卷积神经网络(高级篇)
构建高级卷积神经网络
以Google Net为例
GoogleNet的模型图为
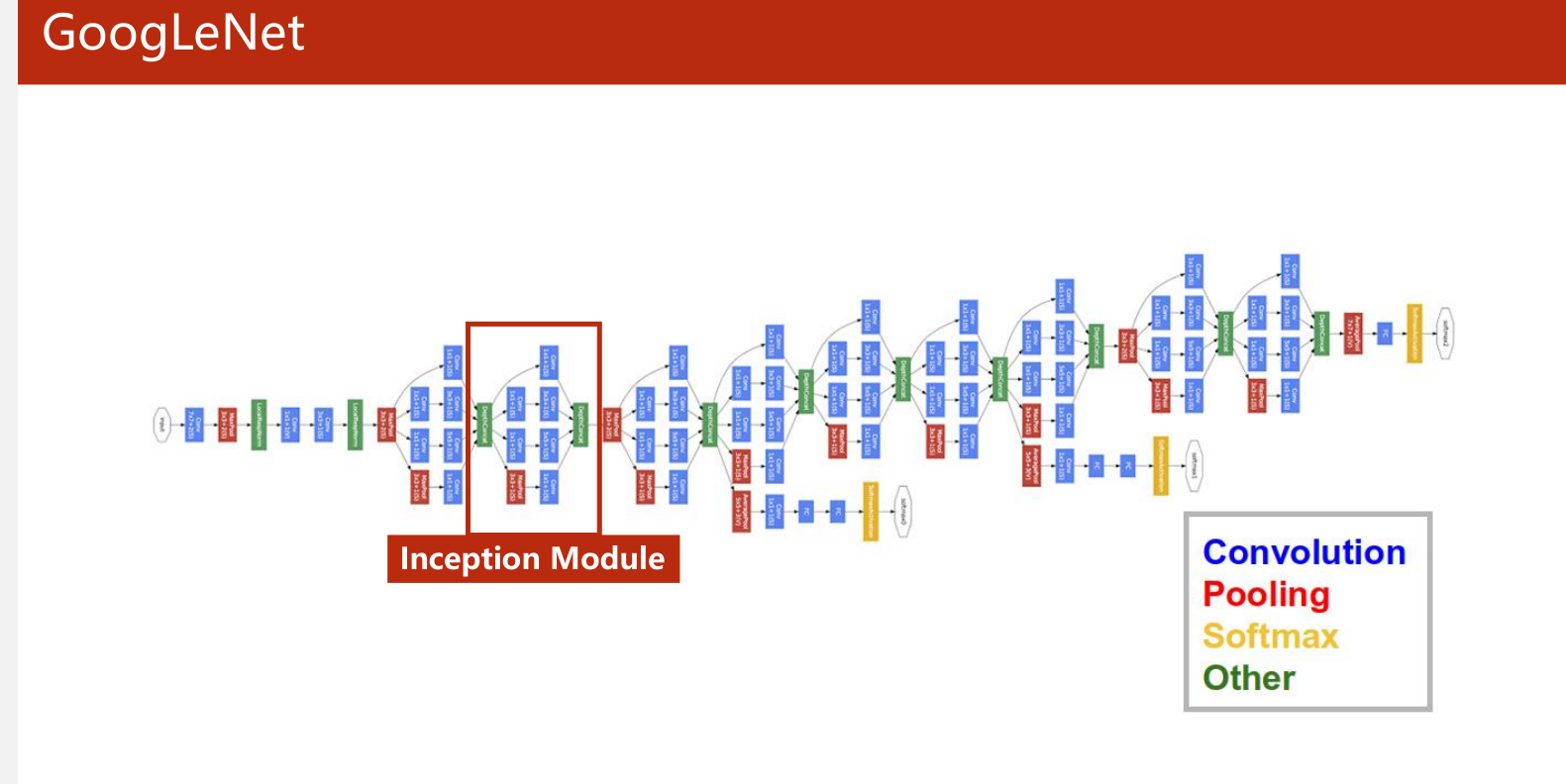
可以看到其中有一个模块反复使用 Inception Module
Inception Module
模型的具体结构图为
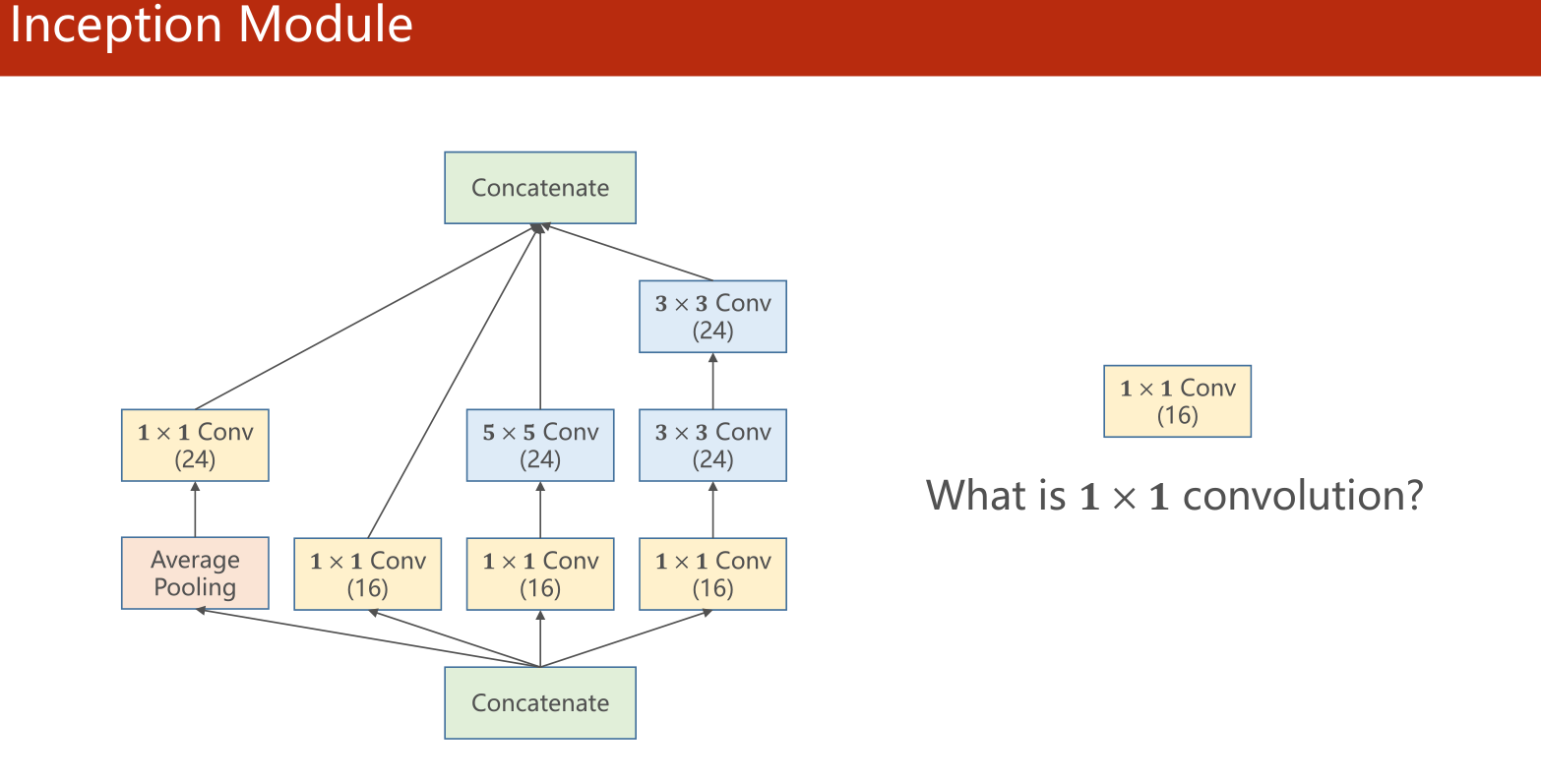
个人理解这个模块是将数据经过不同的卷积方式并保持图像大小不变得到不同的通来获得更多的信息,然后将最后的数据按通道拼接在一起。在某种程度上就是将数据通过多个滤波器提取信息,最后将信息按通道拼在一起。
因此我们可以将这个模块写成类来将其实例化后反复调用,实现代码复用
这里我们将图像转过来方便看
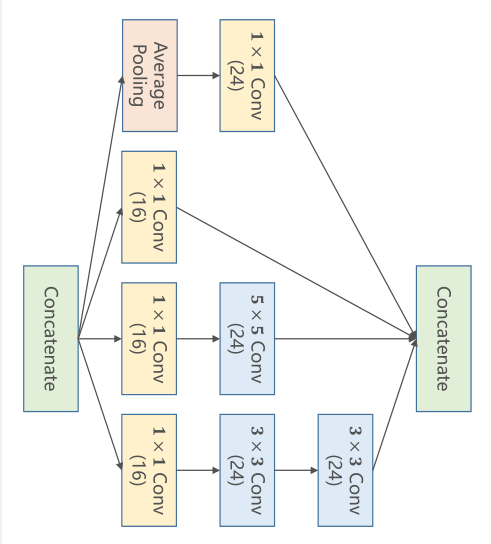
平均池化后通过1x1的卷积核
self.branch_pool=nn.Conv2d(in_channels,24,kernel_size=1)# 定义1x1卷积层
branch_pool=F.avg_pool2d(x,kernel_size=3,stride=1,padding=1)# 定义池化层,并通过调整stride步长和padding填充来使得图像大小不变
branch_pool=self.branch_pool(branch_pool)
直接通过1x1的卷积核
self.branch1x1=nn.Conv2d(in_channels,16,kernel=1)
branch1x1=self.branc1x1(x)
经过1x1的卷积核后通过5x5的卷积核
self.branch5x5_1=nn.Conv2d(in_channels,16,kernel_size=1)
self.branch5x5_2=nn.Conv2d(16,24,kernel_size=5,padding=2)# 通过填充padding来使得图像大小不变
branch5x5=self.branch5x5_1(x)
branch5x5=self.branch5x5_2(branch5x5)
经过1x1、3x3、3x3卷积核
self.branch3x3_1=nn.Conv2d(in_channels,16,kernel_size=1)
self.branch3x3_2=nn.Conv2d(16,24,kernel_size=3,padding=1)
self.branch3x3_3=nn.Conv2d(24,24,kernel_size=3,padding=1)
branch3x3=self.branch3x3_1(x)
branch3x3=self.branch3x3_2(branch3x3)
branch3x3=self.branch3x3_3(branch3x3)
将四个输出按通道拼接在一起
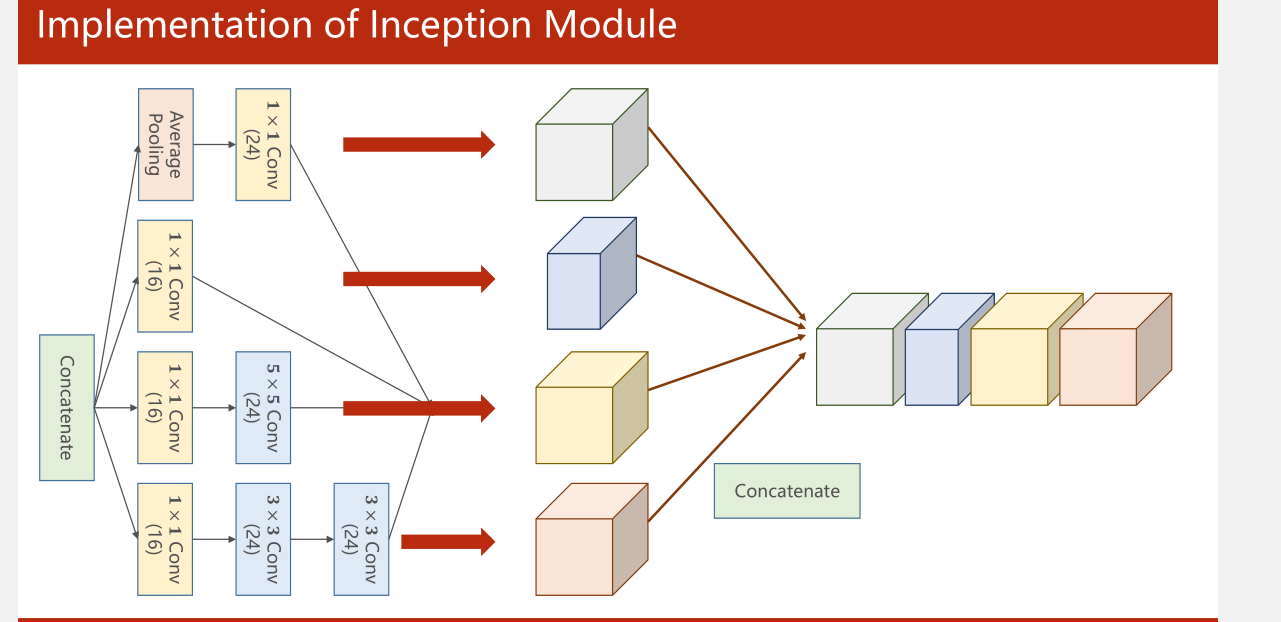
outputs=[branh1x1,branch5x5,branch3x3,branch_pool]
return torch.cat(outputs,dim=1)
#(batch_size,channels,height,width)
#dim=1是第二维度也就是通道维度
完整代码如下
class InceptionA(nn.Module):
def __init__(self,in_channels):
super(self,InceptionA).__init__()
self.branch1x1=nn.Conv2d(in_channels,16,kernel_size=1)
self.branch5x5_1=nn.Conv2d(in_channles,16,kernel_size=1)
self.branch5x5_2=nn.Conv2d(16,24,kernel_size=5,padding=2)
self.branch3x3_1=nn.Conv2d(in_channels,16,kernel_size=1)
self.branch3x3_2=nn.Conv2d(16,24,kernel_size=3,padding=1)
self.branch3x3_3=nn.Conv2d(24,24,kernel_size=3,padding=1)
self.branch_pool=nn.Conv2d(in_channles,24,kernel_size=1)
def forward(self,x):
branch1x1=self.branch1x1(x)
branch5x5=self.branch5x5_1(x)
branch5x5=self.branch5x5_2(branch5x5)
branch3x3=self.branch3x3_1(x)
branch3x3=self.branch3x3_2(branch3x3)
branch3x3=self.branch3x3_3(branch3x3)
branch_pool=F.avg_pool2d(x,kernel_size=3,stride=1,padding=1)
branch_pool=self.branch_pool(branch_pool)
outputs=[branch1x1,branch5x5,branch3x3,branch_pool]
return torch.cat(outputs,dim=1)
然后可以用这个模块来写网络
class Net(nn.Module):
def __init__(self):
super(Net,self).__init__()
self.conv1=nn.Conv2d(1,10,kernel_size=5)#卷积层1
self.conv2=nn.Conv2d(88,20,kernel_size=5)#卷积层2
self.incep1=InceptionA(in_channels=10)#模块1
self.incep2=InceptionA(in_channels=20)#模块2
self.mp=nn.MaxPool2d(2)#最大池化层
self.fc=nn.Linear(1408,10)#全连接层
def forward(self,x):#数据形状为(batch_size,in_channel,height,width)
in_size=x.size(0)#获取张量的批数(batch_size,1,28,28)
x=F.relu(self.mp(self.conv1(x)))#卷积后经过最大池化层后使用激活函数(1,28,28)->(10,24,24)->(10,12,12)
x=self.incep1(x)#经过模块1后,通道数为24+16+24+24=88个通道 (10,12,12)->(88,12,12)
x=F.relu(self.mp(self.conv2(x)))#通过卷积层2后通道数为20 (88,12,12)->(20,8,8)->(20,4,4)
x=self.incep2(x)#经过模块2后输出通道为88 (20,4,4)->(88,4,4)
x=x.view(in_size,-1)#批数不变,将图像展平 88*4*4=1408
x=self.fc(x)#将展平后数据送进全连接层
# 因为kernel_size=5,而且没有做填充卷积后,图像变化(kernel_size-stride)/2
#这里kernel_size=5,默认stride=1,(5-1)/2=4
#池化后,大小是向下取整
return x
还是以MNIST数据集作为案例代码如下
import torch
from torch import nn
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = datasets.MNIST(root='./dataset/mnist/',
train=True,
download=True,
transform=transform)
train_loader = DataLoader(dataset=train_dataset,
shuffle=True,
batch_size=batch_size,
num_workers=4)
test_dataset = datasets.MNIST(root='./dataset/mnist/',
train=False,
download=True,
transform=transform)
test_loader = DataLoader(dataset=test_dataset,
shuffle=False,
batch_size=batch_size,
num_workers=4)
class InceptionA(nn.Module): # 构建一个模块
# 仅是一个模块,其中的输入通道数并不能够指明
def __init__(self, in_channels):
super(InceptionA, self).__init__()
self.branch1x1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch5x5_1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch5x5_2 = nn.Conv2d(16, 24, kernel_size=5, padding=2)
self.branch3x3_1 = nn.Conv2d(in_channels, 16, kernel_size=1)
self.branch3x3_2 = nn.Conv2d(16, 24, kernel_size=3, padding=1)
self.branch3x3_3 = nn.Conv2d(24, 24, kernel_size=3, padding=1)
self.branch_pool = nn.Conv2d(in_channels, 24, kernel_size=1)
def forward(self, x):
branch1x1 = self.branch1x1(x)
branch5x5 = self.branch5x5_1(x)
branch5x5 = self.branch5x5_2(branch5x5)
branch3x3 = self.branch5x5_1(x)
branch3x3 = self.branch3x3_2(branch3x3)
branch3x3 = self.branch3x3_3(branch3x3)
branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)
branch_pool = self.branch_pool(branch_pool)
outputs = [branch1x1, branch5x5, branch3x3, branch_pool]
return torch.cat(outputs, dim=1)
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
# 在Inception的定义中,拼接后的输出通道数为24+16+24+24=88个
self.conv2 = nn.Conv2d(88, 20, kernel_size=5)
self.incep1 = InceptionA(in_channels=10)
self.incep2 = InceptionA(in_channels=20)
self.mp = nn.MaxPool2d(2)
# 关于1408:
# 每次卷积核是5x5,则卷积后原28x28的图像变为24x24的
# 再经过最大池化,变为12x12的
# 以此类推最终得到4x4的图像,又inception输出通道88,则转为一维后为88x4x4=1408个
self.fc = nn.Linear(1408, 10)
def forward(self, x):
in_size = x.size(0)
x = F.gelu(self.mp(self.conv1(x)))
x = self.incep1(x)
x = F.gelu(self.mp(self.conv2(x)))
x = self.incep2(x)
x = x.view(in_size, -1)
x = self.fc(x)
return x
model = Net()
device = torch.device('cuda:0' if torch.cuda.is_available() else 'CPU')
model.to(device)
criterion = torch.nn.CrossEntropyLoss().to(device)
optimizer = torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.5)
def train(epoch):
running_loss = 0
for batch_idx, data in enumerate(train_loader):
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss
if batch_idx % 300 == 299:
print('[%d,%5d] loss:%.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0.0
def test():
corrent = 0.0
total = 0.0
with torch.no_grad():
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, prediction = torch.max(outputs, dim=1)
total += labels.size(0)
corrent += (prediction == labels).sum().item()
print('Accuracy on test set %.3f %%' % (100 * corrent / total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
运行结果:

最终模型在训练集上达到了98%准确率,已经超过了人类识别的准确率(95%)
模型架构如下:
Net(
(conv1): Conv2d(1, 10, kernel_size=(5, 5), stride=(1, 1))
(conv2): Conv2d(88, 20, kernel_size=(5, 5), stride=(1, 1))
(incep1): InceptionA(
(branch1x1): Conv2d(10, 16, kernel_size=(1, 1), stride=(1, 1))
(branch5x5_1): Conv2d(10, 16, kernel_size=(1, 1), stride=(1, 1))
(branch5x5_2): Conv2d(16, 24, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(branch3x3_1): Conv2d(10, 16, kernel_size=(1, 1), stride=(1, 1))
(branch3x3_2): Conv2d(16, 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(branch3x3_3): Conv2d(24, 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(branch_pool): Conv2d(10, 24, kernel_size=(1, 1), stride=(1, 1))
)
(incep2): InceptionA(
(branch1x1): Conv2d(20, 16, kernel_size=(1, 1), stride=(1, 1))
(branch5x5_1): Conv2d(20, 16, kernel_size=(1, 1), stride=(1, 1))
(branch5x5_2): Conv2d(16, 24, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(branch3x3_1): Conv2d(20, 16, kernel_size=(1, 1), stride=(1, 1))
(branch3x3_2): Conv2d(16, 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(branch3x3_3): Conv2d(24, 24, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(branch_pool): Conv2d(20, 24, kernel_size=(1, 1), stride=(1, 1))
)
(mp): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(fc): Linear(in_features=1408, out_features=10, bias=True)
)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号