使用顺序API构建图像分类器
使用Keras加载数据集
import tensorflow as tf
from tensorflow import keras
fashion_mnist=keras.datasets.fashion_mnist
(X_train_full,y_train_full),(X_test,y_test)=fashion_mnist.load_data()
X_train_full.shape#查看训练集的形状
(60000, 28, 28)
X_train_full.dtype#查看训练集的数据类型
dtype('uint8')
将数据集划分为训练集,验证集和测试集
像素强度表示为整数0-255,由于我们要使用梯度下降神经网络,因此必须缩放输入特征。
因为将像素强度除以255.0将之转化为0-1之间的浮点数
X_valid,X_train=X_train_full[:5000]/255.0,X_train_full[5000:]/255.0
y_valid,y_train=y_train_full[:5000],y_train_full[5000:]
对于MNIST当标签等于5时,说明图像代表手写数字5。但是对于Fashion MNIST,我们需要一个类名列表来知道我们要处理的内容
class_names=['T-shirt/top','Trouser','Pullover','Dress','Coat','Sandal','Shirt','Sneaker','Bag','Ankle boot']
例如训练集中的第一幅图像代表一件外套
class_names[y_train[0]]
'Coat'
使用顺序API创建模型,建立一个具有两个隐藏层的分类MLP
典型的回归MLP架构
| 超参数 | 典型值 |
|---|---|
| 输入神经元的数量 | 每个输入特征一个(例如,MNIST为28*28=784) |
| 隐藏层数量 | 取决于问题,但通常为1到5 |
| 每个隐藏层的神经元数量 | 取决于问题,但通常为10到100 |
| 输出神经元数量 | 每个预测维度输出1个神经元 |
| 隐藏的激活 | ReLU(或SELU) |
| 输出激活 | 无,或ReLU/softplus(如果为正输出)或逻辑/tanh(如果为有界输出) |
| 损失函数 | MSE或MAE/Huber(如果存在离群值) |
典型的MLP架构
| 超参数 | 二进制分类 | 多标签二进制分类 | 多类分类 |
|---|---|---|---|
| 输入层和隐藏层 | 与回归相同 | 与回归相同 | 与回归相同 |
| 输出神经元数量 | 1 | 每个标签1 | 每个类1 |
| 输出层激活 | 逻辑 | 逻辑 | softmax |
| 损失函数 | 交叉熵 | 交叉熵 | 交叉熵 |
model=keras.models.Sequential()
model.add(keras.layers.Flatten(input_shape=[28,28]))
model.add(keras.layers.Dense(300,activation='relu'))
model.add(keras.layers.Dense(100,activation='relu'))
model.add(keras.layers.Dense(10,activation='softmax'))
可以不用像前面那样逐层添加层,可以在创建顺序模型时传递一个层列表
model=keras.models.Sequential([
keras.layers.Flatten(input_shape=[28,28]),
keras.layers.Dense(300,activation='relu'),
keras.layers.Dense(100,activation='relu'),
keras.layers.Dense(10,activation='softmax')
])
model.summary()#summary()方法显示模型的所有层
Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
flatten_1 (Flatten) (None, 784) 0
_________________________________________________________________
dense_3 (Dense) (None, 300) 235500
_________________________________________________________________
dense_4 (Dense) (None, 100) 30100
_________________________________________________________________
dense_5 (Dense) (None, 10) 1010
=================================================================
Total params: 266,610
Trainable params: 266,610
Non-trainable params: 0
_________________________________________________________________
model.layers#可以通过layers来获取模型的层列表,按其索引获取层,也可以按名称获取
[<tensorflow.python.keras.layers.core.Flatten at 0x1a8aa53b9d0>,
<tensorflow.python.keras.layers.core.Dense at 0x1a8aa53b340>,
<tensorflow.python.keras.layers.core.Dense at 0x1a8aa53b670>,
<tensorflow.python.keras.layers.core.Dense at 0x1a8aa533c40>]
hidden1=model.layers[1]
hidden1.name
'dense_3'
model.get_layer('dense_3') is hidden1
True
可以用get_weights()和set_weights()方法访问层的所有参数。对于密集层,这包括连接权重和偏置项
weights,biases=hidden1.get_weights()
weights
array([[-0.00048143, -0.02221986, -0.03760444, ..., -0.01870283,
0.02787271, -0.0562621 ],
[ 0.03667355, -0.02800197, -0.02043942, ..., -0.05027718,
0.04881267, -0.03488968],
[-0.01286711, 0.0676775 , 0.01634417, ..., 0.05434407,
-0.02889663, 0.06560428],
...,
[ 0.0035713 , 0.03277423, 0.01696016, ..., -0.06722524,
0.05769408, -0.05496902],
[ 0.04029207, 0.05693065, -0.03199599, ..., 0.02694139,
0.02356034, -0.01617898],
[-0.03333716, -0.03082271, 0.00634206, ..., 0.04961272,
-0.0399887 , 0.0423771 ]], dtype=float32)
weights.shape
(784, 300)
biases
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.], dtype=float32)
biases.shape
(300,)
编译模型
使用loss='sparse_categorical_crossentropy'等同于使用loss=keras.losses.sparse_categorical_crossentropy。同样,指定optimizer='sgd'等同于指定optimizer=keras.optimizers.SGD(),而metrics=['accuracy']等同于metrics=[keras.metrics.sparse_categorical_accuracy]
model.compile(loss='sparse_categorical_crossentropy',
optimizer='sgd',
metrics=['accuracy'])
如果要使用稀疏标签(即类索引)转换为独热向量标签,使用keras.utils.to_categorical()函数。反之则使用np.argmax函数和axis=1
现在模型已准备好进行训练,只需要调用fit方法
将输入特征(X_train)和目标类(y_train)以及要训练的轮次数传给它,否则默认为1.在这里还传递了一个验证集。Keras将在每轮次结束时测量此集合上的损失和其他指标,这对查看模型的实际效果非常有用
history=model.fit(X_train,y_train,epochs=30,validation_data=(X_valid,y_valid))
Epoch 1/30
1719/1719 [==============================] - 4s 2ms/step - loss: 0.7114 - accuracy: 0.7640 - val_loss: 0.5329 - val_accuracy: 0.8156
Epoch 2/30
1719/1719 [==============================] - 3s 2ms/step - loss: 0.4915 - accuracy: 0.8293 - val_loss: 0.4504 - val_accuracy: 0.8464
Epoch 3/30
1719/1719 [==============================] - 3s 1ms/step - loss: 0.4486 - accuracy: 0.8427 - val_loss: 0.4134 - val_accuracy: 0.8562
Epoch 4/30
1719/1719 [==============================] - 2s 1ms/step - loss: 0.4186 - accuracy: 0.8516 - val_loss: 0.4002 - val_accuracy: 0.8618
Epoch 5/30
1719/1719 [==============================] - 2s 1ms/step - loss: 0.3975 - accuracy: 0.8590 - val_loss: 0.3786 - val_accuracy: 0.8692
Epoch 6/30
1719/1719 [==============================] - 2s 1ms/step - loss: 0.3805 - accuracy: 0.8649 - val_loss: 0.3897 - val_accuracy: 0.8648
Epoch 7/30
1719/1719 [==============================] - 2s 1ms/step - loss: 0.3668 - accuracy: 0.8697 - val_loss: 0.3785 - val_accuracy: 0.8686
Epoch 8/30
1719/1719 [==============================] - 2s 1ms/step - loss: 0.3546 - accuracy: 0.8732 - val_loss: 0.3493 - val_accuracy: 0.8762
Epoch 9/30
1719/1719 [==============================] - 2s 1ms/step - loss: 0.3442 - accuracy: 0.8784 - val_loss: 0.3476 - val_accuracy: 0.8776
Epoch 10/30
1719/1719 [==============================] - 3s 2ms/step - loss: 0.3352 - accuracy: 0.8808 - val_loss: 0.3419 - val_accuracy: 0.8796
Epoch 11/30
1719/1719 [==============================] - 3s 1ms/step - loss: 0.3250 - accuracy: 0.8839 - val_loss: 0.3328 - val_accuracy: 0.8812
Epoch 12/30
1719/1719 [==============================] - 2s 1ms/step - loss: 0.3175 - accuracy: 0.8866 - val_loss: 0.3247 - val_accuracy: 0.8860
Epoch 13/30
1719/1719 [==============================] - 3s 1ms/step - loss: 0.3099 - accuracy: 0.8887 - val_loss: 0.3309 - val_accuracy: 0.8794
Epoch 14/30
1719/1719 [==============================] - 3s 1ms/step - loss: 0.3027 - accuracy: 0.8914 - val_loss: 0.3240 - val_accuracy: 0.8810
Epoch 15/30
1719/1719 [==============================] - 2s 1ms/step - loss: 0.2961 - accuracy: 0.8932 - val_loss: 0.3189 - val_accuracy: 0.8834
Epoch 16/30
1719/1719 [==============================] - 2s 1ms/step - loss: 0.2905 - accuracy: 0.8954 - val_loss: 0.3242 - val_accuracy: 0.8852
Epoch 17/30
1719/1719 [==============================] - 2s 1ms/step - loss: 0.2843 - accuracy: 0.8980 - val_loss: 0.3172 - val_accuracy: 0.8884
Epoch 18/30
1719/1719 [==============================] - 2s 1ms/step - loss: 0.2795 - accuracy: 0.8997 - val_loss: 0.3126 - val_accuracy: 0.8856
Epoch 19/30
1719/1719 [==============================] - 3s 1ms/step - loss: 0.2737 - accuracy: 0.9015 - val_loss: 0.3143 - val_accuracy: 0.8874
Epoch 20/30
1719/1719 [==============================] - 2s 1ms/step - loss: 0.2696 - accuracy: 0.9024 - val_loss: 0.3120 - val_accuracy: 0.8884
Epoch 21/30
1719/1719 [==============================] - 2s 1ms/step - loss: 0.2639 - accuracy: 0.9051 - val_loss: 0.3041 - val_accuracy: 0.8930
Epoch 22/30
1719/1719 [==============================] - 3s 1ms/step - loss: 0.2596 - accuracy: 0.9062 - val_loss: 0.3035 - val_accuracy: 0.8926
Epoch 23/30
1719/1719 [==============================] - 2s 1ms/step - loss: 0.2535 - accuracy: 0.9087 - val_loss: 0.2970 - val_accuracy: 0.8916
Epoch 24/30
1719/1719 [==============================] - 3s 1ms/step - loss: 0.2497 - accuracy: 0.9101 - val_loss: 0.3263 - val_accuracy: 0.8864
Epoch 25/30
1719/1719 [==============================] - 2s 1ms/step - loss: 0.2459 - accuracy: 0.9120 - val_loss: 0.2964 - val_accuracy: 0.8908
Epoch 26/30
1719/1719 [==============================] - 2s 1ms/step - loss: 0.2414 - accuracy: 0.9132 - val_loss: 0.2981 - val_accuracy: 0.8902
Epoch 27/30
1719/1719 [==============================] - 3s 1ms/step - loss: 0.2377 - accuracy: 0.9144 - val_loss: 0.3021 - val_accuracy: 0.8920
Epoch 28/30
1719/1719 [==============================] - 3s 1ms/step - loss: 0.2337 - accuracy: 0.9157 - val_loss: 0.3247 - val_accuracy: 0.8864
Epoch 29/30
1719/1719 [==============================] - 3s 1ms/step - loss: 0.2301 - accuracy: 0.9178 - val_loss: 0.3469 - val_accuracy: 0.8764
Epoch 30/30
1719/1719 [==============================] - 3s 1ms/step - loss: 0.2265 - accuracy: 0.9179 - val_loss: 0.2957 - val_accuracy: 0.8920
fit()方法返回一个History对象,其中包含训练参数(history.params)、经历的轮次列表(history.epoch),最重要的是包含在训练集和验证集上的每个轮
次结束时测得的损失和额外指标的字典(history.history)如果用此字典创建pandas DataFrame并调用plot()方法,可以绘制出学习曲线
import pandas as pd
import matplotlib.pyplot as plt
pd.DataFrame(history.history).plot(figsize=(8,5))
plt.grid(True)
plt.gca().set_ylim(0,1)
plt.show()
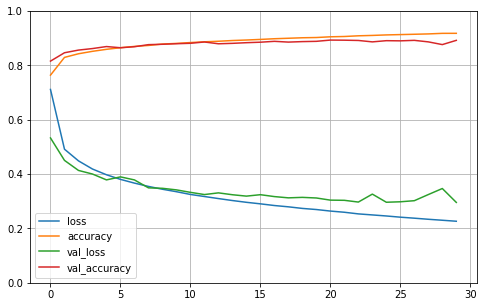
对模型的验证精度感到满意后,应在测试集上对其进行评估泛化误差。这时可以使用evaluate()方法完成此操作
model.evaluate(X_test,y_test)
313/313 [==============================] - 0s 1ms/step - loss: 63.2170 - accuracy: 0.8478
[63.216957092285156, 0.8478000164031982]
使用模型进行预测
X_new=X_test[:3]
y_proba=model.predict(X_new)
y_proba.round(2)
array([[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.],
[0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],
[0., 1., 0., 0., 0., 0., 0., 0., 0., 0.]], dtype=float32)
y_pred=model.predict_classes(X_new)
y_pred
C:\ProgramData\Miniconda3\lib\site-packages\tensorflow\python\keras\engine\sequential.py:455: UserWarning: `model.predict_classes()` is deprecated and will be removed after 2021-01-01. Please use instead:* `np.argmax(model.predict(x), axis=-1)`, if your model does multi-class classification (e.g. if it uses a `softmax` last-layer activation).* `(model.predict(x) > 0.5).astype("int32")`, if your model does binary classification (e.g. if it uses a `sigmoid` last-layer activation).
warnings.warn('`model.predict_classes()` is deprecated and '
array([9, 2, 1], dtype=int64)
y_pred==y_test[:3]
array([ True, True, True])
可见分类器对所有三个图像进行了正确分类

 浙公网安备 33010602011771号
浙公网安备 33010602011771号