
Transoformer Pytorch实现
Transofrmer翻译任务的工作流程

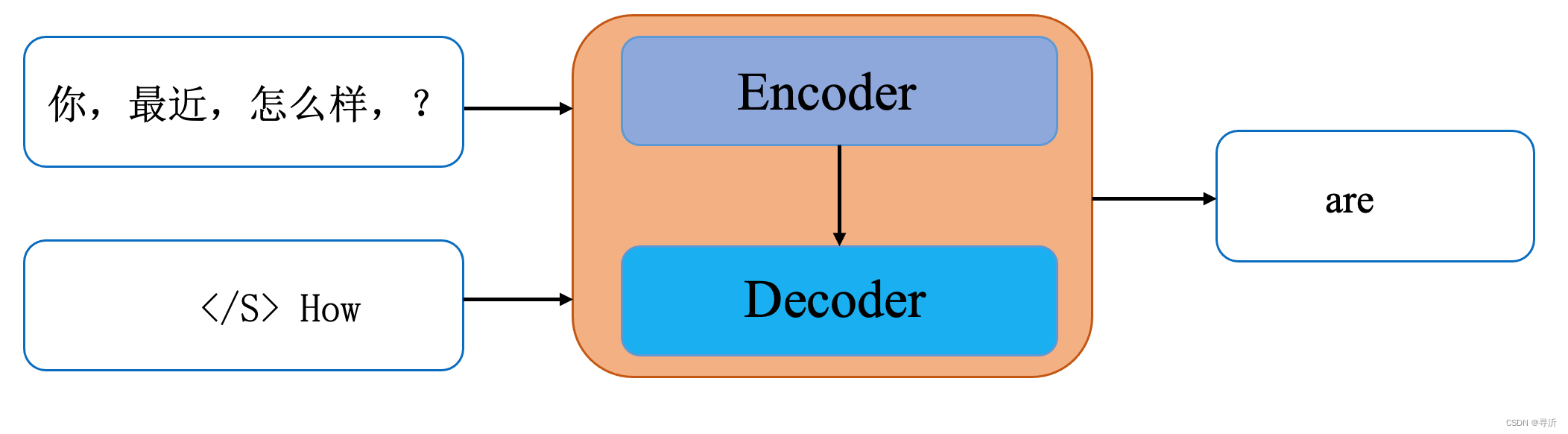



注意力Pad掩码的获得
因为输入句子需要统一长度,肯定会填充Pad特殊字符,Pad特殊字符在word embedding中的数值为0。
提前生成好注意力机制中Pad的掩码。
假设句子长度为Len,那就生成一个Len x Len 矩阵,将其Pad位置,也就是输入句子嵌入等于0的位置填充True。
对于一批句子来说,就是得到一个Batch X Len X Len的矩阵。第0维是批次,1,2维都是句子中自己单词对自己单词的注意掩码。
def get_att_pad_mask(seq_q,seq_k):
# 在Encoder输入阶段,获取输入句子中pad的掩码,此时seq_x等于seq_k,得到batch x len_q x len_q 的注意力掩码矩阵。
#注意力掩码矩阵用于计算句子的自注意力得分,将pad的得分去掉。
#seq_q:Query句子,也即是目标句子
#seq_k:Key句子,也就会源句子,第一维都是batch大小。
batch_size, len_q = seq_q.size() #获取Query句子的长度
batch_size, len_k = seq_k.size() #获取Key句子的长度
pad_att_mask = seq_k.data.eq(0).unsqueeze(1) #因为pad填充为0,所以Key句子中0位置掩码为True,非0位置掩码为False,将其扩充为 batch x batch x len_k
return pad_att_mask.expand(batch_size,len_q,len_k) #将mask 第二维扩充,也就是将第三维的len_k个复制len_q份。
多头自注意力机制
对于自注意力机制来说,Q,K,V都是输入的x与WeightQ,WeightK,WeightV得到的
对于注意力机制来说,Q是需要注意的目标target与WeightQ相乘得到,K和V是输入x与WeightK,WeightV相乘得到的。
现在讨论自注意力机制部分
映射
假设一批输入形状为Batch x Len x Dim,Batch为批次,Len为每个句子长度,Dim为每个单词的嵌入。
输入分别与WeightQ,WeightK,WeightV相乘,相当于线性映射,映射到相同的维度,整合特征。得到维度都是Batch x Len x DimUnify
划分注意力头
之后Q,K,V使用多头注意力机制就是是将 DimUnify均分给各个注意力头,也就变成了Batch x Len x num_heads x DimUnify / num_heads
将其统一把维度变换为( Batch x num_heads x Len x DimUnify / num_heads )
转置相乘
Q和K的二三维转置相乘,( Batch X num_heads X Len X DimUnify / num_heads ) X ( Batch X num_heads X DimUnify / num_heads X Len ) = ( Batch X num_heads X Len X Len )
2,3维的Len X Len 矩阵就是每个单词对其他单词的注意力得分。
掩码
根据句子输入得到Batch X Len X Len注意力掩码,但注意力得分是num_heads个注意力头的得分,形状为 ( Batch X num_heads X Len X Len )
因此要扩张维度变成Batch X 1 X Len X Len,然后将Len X Len 复制num_heads份。
计算Softmax
注意力得分最后一维进行Softmax处理(归一化),得到维度( Batch X num_heads X Len X Len)
与V相乘
V的形状为( Batch x num_heads x Len x DimUnify / num_heads )。
( Batch X num_heads X Len X Len) · ( Batch x num_heads x Len x DimUnify / num_heads ) = ( Batch x num_heads x Len x DimUnify / num_heads )
将结果改变形状,变成 ( Batch x Len x num_heads x DimUnify / num_heads ),合并最后两维就是( Batch x Len x DimUnify )
class MultiHead_SelfAttention(nn.Module):
def __init__(self,num_heads,dim):
super(MultiHead_SelfAttention, self).__init__()
self.Q = nn.Linear(dim,dim)
self.K = nn.Linear(dim, dim)
self.V = nn.Linear(dim, dim)
self.num_heads=num_heads
self.dim = dim
def forward(self,x,attn_mask=None):
B,Len,Dim = x.shape #batch x Len x dim
#改成多头注意力机制就是将每个单词的dim个嵌入向量,均分给每一个注意力头
#batch x Len x num_head x dim/num_head
Q = self.Q(x).reshape(B, Len,self.num_heads, -1).permute(0,2,1,3)
K = self.K(x).reshape(B, Len,self.num_heads, -1).permute(0,2,1,3)
V = self.V(x).reshape(B, Len,self.num_heads, -1).permute(0,2,1,3)
attentionScore = Q @ K.transpose(2,3) * ( x.shape[-1] **-0.5) #Q · K转置 / sqrt(dim)
if attn_mask != None:
#将其扩充第1个维度后得到:batch x 1 x seq_len x seq_len。
# 将其第0维度重复1次,第1维度重复num_head次(后面所有维度赋值num_head次数),第2维重复1次,第3维重复1次
attn_mask=attn_mask.unsqueeze(1).repeat(1,self.num_heads,1,1)
attentionScore.masked_fill_(attn_mask,1e-9)#对多头注意力的份进行掩码填充为负无穷,也就是所有pad字符注意力填充为负无穷。
attentionScore = attentionScore.softmax(dim=-1)#softmax计算
print(attentionScore.shape)
print(V.shape)
V = (attentionScore @ V).permute(0,2,1,3).reshape(B,Len,Dim)
if attn_mask!=None:
return V,attentionScore
else:
return V
LayerNorm层
作用
BatchNorm计算的是一批样本,样本间同一个通道进行正则化
LayerNorm计算的是一个样本内,一个样本内进行正则化。
在一个句子中,因为句子是通过填充补全到统一长度,一个句子中某个词可能对应于其他句子中的填充的0,那么计算就无意义了。

实现代码
class LayerNorm(nn.Module):
def __init__(self,features,eps=1e-6):
super(LayerNorm,self).__init__()
self.a_2 = nn.Parameter(torch.ones(features))#可学习的参数
self.b_2 = nn.Parameter(torch.zeros(features))#可以学习的参数
self.eps =eps
def forward(self,x):
#BatchNorm计算的是一批样本,相同位置之间的均值和方差。
#LayerNorm计算的是一个样本内,所有单词的均值和方差。
mean = x.mean(-1,keepdim=True) #计算最后一维度的均值 3x100
std = x.std(-1,keepdim=True) #计算最后一个维度的方差
return self.a_2 * (x-mean) / (std+self.eps) + self.b_2 #计算每个样本x内正则化
位置编码
作用
弥补自注意力机制的短板,区分不同位置字符的绝对位置。
自注意力机制没有位置信息,比如“我爱你”和“你爱我”,每个词组合后注意力得分是相同的,所以需要在每个字符的嵌入上加上位置编码。
公式

pos为token的位置,dim为token嵌入后的维度,i为单个token的嵌入后的维度中第i个向量。
结构
每个token嵌入后的维度为dim,每个token就对应一个dim维的位置编码。
代码实现
class PositionalEncoding(nn.Module): #整理特征,不改变特征维度
def __init__(self,max_len,dim,dropout):
#max_len:位置编码的总个数,位置编码与输入的特征无关,可以预先生成指定个数,与特征相加的时候可以切特取部分。
#dim:每个词的维度
super(PositionalEncoding,self).__init__()
self.dropout = nn.Dropout(p=dropout)
pe = torch.zeros(max_len,dim) #生成max_len x dim 维度的矩阵
position = torch.arange(0,max_len).unsqueeze(1) #
div_term = torch.exp( torch.arange(0,dim,2) * -(math.log(10000.0)/dim)).unsqueeze(0)
pe[:,0::2]=torch.sin(position*div_term)
pe[:,1::2]=torch.cos(position*div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe',pe) #保证pe在训练的时候不会更新。
def foward(self,x):
out = x + self.pe[:,:x.size(1)] #将与x对应位置的位置编码加起来。
out = self.dropout(out)
return out可以知道位置编码和特征x无关,且分子和分母公共的部分,可以用切片传播方式实现。
可以将相除改成相乘。

其中 -ln10000 / dim这是一个固定的数值。
pe用torch.zeros生成 ( max_len , dim ) 维度的0占位符。
position用torch.arrange生成0到max_len,形状为 ( maxlen,) 数组,表示生成0到max_len个字符的位置编码,为[0,1,2,3,...,max_len],再改变形状为 ( maxlen , 1 )。
div_ter先生成 [0,2,...,dim],形状为(dim/2,)占位符,一共dim/2个,因为2i和2i+1位置是相同,只不过是一个用sin和cos。然后再乘以一个固定的数值 -ln10000 / dim,再取exp,得到如下:
e^{ [0,2,...,dim] * -ln10000/dim },形状为(1,dim/2)
position的形状为 ( maxlen,1 )
position 和 div_term相乘后就是( maxlen,dim/2 )
取 sin( position * div_term) 赋值给pe第二维度的偶数下标。
取cos(position * div_term) 赋值给pe第二维度的奇数下标。
最后将pe第0维度扩充,为了对应句子的批次。
本文来自博客园,作者:Laplace蒜子,转载请注明原文链接:https://www.cnblogs.com/RedNoseBo/p/17797778.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号