STM32 搭建CUBE.AI的demo工程
STM32 搭建CUBE.AI的demo工程
ST公司在自家的CubeMX中加入了Cube.AI人工智能神经网络开发工具包,这次来试试如何在自己的这个资源紧张的小开发板上使用下神经网络吧😂
我在这里用cube.ai的主要目的是得到工具包文件,以便后续迁移其他环境时使用。
准备工作
更新CubeMX
更新CubeMX并安装Cube.AI工具包,位置在这:
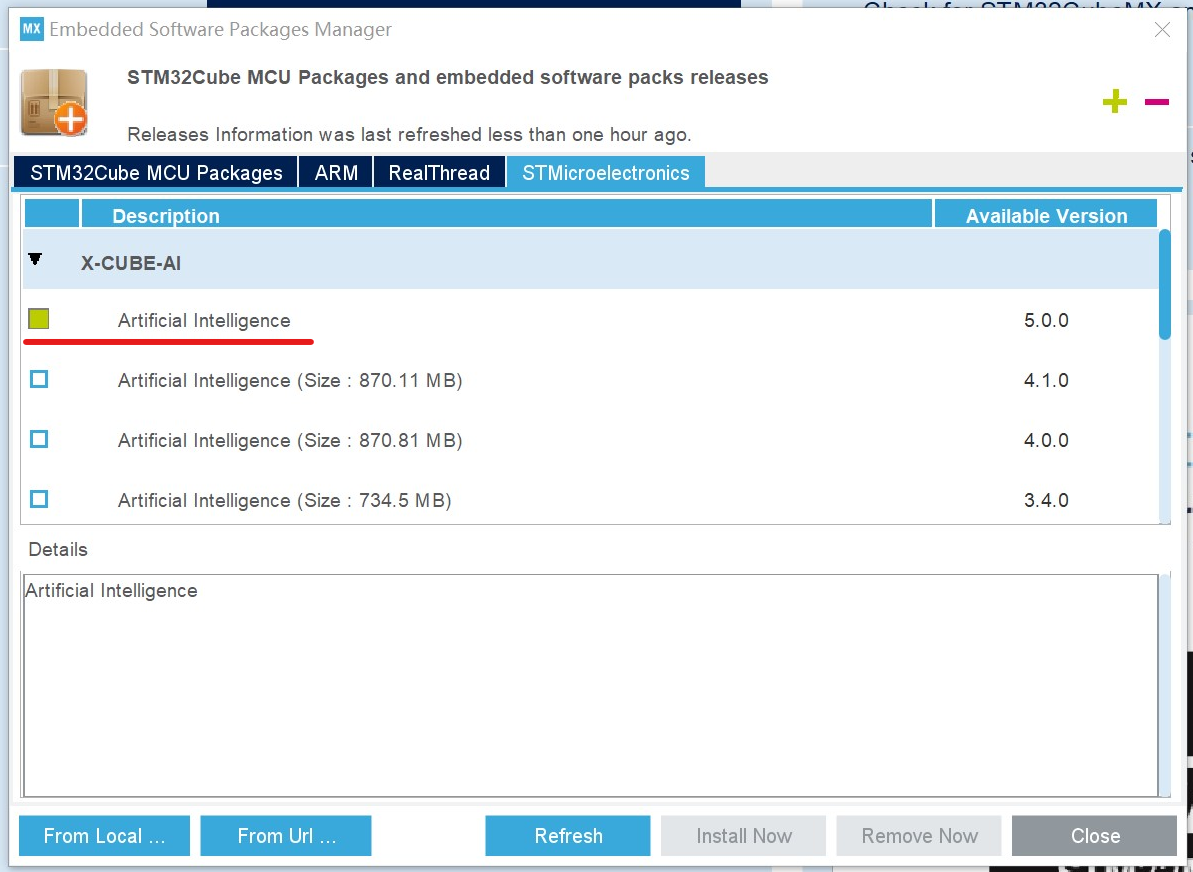
装好后重启软件。
准备模型
向工程中添加cube.ai
创建工程
打开或者创建一个STM32的工程,添加AI模型:
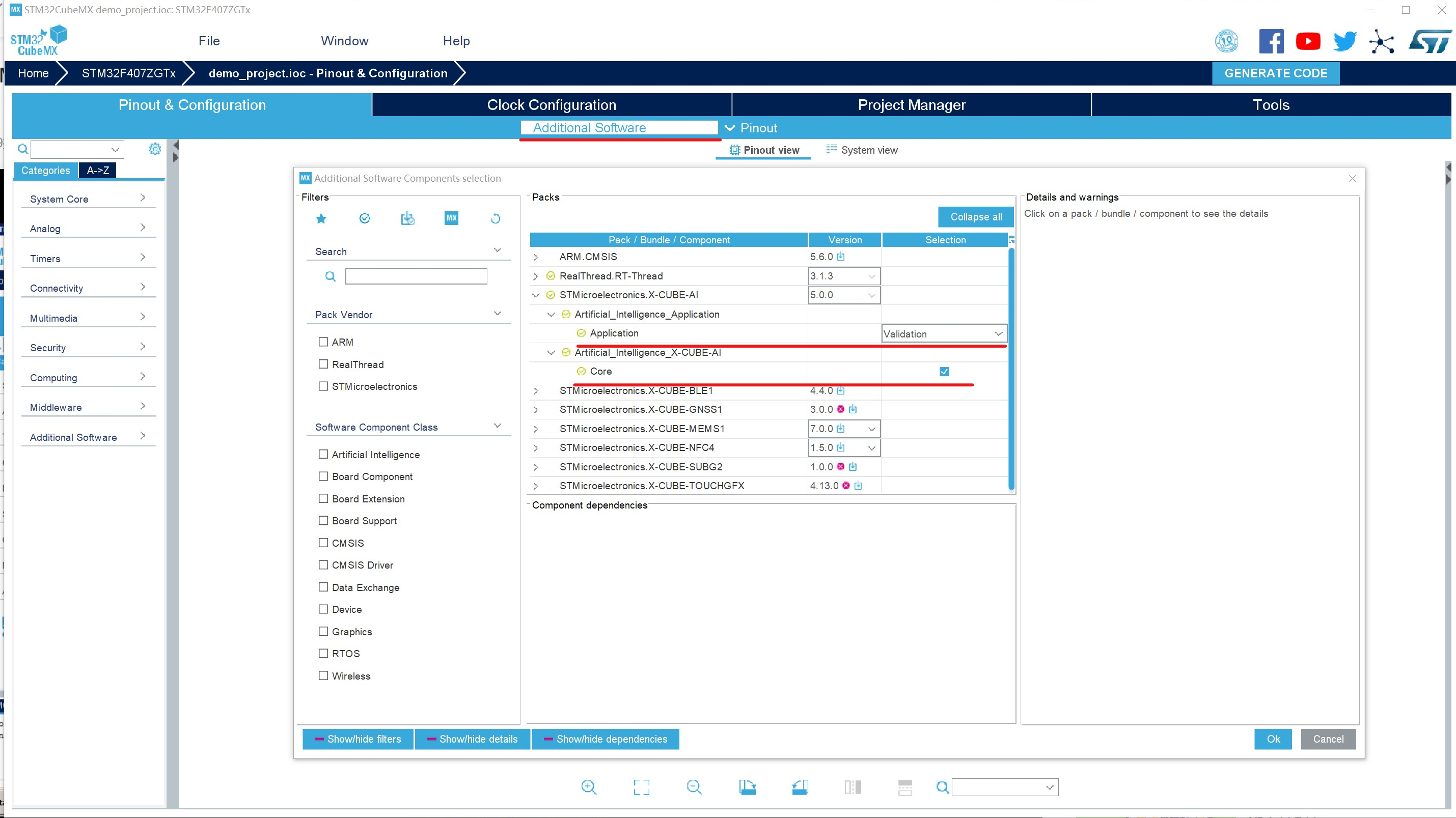
validation是验证集,这里我们把core和application都加上,application这里可以选择system performance、validation还是application template,如果是application template的话,只有一些模型的api,需要什么样的模型这里自己写。
调整参数
进到下面的这个页面:
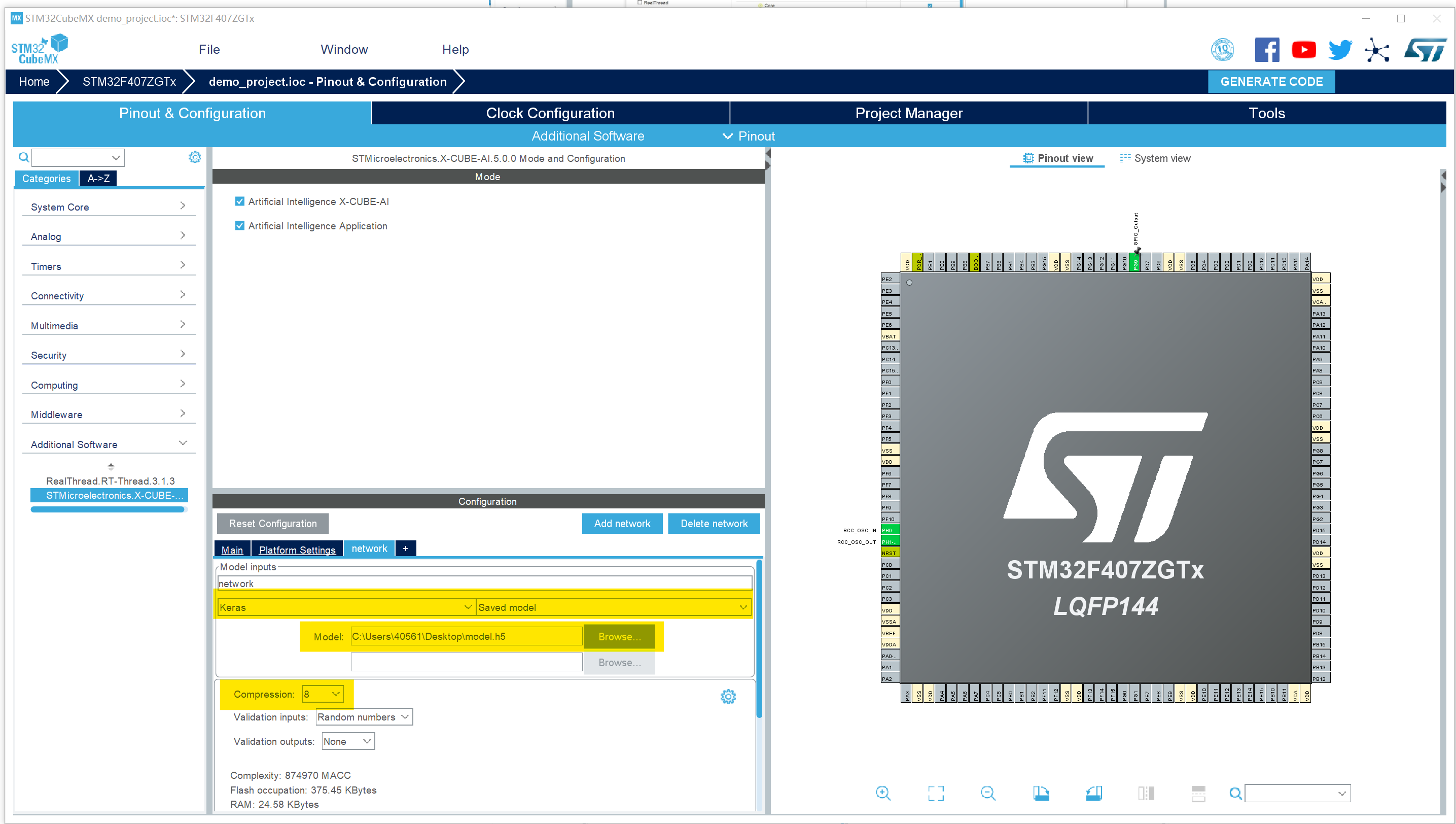
导入模型,推荐用h5格式,注意片内flash的大小,选择压缩倍数(4or8),可以点击Validate on desktop进行验证,下方Output选项卡中会输出Validation OK,还有一些验证的细节。验证后退到下面这张图,记下需要的ram和flash大小。
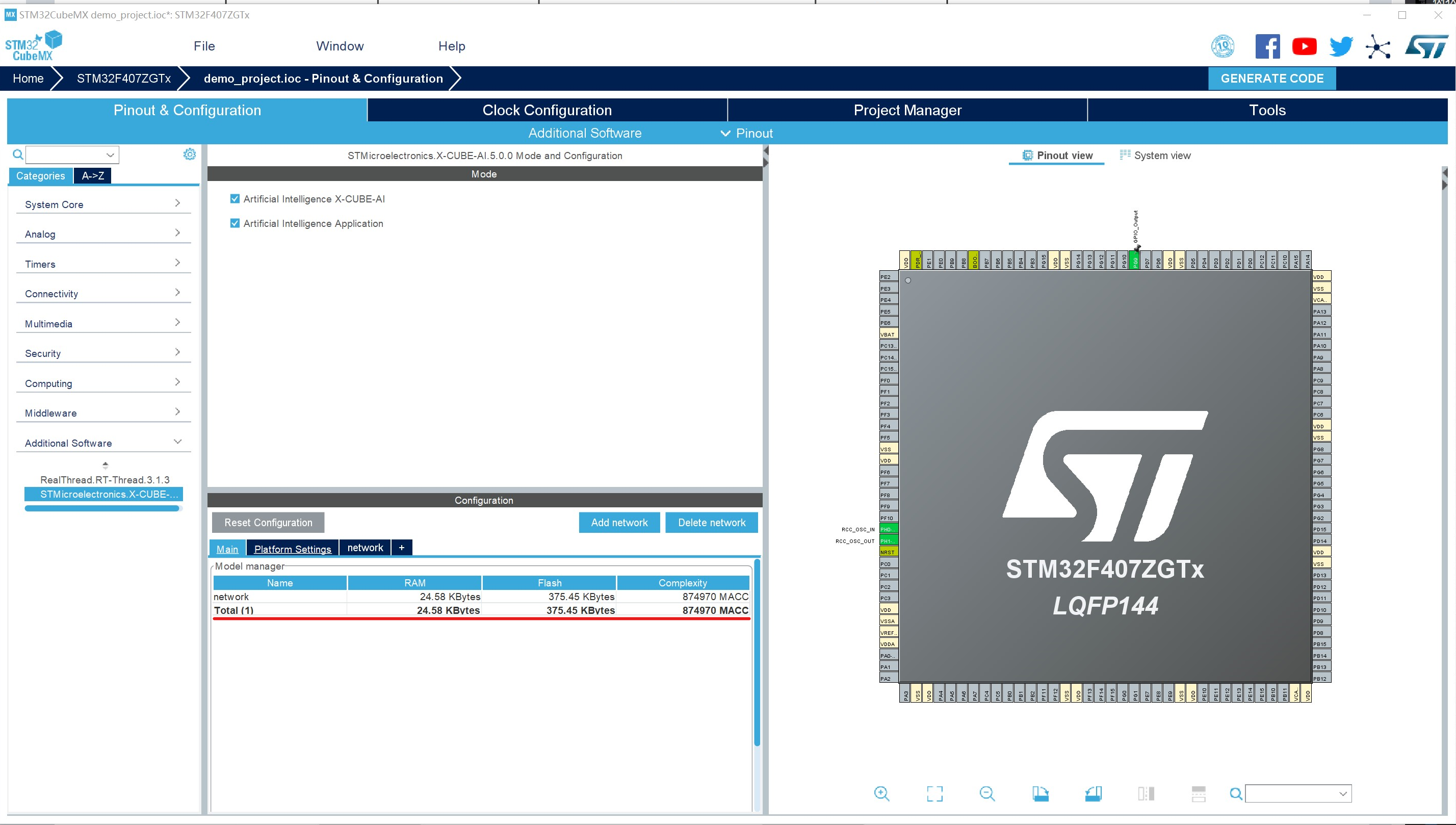
这里的ram需要堆空间,因此我们还需要调整堆空间的大小,官网demo要求是0x2000,嗯裸机程序堆大点也没啥问题,后面的就是直接generate就可以了,我们来看工程,这里为了方便演示,生成的是MDK工程。注意这里需要把UART1的pin脚使能,同时打开UART1的中断,然后在platform settings这里选中,否则编译会出错
其他问题
直接生成的工程,在进行运行的时候printf语句会卡死,查了下网络,大概率是因为HAL库的坑,移植到老代码又有很多HAL库兼容性的问题,暂时放弃了
小结
将AI和嵌入式结合在一起,尤其是直接在边缘设备实现AI功能是现在算法落地的一个重点,有很多解决方案和工具可供选择,从这次的cube ai的效果来看,ST公司在这方面布局很快,但是受cubemx的因素,实用性不高。这里其实是cube ai依托cube mx来实现,稍微简化了软件开发的难度,而cube mx的更新太快,HAL库版本缺陷等等,增加了更多的稳定性缺陷,得不偿失,如果前期提供一个稳定可靠的库文件或者转化小工具,则可以快速推广,积攒口碑。毕竟很多厂商会担心由于新增的AI功能对已有产品的影响,从而影响芯片公司推广。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号