
milvus介绍
1.什么是milvus
Milvus是在2019年创建的,其唯一目标是存储、索引和管理由深度神经网络和其他机器学习(ML)模型生成的大规模嵌入向量。
非结构化数据包括电子邮件、论文、物联网传感器数据、Facebook照片、蛋白质结构等等。为了使计算机能够理解和处理非结构化数据,使用嵌入技术将它们转换为向量。Milvus存储和索引这些向量。Milvus能够通过计算它们的相似距离来分析两个向量之间的相关性。如果两个嵌入向量非常相似,则意味着原始数据源也很相似。
2.Milvus的设计原理
https://www.milvus-io.com/architecture_overview
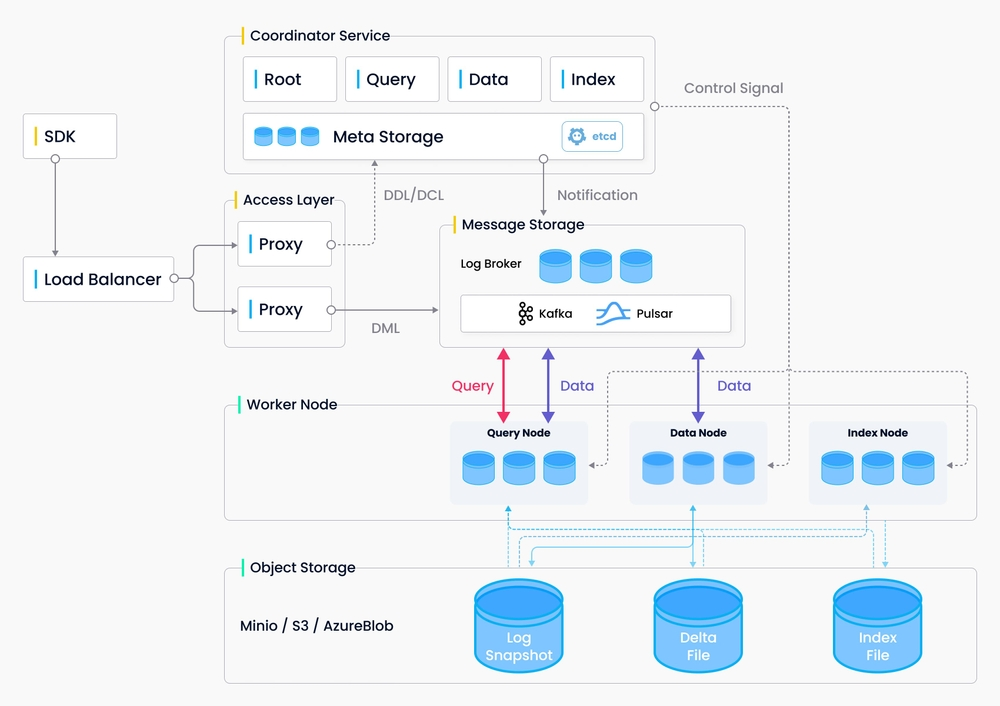
3.应用场景
Milvus使得向应用中添加相似性搜索变得容易。Milvus的示例应用包括:
图像相似性搜索:使图像可搜索,并即时返回来自大型数据库中最相似的图像。
视频相似性搜索:通过将关键帧转换为向量,然后将结果输入Milvus,可以在几乎实时的时间内搜索和推荐数十亿个视频。
音频相似性搜索:快速查询大量音频数据,如语音、音乐、音效和表面相似的声音。
分子相似性搜索:针对指定分子进行极快的相似性搜索、子结构搜索或超结构搜索。
推荐系统:根据用户行为和需求推荐信息或产品。
问答系统:交互式数字问答聊天机器人,自动回答用户的问题。
DNA序列分类:通过比较相似的DNA序列,在毫秒级别准确地分类一个基因。
文本搜索引擎:通过将关键字与文本数据库进行比较,帮助用户找到他们正在寻找的信息
4.index类型
FLAT:FLAT最适合于在小规模,百万级数据集上寻求完全准确和精确的搜索结果的场景。
IVF_FLAT:IVF_FLAT是一种量化索引,最适合于在精度和查询速度之间寻求理想平衡的场景。
IVF_SQ8:IVF_SQ8是一种量化索引,最适合于在磁盘、CPU和GPU内存消耗非常有限的场景中显著减少资源消耗。如果要求95%以上召回精度则不建议选择
IVF_PQ:IVF_PQ是一种量化索引,最适合于在高查询速度的情况下以牺牲精度为代价的场景。
HNSW:HNSW是一种基于图形的索引,最适合于对搜索效率有很高需求的场景。
ANNOY:ANNOY是一种基于树形结构的索引,最适合于寻求高召回率的场景


 浙公网安备 33010602011771号
浙公网安备 33010602011771号