
爬取百度热搜榜
一、主题式网络爬虫设计方案
1.主题式网络爬虫名称:爬取百度热搜榜
2.主题式网络爬虫爬取的的内容:爬取百度热搜前十
3.主题式网络爬虫设计方案概述:
实现思路:通过分析网页源代码,找出数据所在的标签,通过爬虫读取数据保存到csv文件中,读取文件,对数据进行清洗和处理,然后在进行分析与可视化并建立回归方程。
技术难点:知识掌握不充分,对网页爬取还有很多不懂。
二、主题页面的结构特征分析
1.主题页面的结构与特征分析:从网络源代码可以看出,我们所需要的字段全部在id=“hot-list”这个ul标签下的所有li标签中。所以要在整个HTML页面中,首先找到ul标签,获取所需要的热搜榜信息,然后在ul标签中解析所有的li标签,获取所需要的关键词和搜索指数信息。
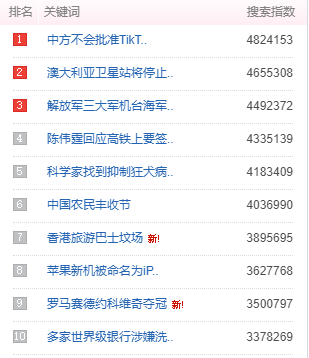

3.节点(标签)查找方法与遍历方法:进入百度热搜页面点击F12打开网络源代码,查询需要的标签属性关键字,可以看到所需要的字段所在的标签位置。用request.get(url)命令向服务器提交请求,然后将响应的网页信息交由BeautifulSoup库解析。提取HTML结构和源代码,最后用soup.prettify()方法输出源码。
三、网络爬虫程序设计
1.数据爬取与采集
import requests from bs4 import BeautifulSoup url='http://top.baidu.com/'#选择要爬取的网站 def getHTMLText(url): try: r=requests.get(url)#获得url信息 r.raise_for_status()#失败请求(非200响应)抛出异常 r.encoding = r.apparent_encoding#根据内容分析出的编码方式,备选编码; return r.text except: return"" def get_data(html): #创建空列表 top=[] keyword=[] hot=[] soup=BeautifulSoup(html,"html.parser")#使用BeautifulSoup解析文本 for x in soup.find_all(class_="num-top"): top.append(x.get_text().strip()) for y in soup.find_all(class_="list-title"): keyword.append(y.get_text().strip()) for z in soup.find_all(class_="icon-rise"): hot.append(z.get_text().strip()) final_list=[top,keyword,hot]#把列表放入变量final_list中 return final_list def main(): url='http://top.baidu.com/' html=getHTMLText(url) final_list=get_data(html) return final_list import pandas as pd df=pd.DataFrame(main(),index=["排名","关键词","搜索指数"])#数据可视化 print(df.T) filename=("百度热搜榜.csv") df.to_csv(filename)
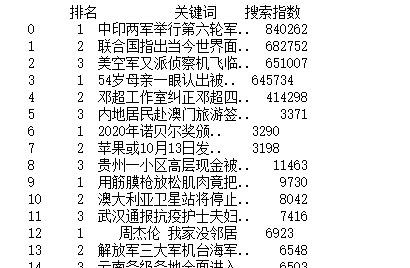
2.对数据进行清洗和处理
df.duplicated()#查找重复值
df.drop_duplicates()#删除重复值
df.isnull()#统计空值
df.describe()#描述数据



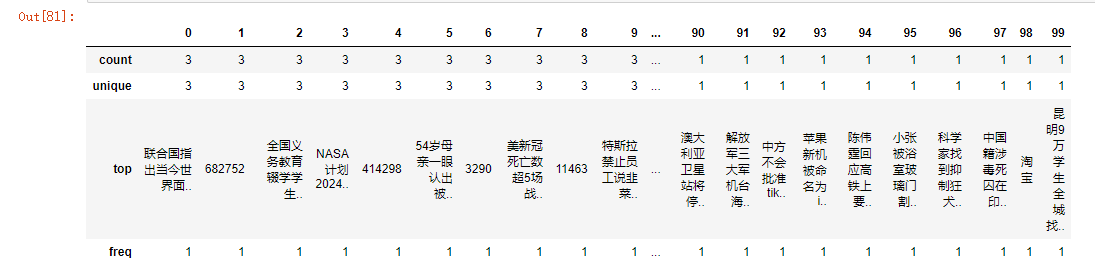
4.数据分析与可视化
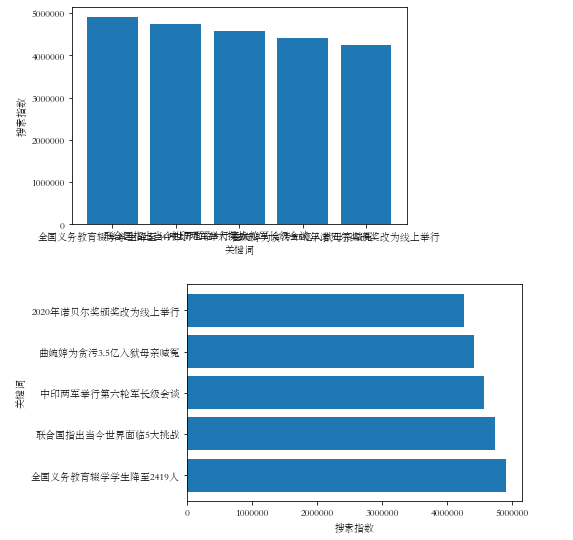
#垂直柱形图 import numpy as np import matplotlib.pyplot as plt plt.rcParams['font.sans-serif']=['STSong']#用来正常显示中文标签 plt.figure() plt.bar(['全国义务教育辍学学生降至2419人','联合国指出当今世界面临5大挑战','中印两军举行第六轮军长级会谈','曲婉婷为贪污3.5亿入狱母亲喊冤','2020年诺贝尔奖颁奖改为线上举行'],[4903555,4731930,4566313,4406492, 4252264]) plt.xlabel("关键词") plt.ylabel("搜索指数") plt.show() #水平柱形图 plt.barh(['全国义务教育辍学学生降至2419人','联合国指出当今世界面临5大挑战','中印两军举行第六轮军长级会谈','曲婉婷为贪污3.5亿入狱母亲喊冤','2020年诺贝尔奖颁奖改为线上举行'],[4903555,4731930,4566313,4406492, 4252264]) plt.xlabel("搜索指数") plt.ylabel("关键词") plt.show()
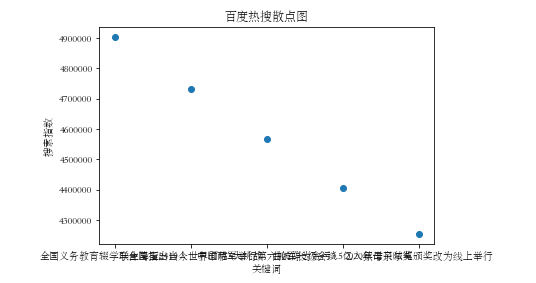
#散点图 plt.scatter(['全国义务教育辍学学生降至2419人','联合国指出当今世界面临5大挑战','中印两军举行第六轮军长级会谈','曲婉婷为贪污3.5亿入狱母亲喊冤','2020年诺贝尔奖颁奖改为线上举行'],[4903555,4731930,4566313,4406492, 4252264]) plt.xlabel("关键词") plt.ylabel("搜索指数") plt.title("百度热搜散点图") plt.show()
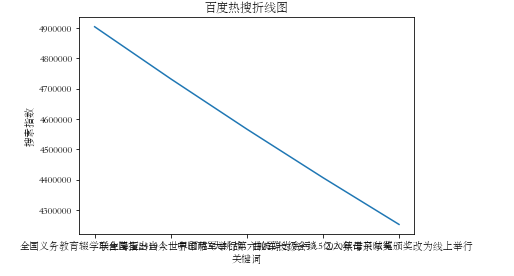
#折线图 plt.plot(['全国义务教育辍学学生降至2419人','联合国指出当今世界面临5大挑战','中印两军举行第六轮军长级会谈','曲婉婷为贪污3.5亿入狱母亲喊冤','2020年诺贝尔奖颁奖改为线上举行'],[4903555,4731930,4566313,4406492, 4252264]) plt.xlabel("关键词") plt.ylabel("搜索指数") plt.title("百度热搜折线图") plt.show()
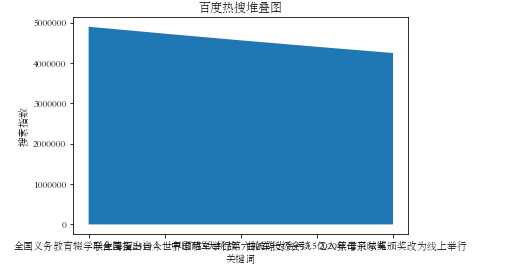
#堆叠图图 plt.stackplot(['全国义务教育辍学学生降至2419人','联合国指出当今世界面临5大挑战','中印两军举行第六轮军长级会谈','曲婉婷为贪污3.5亿入狱母亲喊冤','2020年诺贝尔奖颁奖改为线上举行'],[4903555,4731930,4566313,4406492, 4252264]) plt.xlabel("关键词") plt.ylabel("搜索指数") plt.title("百度热搜堆叠图") plt.show()
#盒图 import seaborn as sns sns.boxplot(['全国义务教育辍学学生降至2419人','联合国指出当今世界面临5大挑战','中印两军举行第六轮军长级会谈','曲婉婷为贪污3.5亿入狱母亲喊冤','2020年诺贝尔奖颁奖改为线上举行'],[4903555,4731930,4566313,4406492, 4252264])

5.根据数据之间的关系,分析两个变量之间的相关系数,画出散点图,并建立变量之间的回归方程(一元或多元)
import scipy as sp import matplotlib from scipy.optimize import leastsq from numpy import genfromtxt colnames=["关键词","搜索指数"] X=np.array(keyword) Y=np.array(hot) def fit_func(p,x): k,b=p return k*x+b def error_func(p,x,y): return fit_func(p,x)-y def main(): plt.figure(figsize=(10,6))#指定图像比例 p0=[0,0] Para=leastsq(error_func,p0,args=(X,Y))#读取leastsq返回值结果 k,b=Para[0] print("k=",k,"b=",b) plt.scatter(X,Y,color="green",label="样本数据",linewidth=2) #画拟合曲线 x=np.linspace(43000,49000,5) y=k*x+b plt.plot(x,y,color="red",label="拟合曲线",linewidth=2) plt.title("百度热搜榜") plt.grid() plt.legend() plt.show()
6.数据持久化
import csv with open("百度热搜榜.csv","r") as csvfile: read=csv.reader(csvfile) for i in read: print(i) with open("百度热搜榜.csv","w") as csvfile: write=csv.writer(csvfile) write.writerow(data) write.writerows(data)
7.将以上各部分的代码汇总,附上完整程序代码
import requests from bs4 import BeautifulSoup url='http://top.baidu.com/'#选择要爬取的网站 def getHTMLText(url): try: r=requests.get(url)#获得url信息 r.raise_for_status()#失败请求(非200响应)抛出异常 r.encoding = r.apparent_encoding#根据内容分析出的编码方式,备选编码; return r.text except: return"" def get_data(html): #创建空列表 keyword=[] hot=[] soup=BeautifulSoup(html,"html.parser")#使用BeautifulSoup解析文本 for x in soup.find_all(class_="list-title"): keyword.append(x.get_text().strip()) for y in soup.find_all(class_="icon-rise"): hot.append(y.get_text().strip()) final_list=[keyword,hot]#把列表放入变量final_list中 return final_list def main(): url='http://top.baidu.com/' html=getHTMLText(url) final_list=get_data(html) return final_list import pandas as pd df=pd.DataFrame(main(),index=["关键词","搜索指数"])#数据可视化 print(df.T) df.to_csv("百度热搜榜.csv",encoding="utf_8") df.duplicated()#查找重复值 df.drop_duplicates()#删除重复值 df.isnull()#统计空值 df.describe()#描述数据 #垂直柱形图 import numpy as np import matplotlib.pyplot as plt plt.rcParams['font.sans-serif']=['STSong']#用来正常显示中文标签 plt.figure() plt.bar(['全国义务教育辍学学生降至2419人','联合国指出当今世界面临5大挑战','中印两军举行第六轮军长级会谈','曲婉婷为贪污3.5亿入狱母亲喊冤','2020年诺贝尔奖颁奖改为线上举行'],[4903555,4731930,4566313,4406492, 4252264]) plt.xlabel("关键词") plt.ylabel("搜索指数") plt.title("百度热搜垂直柱形图") plt.show() #水平柱形图 plt.barh(['全国义务教育辍学学生降至2419人','联合国指出当今世界面临5大挑战','中印两军举行第六轮军长级会谈','曲婉婷为贪污3.5亿入狱母亲喊冤','2020年诺贝尔奖颁奖改为线上举行'],[4903555,4731930,4566313,4406492, 4252264]) plt.xlabel("搜索指数") plt.ylabel("关键词") plt.title("百度热搜水平柱形图") plt.show() #散点图 plt.scatter(['全国义务教育辍学学生降至2419人','联合国指出当今世界面临5大挑战','中印两军举行第六轮军长级会谈','曲婉婷为贪污3.5亿入狱母亲喊冤','2020年诺贝尔奖颁奖改为线上举行'],[4903555,4731930,4566313,4406492, 4252264]) plt.xlabel("关键词") plt.ylabel("搜索指数") plt.title("百度热搜散点图") plt.show() #折线图 plt.plot(['全国义务教育辍学学生降至2419人','联合国指出当今世界面临5大挑战','中印两军举行第六轮军长级会谈','曲婉婷为贪污3.5亿入狱母亲喊冤','2020年诺贝尔奖颁奖改为线上举行'],[4903555,4731930,4566313,4406492, 4252264]) plt.xlabel("关键词") plt.ylabel("搜索指数") plt.title("百度热搜折线图") plt.show() #堆叠图图 plt.stackplot(['全国义务教育辍学学生降至2419人','联合国指出当今世界面临5大挑战','中印两军举行第六轮军长级会谈','曲婉婷为贪污3.5亿入狱母亲喊冤','2020年诺贝尔奖颁奖改为线上举行'],[4903555,4731930,4566313,4406492, 4252264]) plt.xlabel("关键词") plt.ylabel("搜索指数") plt.title("百度热搜堆叠图") plt.show() import seaborn as sns sns.boxplot(['全国义务教育辍学学生降至2419人','联合国指出当今世界面临5大挑战','中印两军举行第六轮军长级会谈','曲婉婷为贪污3.5亿入狱母亲喊冤','2020年诺贝尔奖颁奖改为线上举行'],[4903555,4731930,4566313,4406492, 4252264]) import scipy as sp import matplotlib from scipy.optimize import leastsq from numpy import genfromtxt colnames=["关键词","搜索指数"] X=np.array(keyword) Y=np.array(hot) def fit_func(p,x): k,b=p return k*x+b def error_func(p,x,y): return fit_func(p,x)-y def main(): plt.figure(figsize=(10,6))#指定图像比例 p0=[0,0] Para=leastsq(error_func,p0,args=(X,Y))#读取leastsq返回值结果 k,b=Para[0] print("k=",k,"b=",b) plt.scatter(X,Y,color="green",label="样本数据",linewidth=2) #画拟合曲线 x=np.linspace(43000,49000,5) y=k*x+b plt.plot(x,y,color="red",label="拟合曲线",linewidth=2) plt.title("百度热搜榜") plt.grid() plt.legend() plt.show() import csv with open("百度热搜榜.csv","r") as csvfile: read=csv.reader(csvfile) for i in read: print(i) with open("百度热搜榜.csv","w") as csvfile: write=csv.writer(csvfile) write.writerow(data) write.writerows(data)
四、结论
1.经过对主题数据的分析与可视化,可以得到哪些结论?
经过对数据的分析与可视化,我们可以清晰的了解数据之间的相关关系,这有助于解决大部分人工计算绘图的问题。
2.对本次程序设计任务完成的情况做一个简单的小结
通过这次任务,我学会了数据的分析与可视化,并掌握了不少库的使用,过程中也参考了不少百度资料,这也加深了我对学习python的兴趣。
