
RoI Align 和 RoI Pooling
RoI Pooling
作用
将候选区域大小统一。
工作原理
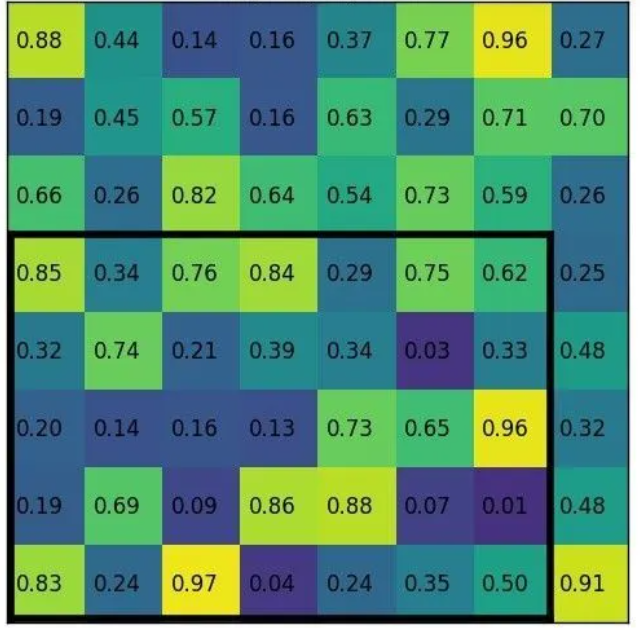
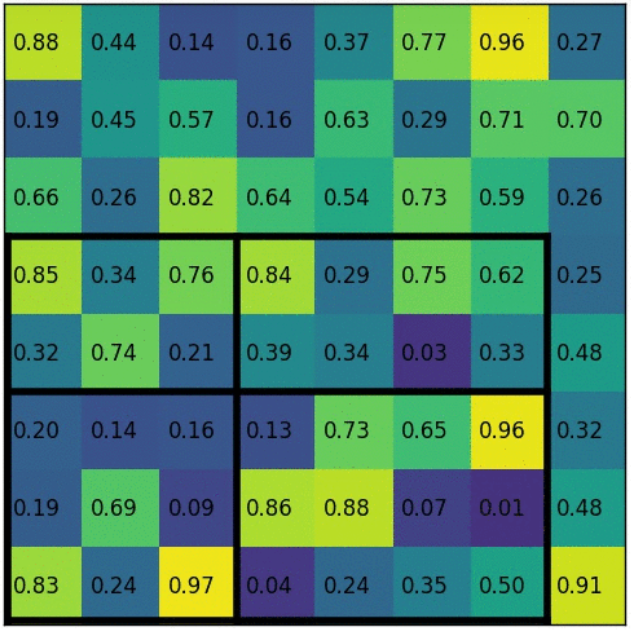
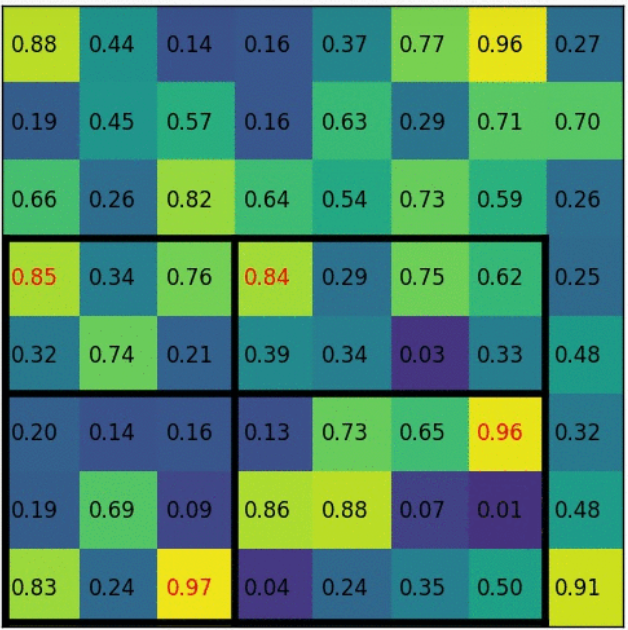
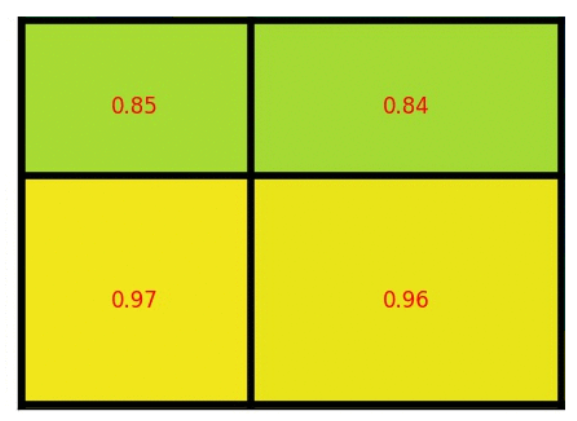
假设要将7x5的候选区域,池化为2x2大小。
划分的时候粗劣的取整,7/2得到3和4,5/2得到2和3。
每个区域取最大值填充,每个网格的像素值。
缺点
直接取整太粗糙,会丢失部分信息。
在Faster RCNN中,输入RoI Pooling的是特征图,,候选框对应的是原图,需要将其放大到原图,然后再取候选区域。
假设原图大小为512x 256,映射到特征图的步距为32,则特征图大小大小为16 x 8。
假设原图候选区域中心点为(292 , 192),候选区域宽度为200,高度为145。
在RoI Pooling中需要先将特征图16 x 8放大到原图大小,也就是512x 256。
在原图获取候选位置,再将候选区域缩小到对应特征图尺寸。
则在特征图中,候选区域中心点为(9.125 , 6),宽度为6.25,高度为4.53。但是像素位置要取整,候选区域中心点为(9 , 6),宽度为6,高度为4,再粗略的向上取整或向下取整划分。
最终会丢是小数部分的精度。
RoI Align
作用
按照候选框,将图片中候选区域提取出来,并池化为统一大小,同时避免丢失更多的信息。
工作原理

假设要将大小为7x5的原图池化为2x2大小的特征图。
-
-
- 第一次均等划分,保持浮点边界,7/2=3.5,5/2=2.5。
- 第二次每个子网格按照同等规模继续划分,保持浮点边界,得到最小区域。
- 每个最小区域中,根据四个边界点,做双线性插值,得到最小区域的中心点像素(图中标记为 x )。
- 每个最小区域用中心点像素填充最小区域。
- 每个子区域做最大池化,最终的到目标大小的特征图。
-
步骤总结
第一次划分子网格 -> 每个子网格再划分最小区域 -> 小区域双线性插值取中心像素 -> 中心像素填充最小区域 -> 每个子网格做最大池化
Pytorch代码使用RoI Align
import torch
import torchvision
pooler = torchvision.ops.RoIAlign(output_size=2,sampling_ratio=2,spatial_scale=5)
#在Mask RCNN中输入的是特征图,框对应的是原图,因此需要将其缩放为原图大小。在实际应用中,若输入的是原图,缩放为1即可。
#spatial_scale: 原图到特征图的缩放比例,框对应的是原图,假设框对应的是224x224的原图,输入的特征图是112x112,则缩放比例为0.5。
#sampling_ratio:插值网格中采样点个数。如果大于0,则每个bin用sampling_ratio X sampling_ratio采样点,若小于0,则自适应
output = pooler(inputTensor,boxes)
#输入图像为一批图像,所以inputTensor形状为(N,C,H,W),N表示图像索引,C表示通道,H表示高度,W表示宽度
#boxes为tensor(K,5)形式,第一列K表示对应的图片索引,5表示候选框索引以及4个坐标点
#boxes或者一个Tensor列表,形式为List[ tensor(L,4) ],L表示候选框索引,4表示四个坐标点,tensor处于list中的下标对应图片索引。
本文来自博客园,作者:Laplace蒜子,转载请注明原文链接:https://www.cnblogs.com/RedNoseBo/p/17699844.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号