loss=(\hat{y}-y)^2=(x*w-y)^2\to cost=\frac1N\sum^N_{n=1}(\hat{y_n}-y_n)^2
\]
由图可知损失函数在\(w=2.0\)时,取得最小值。记损失函数在\(w^*\)处取得最小值
\[w^*=\arg_w min\ cost(w)
\]
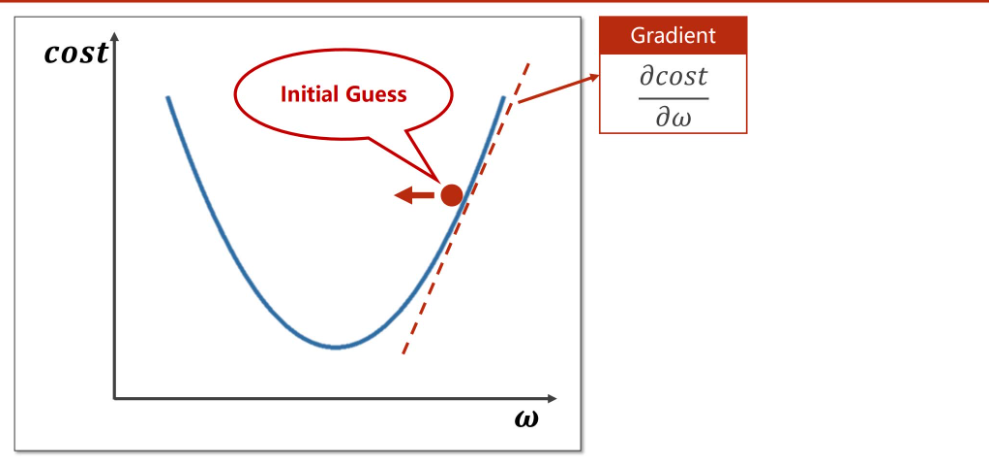
假定w的初始位置在Initial Guess处,在这点处的梯度为\(\frac{\partial cost}{\partial w}\),此时梯度为正数,沿着梯度方向\(cost\)变化最快,可以通过沿梯度方向变化最快方向来更新\(w\),通过公式:\(w=w-\alpha\frac{\partial cost}{\partial w}\)来更新\(w\),\(\alpha\)为学习率,也可以理解成沿梯度下降方向迈出步伐的大小。
\[\frac{\partial cost(\omega)}{\partial\omega}= \frac{\partial}{\partial\omega}\frac1N\sum^N_{n=1}(x_n*w-y_n)^2 \\
= \frac1N\sum^N_{n=1}\frac{\partial}{\partial\omega}(x_n\cdot w-y_n)^2 \\
= \frac1N\sum^N_{n=1}2\cdot(x_n\cdot\omega-y_n)\frac{\partial(x_n\cdot\omega-y_n)}{\partial\omega}\\
= \frac1N\sum^N_{n=1}2\cdot x_n\cdot (x_n\cdot\omega-y_n)\]
\[w=w-\alpha\frac1N\sum^N_{n=1}2\cdot x_n\cdot (x_n\cdot w-y_n)
\]
x_data = [1.0, 2.0, 3.0] # 准备数据
y_data = [2.0, 4.0, 6.0]
w = 1.0 # 初始化权重w为1.0
def forward(x):
return x*w # 定义线性模型y=x*w
def cost(xs, ys): # 定义损失函数
cost = 0
for x, y in zip(xs, ys):
y_pred = forward(x)
cost += (y_pred-y)**2 # 损失等于每个数据的和
return cost/len(xs) # 除以数据个数来获得均方误差差
def gradient(xs, ys): # 定义梯度函数
grad = 0
for x, y in zip(xs, ys):
grad += 2*x*(x*w-y) # 根据前面的公式计算在该点的梯度
return grad/len(xs)
print('Predict (before training', 4, forward(4)) # 输出训练之前的x=4和y_pred
for epoch in range(100): # 训练100伦
cost_val = cost(x_data, y_data) # 计算损失函数
grad_val = gradient(x_data, y_data) # 计算梯度
w -= 0.01*grad_val # 通过梯度和学习率来调整权重
print('Epoch', epoch, 'w=', w, 'loss=', cost_val)
print('Predict (after training)', 4, forward(4)) # 输出训练之后的x=4和y_pred
Epoch 90 w= 1.9998658050763347 loss= 1.0223124683409346e-07
Epoch 91 w= 1.9998783299358769 loss= 8.403862850836479e-08
Epoch 92 w= 1.9998896858085284 loss= 6.908348768398496e-08
Epoch 93 w= 1.9998999817997325 loss= 5.678969725349543e-08
Epoch 94 w= 1.9999093168317574 loss= 4.66836551287917e-08
Epoch 95 w= 1.9999177805941268 loss= 3.8376039345125727e-08
Epoch 96 w= 1.9999254544053418 loss= 3.154680994333735e-08
Epoch 97 w= 1.9999324119941766 loss= 2.593287985380858e-08
Epoch 98 w= 1.9999387202080534 loss= 2.131797981222471e-08
Epoch 99 w= 1.9999444396553017 loss= 1.752432687141379e-08
Predict (after training) 4 7.999777758621207
随机梯度下降(SGD)Stochastic Gradient Descent
\[w=w-\alpha\frac{\partial cost}{\partial w}\to w=w-\alpha\frac{\partial loss}{\partial w}
\]
\[\frac{\partial cost}{\partial w}=\frac1N\sum_{n=1}^N2\cdot x_n\cdot(x_n\cdot w-y_n)\to\frac{\partial loss_n}{\partial w}=2\cdot x_n\cdot(x_n\cdot w-y_n)
\]
def loss(x,y):
y_pred=forward(x)
return (y_pred-y)**2
\(loss=(\hat{y}-y)^2=(x*w-y)^2\)
def graident(x,y):
return 2*x*(x*w-y)
\(\frac{\partial loss_n}{\partial w}=2\cdot x_n\cdot(x_n\cdot w-y_n)\)
for epoch in range(100):
for x,y in zip(x_data,y_data):
grad=gradient(x,y)
w=-=0.01*grad
print('\tgrad:',x,y,grad)
l=loss(x,y)
更新权重使用训练集每个样本的梯度,而不是梯度的平均

 浙公网安备 33010602011771号
浙公网安备 33010602011771号