MNIST手写数字集的多分类问题(Convolution Neural Network)
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn.functional as F
import torch.optim as optim
batch_size = 64
transform = transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])
train_dataset = datasets.MNIST(root='./dataset/mnist/',
train=True,
download=True,
transform=transform)
train_loader = DataLoader(dataset=train_dataset,
shuffle=True,
batch_size=batch_size)
test_dataset = datasets.MNIST(root='./dataset/mnist/',
train=False,
download=True,
transform=transform)
test_loader = DataLoader(dataset=test_dataset,
shuffle=False,
batch_size=batch_size)
class Net(torch.nn.Module): # 继承Module类
def __init__(self):
super(Net, self).__init__() # 继承父类
self.conv1 = torch.nn.Conv2d(1, 10, kernel_size=5) # 卷积层1,使用2维的卷积核,1通道->10通道,卷积核大小为5x5,
self.pooling = torch.nn.MaxPool2d(2) # 池化层,使用二维的最大池化层,图像大小的height和width都减半并向下取整
self.conv2 = torch.nn.Conv2d(10, 20, kernel_size=5) # 卷积层2, 10通道->20通道,卷积核大小为5x5,
# (batch_size,13,13,10)->(batch_size,11,11,20)
self.l1 = torch.nn.Linear(320, 256) # 全连接层
self.l2 = torch.nn.Linear(256, 128)
self.l3 = torch.nn.Linear(128, 64)
self.l4 = torch.nn.Linear(64, 10)
def forward(self, x):
batch_size = x.size(0)
x = F.gelu(self.pooling(self.conv1(
x))) # (batch_size,28,28,1)->(batch_size,26,26,10)->(batch_size,13,13,10) 因为没有做填充(padding)所以图像的大小减小了
x = F.gelu(self.pooling(self.conv2(x))) # (batch_size,13,13,10)->(batch_size,6,6,20)->(batch_size,4,4,20)
x = x.view(batch_size, -1) # (batch_size,4*4*20)将张量展平接入全连接层
x = F.gelu(self.l1(x))
x = F.gelu(self.l2(x))
x = F.gelu(self.l3(x))
x = self.l4(x)
return x # 通过带有激活函数的线性层获得输出
model = Net() # 实例化神经网络
device = torch.device('cuda:0' if torch.cuda.is_available() else 'CPU') # 如果能使用GPU,就将模型移植到GPU上用cuda核心进行并行计算
model.to(device)
criterion = torch.nn.CrossEntropyLoss().to(device)
optimizer = optim.Adam(model.parameters(), lr=0.01)
def train(epoch):
running_loss = 0
for batch_idx, data in enumerate(train_loader):
inputs, target = data
inputs, target = inputs.to(device), target.to(device)
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, target)
loss.backward()
optimizer.step()
running_loss += loss
if batch_idx % 300 == 299:
print('[%d,%5d] loss:%.3f' % (epoch + 1, batch_idx + 1, running_loss / 300))
running_loss = 0
def test():
corrent = 0
total = 0
with torch.no_grad():
for data in test_loader:
images, labels = data
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, prediction = torch.max(outputs, dim=1)
total += labels.size(0)
corrent += (prediction == labels).sum().item()
print('Accuracy on test set %.2f %%' % (100 * corrent / total))
if __name__ == '__main__':
for epoch in range(10):
train(epoch)
test()
运行结果: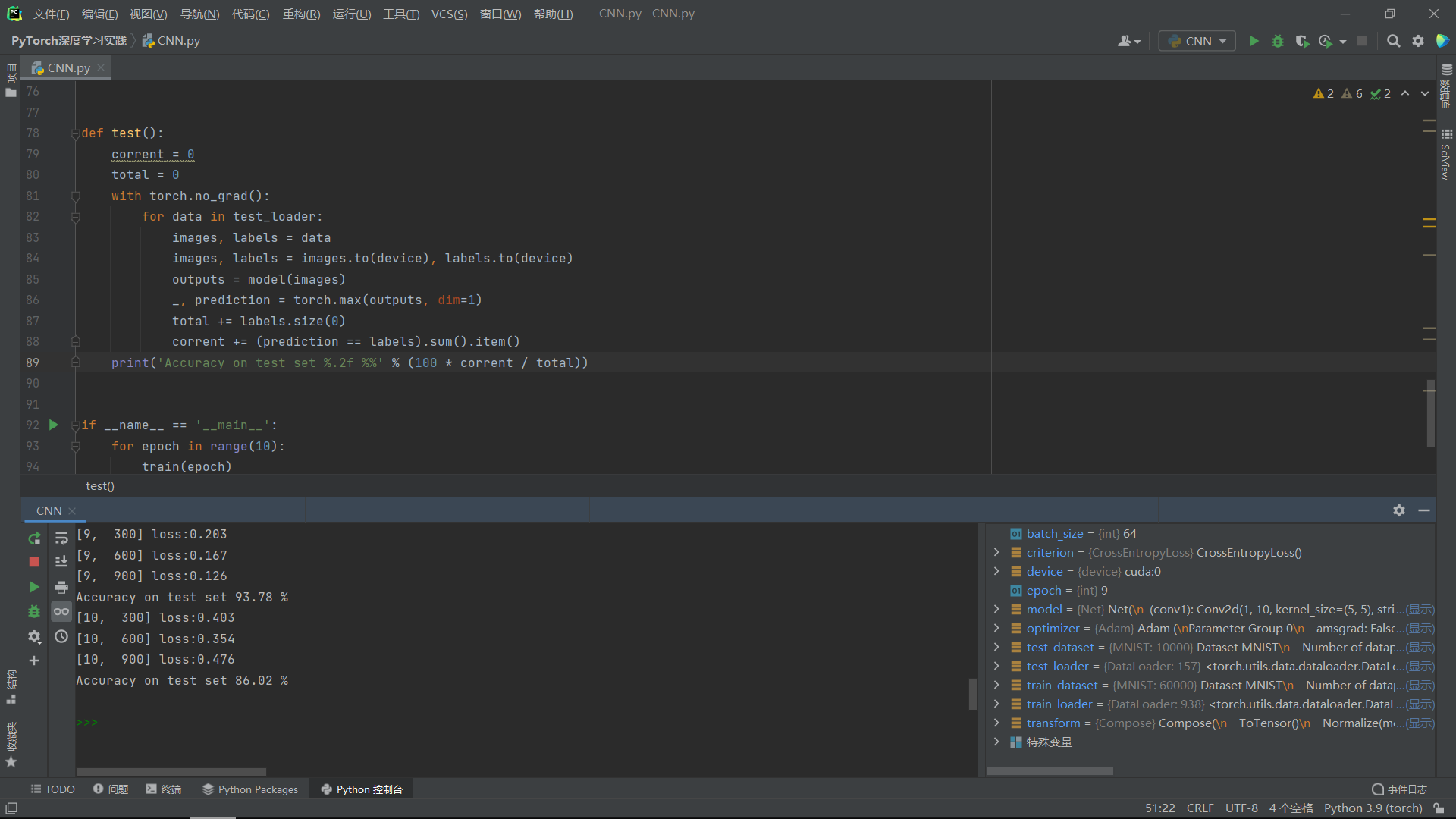

 浙公网安备 33010602011771号
浙公网安备 33010602011771号