
电影评论分类:二分类问题
IMDB数据集
它包含来自互联网电影数据库(IMDB)的50000条严重两极分化的评论
数据集被分为用于训练的25000条评论与用于测试的25000条评论
训练集和测试集都包含50%的正面评论和50%的负面评论
加载IMDB数据集
import tensorflow as tf
from tensorflow import keras
from keras.datasets import imdb
import warnings
warnings.filterwarnings('ignore')
(train_data,train_labels),(test_data,test_labels)=imdb.load_data(num_words=10000)
# num_words=10000是仅保留训练数据中前10000最常出现的单词
train_data[0]
[1,
14,
22,
16,
43,
530,
973,
1622,
1385,
65,
458,
4468,
66,
3941,
4,
173,
36,
256,
5,
25,
100,
43,
838,
112,
50,
670,
2,
9,
35,
480,
284,
5,
150,
4,
172,
112,
167,
2,
336,
385,
39,
4,
172,
4536,
1111,
17,
546,
38,
13,
447,
4,
192,
50,
16,
6,
147,
2025,
19,
14,
22,
4,
1920,
4613,
469,
4,
22,
71,
87,
12,
16,
43,
530,
38,
76,
15,
13,
1247,
4,
22,
17,
515,
17,
12,
16,
626,
18,
2,
5,
62,
386,
12,
8,
316,
8,
106,
5,
4,
2223,
5244,
16,
480,
66,
3785,
33,
4,
130,
12,
16,
38,
619,
5,
25,
124,
51,
36,
135,
48,
25,
1415,
33,
6,
22,
12,
215,
28,
77,
52,
5,
14,
407,
16,
82,
2,
8,
4,
107,
117,
5952,
15,
256,
4,
2,
7,
3766,
5,
723,
36,
71,
43,
530,
476,
26,
400,
317,
46,
7,
4,
2,
1029,
13,
104,
88,
4,
381,
15,
297,
98,
32,
2071,
56,
26,
141,
6,
194,
7486,
18,
4,
226,
22,
21,
134,
476,
26,
480,
5,
144,
30,
5535,
18,
51,
36,
28,
224,
92,
25,
104,
4,
226,
65,
16,
38,
1334,
88,
12,
16,
283,
5,
16,
4472,
113,
103,
32,
15,
16,
5345,
19,
178,
32]
train_labels[0]
1
[max([max(sequence)for sequence in train_data])] # 前10000个最常见的单词,单词索引不会超过10000
[9999]
word_index=imdb.get_word_index() # word_index是一个将单词映射为整数的字典
reverse_word_index=dict(
[(value,key)for (key,value) in word_index.items()]) # 键值颠倒,将整数索引映射为单词
decoded_review=' '.join([
reverse_word_index.get(i-3,'?')for i in train_data[0]
]) # 将评论解码,索引减去了3,因为0、1、2是为padding(填充)、start of sequence(序列开始)、unknown(未知词)分别保留的索引
准备数据
import numpy as np
def vectorize_sequences(sequences,dimension=10000):
results=np.zeros((len(sequences),dimension)) # 创建一个形状为(len(sequences),dimension)的零矩阵
for i,sequence in enumerate(sequences):
results[i,sequence]=1. # 将results[i]的索引设置为1
return results
X_train=vectorize_sequences(train_data)
X_test=vectorize_sequences(test_data) # 将数据向量化
X_train[0]# 向量化后数据
array([0., 1., 1., ..., 0., 0., 0.])
y_train=np.array(train_labels).astype('float32') # 将标签向量化
y_test=np.array(test_labels).astype('float32')
y_train
array([1., 0., 0., ..., 0., 1., 0.], dtype=float32)
构建网络
模型定义
from keras import models
from keras import layers
model=models.Sequential()
model.add(layers.Dense(16,activation='relu',input_shape=[10000,]))
model.add(layers.Dense(16,activation='relu'))
model.add(layers.Dense(1,activation='sigmoid'))
2021-09-27 21:09:53.396263: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcuda.so.1
2021-09-27 21:09:53.472257: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-09-27 21:09:53.473082: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1733] Found device 0 with properties:
pciBusID: 0000:01:00.0 name: NVIDIA GeForce RTX 3060 Laptop GPU computeCapability: 8.6
coreClock: 1.702GHz coreCount: 30 deviceMemorySize: 5.81GiB deviceMemoryBandwidth: 312.97GiB/s
2021-09-27 21:09:53.473156: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcudart.so.11.0
2021-09-27 21:09:53.481835: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcublas.so.11
2021-09-27 21:09:53.481910: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcublasLt.so.11
2021-09-27 21:09:53.485108: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcufft.so.10
2021-09-27 21:09:53.486878: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcurand.so.10
2021-09-27 21:09:53.489126: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcusolver.so.11
2021-09-27 21:09:53.491392: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcusparse.so.11
2021-09-27 21:09:53.491984: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcudnn.so.8
2021-09-27 21:09:53.492082: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-09-27 21:09:53.492386: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-09-27 21:09:53.492756: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1871] Adding visible gpu devices: 0
2021-09-27 21:09:53.493101: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN) to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2021-09-27 21:09:53.493983: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-09-27 21:09:53.494378: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1733] Found device 0 with properties:
pciBusID: 0000:01:00.0 name: NVIDIA GeForce RTX 3060 Laptop GPU computeCapability: 8.6
coreClock: 1.702GHz coreCount: 30 deviceMemorySize: 5.81GiB deviceMemoryBandwidth: 312.97GiB/s
2021-09-27 21:09:53.494501: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-09-27 21:09:53.494754: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-09-27 21:09:53.494977: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1871] Adding visible gpu devices: 0
2021-09-27 21:09:53.495238: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcudart.so.11.0
2021-09-27 21:09:54.053755: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1258] Device interconnect StreamExecutor with strength 1 edge matrix:
2021-09-27 21:09:54.053791: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1264] 0
2021-09-27 21:09:54.053797: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1277] 0: N
2021-09-27 21:09:54.053989: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-09-27 21:09:54.054601: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-09-27 21:09:54.055029: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:937] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2021-09-27 21:09:54.055310: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1418] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 3784 MB memory) -> physical GPU (device: 0, name: NVIDIA GeForce RTX 3060 Laptop GPU, pci bus id: 0000:01:00.0, compute capability: 8.6)
编译模型
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
# 使用rmsprop优化器,binary_crossentropy损失函数来配置模型
验证方法
X_val=X_train[:10000] # 留出10000个样本作为验证集
partial_X_train=X_train[10000:]
y_val=y_train[:10000]
partial_y_train=y_train[10000:]
训练模型
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
history=model.fit(partial_X_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(X_val,y_val))
2021-09-27 21:09:55.068570: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:176] None of the MLIR Optimization Passes are enabled (registered 2)
2021-09-27 21:09:55.069321: I tensorflow/core/platform/profile_utils/cpu_utils.cc:114] CPU Frequency: 3293895000 Hz
Epoch 1/20
2021-09-27 21:10:06.815229: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcublas.so.11
19/30 [==================>...........] - ETA: 0s - loss: 0.6202 - acc: 0.6564
2021-09-27 21:10:07.491653: I tensorflow/stream_executor/platform/default/dso_loader.cc:53] Successfully opened dynamic library libcublasLt.so.11
2021-09-27 21:10:07.491710: I tensorflow/stream_executor/cuda/cuda_blas.cc:1838] TensorFloat-32 will be used for the matrix multiplication. This will only be logged once.
30/30 [==============================] - 13s 34ms/step - loss: 0.5807 - acc: 0.7005 - val_loss: 0.3785 - val_acc: 0.8654
Epoch 2/20
30/30 [==============================] - 0s 16ms/step - loss: 0.3154 - acc: 0.9049 - val_loss: 0.3115 - val_acc: 0.8781
Epoch 3/20
30/30 [==============================] - 0s 16ms/step - loss: 0.2223 - acc: 0.9327 - val_loss: 0.3158 - val_acc: 0.8698
Epoch 4/20
30/30 [==============================] - 0s 16ms/step - loss: 0.1757 - acc: 0.9443 - val_loss: 0.3511 - val_acc: 0.8573
Epoch 5/20
30/30 [==============================] - 0s 15ms/step - loss: 0.1445 - acc: 0.9561 - val_loss: 0.2798 - val_acc: 0.8891
Epoch 6/20
30/30 [==============================] - 0s 16ms/step - loss: 0.1179 - acc: 0.9666 - val_loss: 0.3308 - val_acc: 0.8743
Epoch 7/20
30/30 [==============================] - 0s 15ms/step - loss: 0.0939 - acc: 0.9742 - val_loss: 0.3078 - val_acc: 0.8843
Epoch 8/20
30/30 [==============================] - 0s 16ms/step - loss: 0.0778 - acc: 0.9797 - val_loss: 0.3289 - val_acc: 0.8810
Epoch 9/20
30/30 [==============================] - 0s 16ms/step - loss: 0.0643 - acc: 0.9830 - val_loss: 0.3504 - val_acc: 0.8795
Epoch 10/20
30/30 [==============================] - 0s 16ms/step - loss: 0.0546 - acc: 0.9880 - val_loss: 0.3877 - val_acc: 0.8752
Epoch 11/20
30/30 [==============================] - 0s 16ms/step - loss: 0.0445 - acc: 0.9906 - val_loss: 0.4087 - val_acc: 0.8758
Epoch 12/20
30/30 [==============================] - 1s 17ms/step - loss: 0.0334 - acc: 0.9944 - val_loss: 0.4304 - val_acc: 0.8748
Epoch 13/20
30/30 [==============================] - 0s 15ms/step - loss: 0.0297 - acc: 0.9940 - val_loss: 0.4595 - val_acc: 0.8733
Epoch 14/20
30/30 [==============================] - 0s 16ms/step - loss: 0.0213 - acc: 0.9968 - val_loss: 0.5709 - val_acc: 0.8600
Epoch 15/20
30/30 [==============================] - 0s 16ms/step - loss: 0.0198 - acc: 0.9976 - val_loss: 0.5357 - val_acc: 0.8664
Epoch 16/20
30/30 [==============================] - 0s 16ms/step - loss: 0.0158 - acc: 0.9981 - val_loss: 0.5745 - val_acc: 0.8682
Epoch 17/20
30/30 [==============================] - 0s 15ms/step - loss: 0.0112 - acc: 0.9989 - val_loss: 0.6031 - val_acc: 0.8665
Epoch 18/20
30/30 [==============================] - 0s 15ms/step - loss: 0.0083 - acc: 0.9992 - val_loss: 0.6395 - val_acc: 0.8670
Epoch 19/20
30/30 [==============================] - 0s 16ms/step - loss: 0.0056 - acc: 0.9997 - val_loss: 0.6643 - val_acc: 0.8653
Epoch 20/20
30/30 [==============================] - 0s 14ms/step - loss: 0.0038 - acc: 0.9999 - val_loss: 0.6918 - val_acc: 0.8646
调用moodel.fit()返回了一个History对象。这个对象有一个成员history是一个字典,包含训练过程中的所有数据
history_dict=history.history
history_dict.keys()
dict_keys(['loss', 'acc', 'val_loss', 'val_acc'])
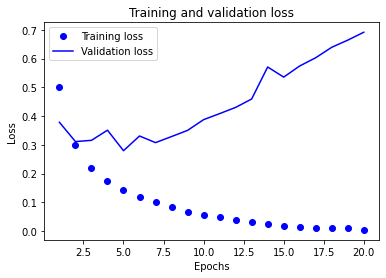
绘制训练损失和验证损失
import matplotlib.pyplot as plt
history_dict=history.history
loss_values=history_dict['loss']
val_loss_values=history_dict['val_loss']
epochs=range(1,len(loss_values)+1)
plt.plot(epochs,loss_values,'bo',label='Training loss')
plt.plot(epochs,val_loss_values,'b',label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
<matplotlib.legend.Legend at 0x7ff3bf5f18e0>
绘制训练精度和验证精度
plt.clf()
acc=history_dict['acc']
val_acc=history_dict['val_acc']
plt.plot(epochs,acc,'bo',label='Training acc')
plt.plot(epochs,val_acc,'b',label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
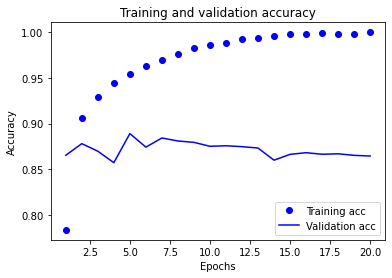
为了防止拟合,可以在第三轮之后停止训练
从头开始从新训练一个模型
model=models.Sequential()
model.add(layers.Dense(16,activation='relu',input_shape=[10000,]))
model.add(layers.Dense(16,activation='relu'))
model.add(layers.Dense(1,activation='sigmoid'))
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
model.fit(X_train,y_train,epochs=4,batch_size=512)
results=model.evaluate(X_test,y_test)
2021-09-27 21:10:18.351156: W tensorflow/core/framework/cpu_allocator_impl.cc:80] Allocation of 1000000000 exceeds 10% of free system memory.
Epoch 1/4
49/49 [==============================] - 1s 10ms/step - loss: 0.5550 - accuracy: 0.7375
Epoch 2/4
49/49 [==============================] - 0s 10ms/step - loss: 0.2718 - accuracy: 0.9129
Epoch 3/4
49/49 [==============================] - 0s 9ms/step - loss: 0.2014 - accuracy: 0.9307
Epoch 4/4
49/49 [==============================] - 0s 9ms/step - loss: 0.1621 - accuracy: 0.9434
2021-09-27 21:10:21.517788: W tensorflow/core/framework/cpu_allocator_impl.cc:80] Allocation of 1000000000 exceeds 10% of free system memory.
782/782 [==============================] - 2s 2ms/step - loss: 0.2919 - accuracy: 0.8845
results
[0.29189127683639526, 0.8844799995422363]
使用训练好的网络在新数据上生成预测结果
model.predict(X_test)
2021-09-27 21:10:24.312851: W tensorflow/core/framework/cpu_allocator_impl.cc:80] Allocation of 1000000000 exceeds 10% of free system memory.
array([[0.19328508],
[0.99986005],
[0.9216948 ],
...,
[0.20816731],
[0.09685578],
[0.6103842 ]], dtype=float32)
进一步的实验
- 前面使用了两个隐藏层,可以尝试使用一个或三个隐藏层,然后观察对验证精度和测试精度的影响
- 尝试使用更多或更少的隐藏单元
- 尝试使用mse损失函数代替binary_crossentropy
- 尝试使用tanh激活函数代替relu
小结
- 通常需要对原始数据进行大量预处理,以便于将其转换为张量输入到神经网络中。单词序列可以编码为二进制向量,但也有其他编码方式
- 带有relu激活的Dense层叠加,可以解决很多种问题(包括情感分类)
- 对于二分类问题(两个输出类别),网络的最后一层应该是只有一个单元并使用sigmoid激活的Dense层,网络输出应该是0-1范围内的标量,表示概率值
- 对于二分类的sigmoid标量输出,应该使用binary_crossentropy损失函数
- 无论什么问题,rmsprop优化器通常都是足够好的选择
- 随着神经网络在训练数据上的表现越来越好,模型最终会过拟合,并在前所未见的数据上得到越来越差的结果。一定要一直监控模型在训练集之外的数据上的性能

 浙公网安备 33010602011771号
浙公网安备 33010602011771号