
ALBEF-图文对比学习
《Align before Fuse: Vision and Language Representation Learning with Momentum Distillation》
引言
VLP目标是从大规模图片-文本对子中学习到多模态表示,一次改进下游的视觉-语言任务。
VLP框架的局限性如下:
- 图片特征和文字token嵌入在它们各自的空间内,使得多模态encoder难以去学习它们之间的关系。
- 目标decoder既需要大量标注也需要大量的计算资源,因为其在预训练时候需要边界框的标注和高分辨率的图片(600x1000)。
- 许多图片-文本数据集来自于网络,通常包含噪声,导致如MLM等模型可能会拟合噪声文本,降低模型的泛化能力。
作者提出了一种新的VLP框架ALBEF,以此解决以上问题:
1. 跨模态注意力:
作者首先使用detector-free的图片encoder(不需要检查特征点,直接匹配)和文本encoder对图片和文本编码。
然后使用多模态编码器通过跨模态注意力去融合图片特征和文本特征。
2. 作者提出了图片-文本对比(ITC)损失:
对齐图片特征和文本特征,使得其更容易用于多模态编码器执行跨模态学习。
帮助单模态编码器更好的理解图片和文本的语义
学习一个低维空间去嵌入图片和文本,可以使得图片-文本匹配目标挖掘更多有信息的样本。
3. 为了在噪声监督下学习,作者还提出了动量蒸馏(MoD):
在训练期间,通过获取模型的参数的移动平均值,保持模型的一个动量版本。然后使用动量模型生成伪目标作为额外的监督。
MoD模型不会因为产生与网络注释不同的输出而受到惩罚。
MoD不仅改进了预训练,也对下游任务的标注进行清洗。
方法
图-文对比学习损失ITC
首先,图片编码器和文本编码器都会在图片序列和文本序列的首部加上[CLS]标签,表示学习到的图片全局表示。
之后的对比就是基于[CLS]向量的对比。
图片和文本的[CLS]分别用vcls和wcls表示,动量编码器的输出特征分别使用g'w(w'cls)和g'v(v'cls)表示
对比学习,是学习与动量编码器输出的相似度。
s(I,T)=gv(vcls)T g'w(w'cls)
s(T,I)= gw(wcls)Tg'v(v'cls)
对于每个图片和文本,计算归一化的图片对文本的相似度和文本对图片的相似度。

τ是温度超参数。Tm是动量编码器输出的所有图片的[CLS],Im是动量编码器输出的所有文本[CLS]。
图文对比学习损失ITC如下:
![]()
其中H为交叉熵损失,y为Ground Truth标签。(在实际预训练中,代码中y采用的是伪标签)
已知交叉熵损失

代入ITC损失,得到

其中预测概率p为

其中s(I,T)是当前Image与一个Text的相似度。最终需要计算当前Image与所有Text的相似度,所以在源码中,是直接计算I与Text队列中所有的Text的相似度。s(T,I)也是如此。
文本对图片的相似度矩阵sim_t2i如下,图片对文本的相似度矩阵也类似。

代入到ITC损失中得到源代码中的计算公式(对应源代码中不蒸馏部分)

#源码中,映射图片和文本的全连接层输出embedding_dim为256
#一批输入中,有N个图片和N个句子
#图片和文本队列大小都为57600,维度为256,也就是是可以保存57600个维度为256的[CLS]
#为了存储方便,队列形状设置为256 x 57600
image_embeds = self.visual_encoder(image)
image_atts = torch.ones(image_embeds.size()[:-1],dtype=torch.long).to(image.device)
image_feat = F.normalize(self.vision_proj(image_embeds[:,0,:]),dim=-1)
#image_feat形状为:(N,256)
text_output = self.text_encoder(text.input_ids, attention_mask = text.attention_mask,return_dict = True, mode = 'text')
text_embeds = text_output.last_hidden_state
text_feat = F.normalize(self.text_proj(text_embeds[:,0,:]),dim=-1)
#text_feat形状为:(N,256)
idx = idx.view(-1,1)
#idx为图片-文本对的标签,分为一致2,中性1,对立0。
#原本形状为(N,),现在变为(N,1)
#idx转置成形状(1,N),idx_queue形状为(1,57600)
#然后将idx拼接到队列的头部得到idx_all,形状为(1,N+57600)
idx_all = torch.cat([idx.t(), self.idx_queue.clone().detach()],dim=1)
pos_idx = torch.eq(idx, idx_all).float()
#idx形状为(N,1),idx_all形状为(1,N+57600)
#比较之后,比较矩阵为(N,N+57600),表示N个标签分别与N+57600个的比较结果。
#由于队列的头部是新添加的标签,新标签与其比较时,自然而然对角线为1。
sim_targets = pos_idx / pos_idx.sum(1,keepdim=True) #硬标签
with torch.no_grad():
self._momentum_update()#更新动量编码器
image_embeds_m = self.visual_encoder_m(image)
image_feat_m = F.normalize(self.vision_proj_m(image_embeds_m[:,0,:]),dim=-1)
image_feat_all = torch.cat([image_feat_m.t(),self.image_queue.clone().detach()],dim=1)
#image_feat_m转置后形状为:256 x 2 , Image队列的形状为256 x 57600
#上述拼接操作是将队列复制一份,并将image_feat_m拼接到队列的头部!。
text_output_m = self.text_encoder_m(text.input_ids, attention_mask = text.attention_mask,return_dict = True, mode = 'text')
text_feat_m = F.normalize(self.text_proj_m(text_output_m.last_hidden_state[:,0,:]),dim=-1)
text_feat_all = torch.cat([text_feat_m.t(),self.text_queue.clone().detach()],dim=1)
#文本也一致
#text_feat_all和image_feat_all分别为text队列和image队列中所有的[CLS]集合
#计算图文特征分别对队列中所有特征的相似度
sim_i2t = image_feat @ text_feat_all / self.temp
sim_t2i = text_feat @ image_feat_all / self.temp
loss_i2t = -torch.sum(F.log_softmax(sim_i2t, dim=1)*sim_targets,dim=1).mean()#计算与硬标签的交叉熵损失
loss_t2i = -torch.sum(F.log_softmax(sim_t2i, dim=1)*sim_targets,dim=1).mean()
loss_ita = (loss_i2t+loss_t2i)/2
self._dequeue_and_enqueue(image_feat_m, text_feat_m, idx)动量蒸馏图文对比损失
带蒸馏则需要动量编码器输出的新样本与队列中所有样本的相似度q,然后将相似度q和硬标签组合成软标签。


然后最小化q和p之间的KL散度

代入原始式子
![]()
最小化KL散度的等价关系如下
![]()
最小化原式子等价于

得到如下公式(对应于源代码中的式子):
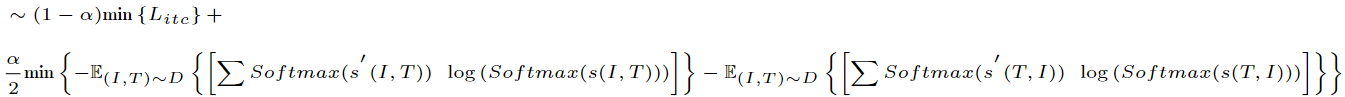
将Litc代入,得到:

最后一个公式就是对应于源码中的计算方式
源代码如下:
#源码中,映射图片和文本的全连接层输出embedding_dim为256
#一批输入中,有N个图片和N个句子
#图片和文本队列大小都为57600,维度为256,也就是是可以保存57600个维度为256的[CLS]
#为了存储方便,队列形状设置为256 x 57600
image_embeds = self.visual_encoder(image)
image_atts = torch.ones(image_embeds.size()[:-1],dtype=torch.long).to(image.device)
image_feat = F.normalize(self.vision_proj(image_embeds[:,0,:]),dim=-1)
#image_feat形状为:(N,256)
text_output = self.text_encoder(text.input_ids, attention_mask = text.attention_mask,return_dict = True, mode = 'text')
text_embeds = text_output.last_hidden_state
text_feat = F.normalize(self.text_proj(text_embeds[:,0,:]),dim=-1)
#text_feat形状为:(N,256)
idx = idx.view(-1,1)
#idx为图片-文本对的标签,分为一致2,中性1,对立0。
#原本形状为(N,),现在变为(N,1)
#idx转置成形状(1,N),idx_queue形状为(1,57600)
#然后将idx拼接到队列的头部得到idx_all,形状为(1,N+57600)
idx_all = torch.cat([idx.t(), self.idx_queue.clone().detach()],dim=1)
pos_idx = torch.eq(idx, idx_all).float()
#idx形状为(N,1),idx_all形状为(1,N+57600)
#比较之后,比较矩阵为(N,N+57600),表示N个标签分别与N+57600个的比较结果。
#由于队列的头部是新添加的标签,新标签与其比较时,自然而然对角线为1。
sim_targets = pos_idx / pos_idx.sum(1,keepdim=True)
with torch.no_grad():
self._momentum_update()#更新动量编码器
image_embeds_m = self.visual_encoder_m(image)
image_feat_m = F.normalize(self.vision_proj_m(image_embeds_m[:,0,:]),dim=-1)
image_feat_all = torch.cat([image_feat_m.t(),self.image_queue.clone().detach()],dim=1)
#image_feat_m转置后形状为:256 x 2 , Image队列的形状为256 x 57600
#上述拼接操作是将队列复制一份,并将image_feat_m拼接到队列的头部!。
text_output_m = self.text_encoder_m(text.input_ids, attention_mask = text.attention_mask,return_dict = True, mode = 'text')
text_feat_m = F.normalize(self.text_proj_m(text_output_m.last_hidden_state[:,0,:]),dim=-1)
text_feat_all = torch.cat([text_feat_m.t(),self.text_queue.clone().detach()],dim=1)
#文本也一致
#text_feat_all和image_feat_all分别为text队列和image队列中所有的[CLS]集合
#动量蒸馏,创建软标签
sim_i2t_m = image_feat_m @ text_feat_all / self.temp
sim_t2i_m = text_feat_m @ image_feat_all / self.temp
sim_i2t_targets = alpha * F.softmax(sim_i2t_m, dim=1) + (1 - alpha) * sim_targets
sim_t2i_targets = alpha * F.softmax(sim_t2i_m, dim=1) + (1 - alpha) * sim_targets
#计算图文特征分别对队列中所有特征的相似度
sim_i2t = image_feat @ text_feat_all / self.temp
sim_t2i = text_feat @ image_feat_all / self.temp
#动量蒸馏,计算与软标签的等价KL散度。
loss_i2t = -torch.sum(F.log_softmax(sim_i2t, dim=1)*sim_i2t_targets,dim=1).mean()
loss_t2i = -torch.sum(F.log_softmax(sim_t2i, dim=1)*sim_t2i_targets,dim=1).mean()
loss_ita = (loss_i2t+loss_t2i)/2
self._dequeue_and_enqueue(image_feat_m, text_feat_m, idx)图文匹配损失ITM损失

整体流程

上述流程中,最难区分的负样本图片相当于噪声,添加到原始图片中,作为负样本;相应的,最难区分的负样本文本也相当于噪声,添加造原始文本中,作为负样本。
将两种模态使用BERT编码器融合。
原始图片和原始文本作为正样本,也是用BERT编码器融合。
ITM损失相当于找出原始样本和改变后样本的细微差别。
寻找与文本最相似的负样本图片。
将原始文本对图片相似度矩阵截断


因为要找到统一批次中,与当前文本最相似的负样本图片,而对角线是正样本图片,因此要将对角线填充0。

之后每一行筛选权重最高的图片样本,也就是最相似的负样本图片(最难区分的负样本)。
得到的相似的负样本图片集合记为image_embedding_neg。
寻找与图片最相似的负样本文本。
与以上方法一致,最终得到的最相似的文本集合记为text_embedding_neg
with torch.no_grad():
bs = image.size(0)
weights_i2t = F.softmax(sim_i2t[:,:bs],dim=1) #截断相似度矩阵,确保只包含当前批次的样本
weights_t2i = F.softmax(sim_t2i[:,:bs],dim=1)
weights_i2t.fill_diagonal_(0) #对角线为每对image-text自己的相似度,
weights_t2i.fill_diagonal_(0)
image_embedding_neg = [] #获得相对于text最难区分的negative的图片
for b in range(bs):
neg_idx =torch.multinomial(weights_t2i[b],1).item() #为当前行采样一个样本,获得其索引,相似度高的更容易被采样。
image_embedding_neg.append(image_embedding[neg_idx])#每个图片形状为(3,512),加入到list中
image_embedding_neg=torch.stack(image_embedding_neg,dim=0)#将所有图片按照第0维度堆叠,得到形状为(2,3,512)
text_embedding_neg = [] #获得相对于image最相似的negative文本。
text_atts_neg = [] #获得相对于image最相似的negative样本的注意力掩码。
for b in range(bs):
neg_idx = torch.multinomial(weights_i2t[b],1).item() #为当前行采样一个相似度最高的文本,获得其索引
text_embedding_neg.append(text_embedding['last_hidden_state'][neg_idx]) #每个文本形状为(30,768)
text_atts_neg.append(text_token['attention_mask'][neg_idx])#每个文本的注意力掩码形状为(30)
text_embedding_neg = torch.stack(text_embedding_neg,dim=0) #按照第0维度堆叠,得到形状为(2,30,768)
text_atts_neg = torch.stack(text_atts_neg,dim=0)#按照第0维度堆叠,得到形状为(2,30)
将输入的图片和最难区分负样本图片拼接,将输入的文本与最难区分的负样本文本拼接,作为比较的负样本。
#将文本和对应图片最相似的负样本文本拼接,得到形状为(4,30,768)
text_embedding_all = torch.cat([text_embedding['last_hidden_state'],text_embedding_neg],dim=0)
text_atts_all = torch.cat([text_token['attention_mask'],text_atts_neg],dim=0)
#将图片和对应文本最相似的负样本图片拼接,得到形状为(4,3,512)
image_embedding_all = torch.cat([image_embedding_neg,image_embedding],dim=0)
image_atts_all =torch.cat([image_atts,image_atts],dim=0)将原始文本特征和图片特征经过Bert-Encoder融合,得到正样本,对应的标签为1。
output_pos = self.text_encoder.bert(encoder_embeds = text_embeds,
attention_mask = text.attention_mask,
encoder_hidden_states = image_embeds,
encoder_attention_mask = image_atts,
return_dict = True,
mode = 'fusion',
)将拼接的文本特征和拼接的图片特征经过Bert-Encoder融合,得到负样本,对应标签为0。
output_neg = self.text_encoder.bert(encoder_embeds = text_embeds_all,
attention_mask = text_atts_all,
encoder_hidden_states = image_embeds_all,
encoder_attention_mask = image_atts_all,
return_dict = True,
mode = 'fusion',
) 创建标签
itm_labels = torch.cat([torch.ones(bs,dtype=torch.long),torch.zeros(2*bs,dtype=torch.long)],
dim=0).to(image.device)正样本和负样本拼接,经过itm映射,得到正负样本的概率。
vl_embeddings = torch.cat([output_pos.last_hidden_state[:,0,:], output_neg.last_hidden_state[:,0,:]],dim=0)
vl_output = self.itm_head(vl_embeddings)计算其与标签的交叉熵损失,即为ITM损失。
loss_itm = F.cross_entropy(vl_output, itm_labels) 本文来自博客园,作者:Laplace蒜子,转载请注明原文链接:https://www.cnblogs.com/RedNoseBo/p/17845565.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号