
空间变换网络
函数说明
make_grid函数
torchvision.utils.make_grid(tensor, nrow=8, padding=2, normalize=False, range=None, scale_each=False, pad_value=0)tensor:输入的张量,一般为大小为(B, C, H, W)的四维张量,其中B是批次大小,C是通道数,H和W分别是每张图像的高度和宽度。nrow:每行显示的图像数量,默认为 8。padding:每个图像之间的像素填充,默认为 2。normalize:是否进行归一化,默认为False。如果设置为True,则将图像像素值归一化到[0, 1]范围。range:将图像像素值缩放到指定范围,默认为None。如果range给定为一个元组(min, max),则将像素值缩放到该范围内。scale_each:是否对每个图像独立进行像素缩放,默认为False。如果设置为True,则将每个图像的像素值独立缩放。pad_value:填充像素的值,默认为 0。
返回的是一个图片张量。每行8个图片,图片前后2像素填充,起始图片和结束图片的前后也会填充。
假设显示手写数字识别的数据集,显示64张图片,每张图片大小为28 x 28,那么横向和竖向的的大小为:28 x 8+ 2 * 9=242
![]()
torch.nn.functional.affine_grid函数
torch.nn.functional.affine_grid( theta , size )
theta:一组放射变换矩阵参数,N x 2 x 3
size:要输出的图像的size,N x C x H x W
返回一个tensor,表示仿射变换网格,N x H x W x 2
torch.nn.functional.grid_sample函数
torch.nn.functional.grid_sample( input_image, grid )
input_image:输入图像
grid :仿射变换网格,N x H x W x 2
返回为经过仿射变换的图片。
图片归一化方法
各自通道乘以各自的方差再加上各自的均值
def convert_image_np(inp):
"""Convert a Tensor to numpy image."""
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
return inp
空间变换网络
网络结构图
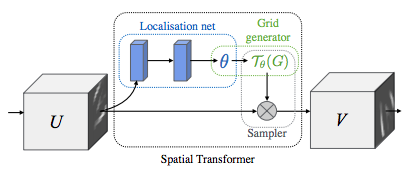
本质是通过学习得到一个仿射变换参数
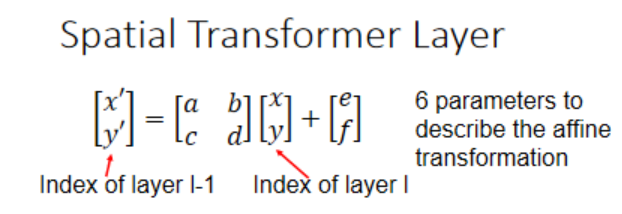
其中a,b,c,d,e,f是仿射变换参数,需要通过学习得到。
Localization Net
Grid Generator
根据Localization Net生成的仿射变换参数,结合原始图像的大小,生成仿射变换网格。
grid = F.affine_grid(theta,x.size())Sampler
根据 Grid Generator生成的仿射变换网格,将原始图片进行仿射变换。
x = F.grid_sample(x,grid)结果
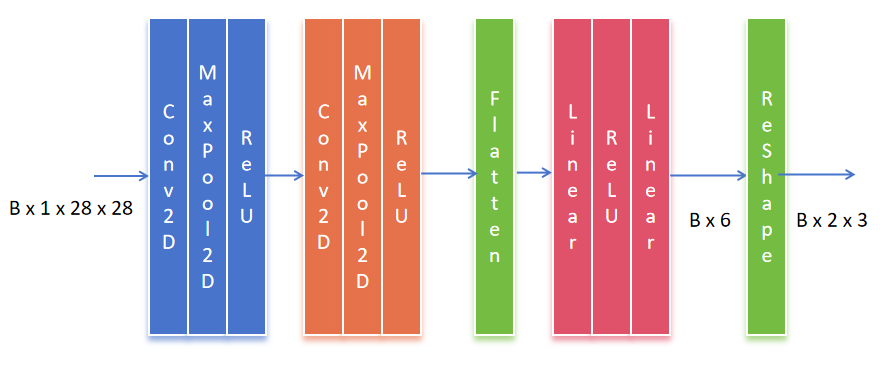
整个网络结构
class STN(nn.Module):
def __init__(self):
super(STN,self).__init__()
self.conv1 = nn.Conv2d(in_channels=1,out_channels=10,kernel_size=5)
self.conv2 = nn.Conv2d(in_channels=10,out_channels=20,kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320,50)
self.fc2 = nn.Linear(50,10)
self.localization = nn.Sequential(
nn.Conv2d(in_channels=1,out_channels=8,kernel_size=7),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.ReLU(True),
nn.Conv2d(in_channels=8,out_channels=10,kernel_size=5),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.ReLU(True)
)
self.fc_loc = nn.Sequential(
nn.Linear(in_features=10*3*3,out_features=32),
nn.ReLU(True),
nn.Linear(in_features=32,out_features=3*2)
)
self.fc_loc[2].weight.data.zero_()
self.fc_loc[2].bias.data.copy_(torch.tensor([1,0,0,0,1,0],dtype=torch.float))
def stn(self,x):
xs = self.localization(x)
xs = xs.view(-1,10*3*3)
theta = self.fc_loc(xs)
theta = theta.view(-1,2,3)
grid = F.affine_grid(theta,x.size())
x = F.grid_sample(x,grid)
return x
def forward(self,x):
x = self.stn(x)
x = self.conv1(x)
x = F.max_pool2d(x,2)
x = F.relu(x)
x = self.conv2(x)
x = self.conv2_drop(x)
x = F.max_pool2d(x,2)
x = F.relu(x)
x = x.view(-1,320)
x = self.fc1(x)
x = F.relu(x)
x = F.dropout(x,training=self.training)
x = self.fc2(x)
return F.log_softmax(x,dim=1)辅助函数
def convert_image_np(inp):
"""Convert a Tensor to numpy image."""
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
return inp
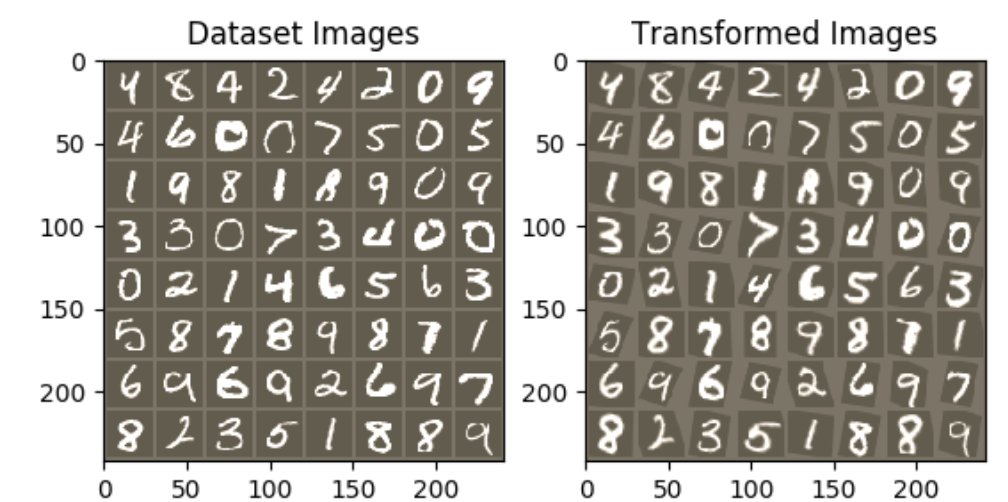
# 我们想要在训练之后可视化空间变换器层的输出
# 我们使用STN可视化一批输入图像和相应的变换批次。
def visualize_stn():
with torch.no_grad():
# Get a batch of training data
data = next(iter(test_loader))[0].to(device)
input_tensor = data.cpu()
transformed_input_tensor = model.stn(data).cpu()
in_grid = convert_image_np(
torchvision.utils.make_grid(input_tensor))
out_grid = convert_image_np(
torchvision.utils.make_grid(transformed_input_tensor))
# Plot the results side-by-side
f, axarr = plt.subplots(1, 2)
axarr[0].imshow(in_grid)
axarr[0].set_title('Dataset Images')
axarr[1].imshow(out_grid)
axarr[1].set_title('Transformed Images')
训练函数
optimizer = optim.SGD(model.parameters(), lr=0.01)
def train(epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % 500 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
#
# 一种简单的测试程序,用于测量STN在MNIST上的性能。.
#
def test():
with torch.no_grad():
model.eval()
test_loss = 0
correct = 0
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
# 累加批量损失
test_loss += F.nll_loss(output, target, size_average=False).item()
# 获取最大对数概率的索引
pred = output.max(1, keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'
.format(test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))完整代码
from __future__ import print_function
from torchsummary import summary
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torchvision
from torchvision import datasets, transforms
import matplotlib.pyplot as plt
import numpy as np
plt.ion()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
train_loader = torch.utils.data.DataLoader(
datasets.MNIST(root='.', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])), batch_size=64, shuffle=True, num_workers=4)
# 测试数据集
test_loader = torch.utils.data.DataLoader(
datasets.MNIST(root='.', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
])), batch_size=64, shuffle=True, num_workers=4)
class STN(nn.Module):
def __init__(self):
super(STN,self).__init__()
self.conv1 = nn.Conv2d(in_channels=1,out_channels=10,kernel_size=5)
self.conv2 = nn.Conv2d(in_channels=10,out_channels=20,kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320,50)
self.fc2 = nn.Linear(50,10)
self.localization = nn.Sequential(
nn.Conv2d(in_channels=1,out_channels=8,kernel_size=7),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.ReLU(True),
nn.Conv2d(in_channels=8,out_channels=10,kernel_size=5),
nn.MaxPool2d(kernel_size=2,stride=2),
nn.ReLU(True)
)
self.fc_loc = nn.Sequential(
nn.Linear(in_features=10*3*3,out_features=32),
nn.ReLU(True),
nn.Linear(in_features=32,out_features=3*2)
)
self.fc_loc[2].weight.data.zero_()
self.fc_loc[2].bias.data.copy_(torch.tensor([1,0,0,0,1,0],dtype=torch.float))
def stn(self,x):
xs = self.localization(x)
xs = xs.view(-1,10*3*3)
theta = self.fc_loc(xs)
theta = theta.view(-1,2,3)
grid = F.affine_grid(theta,x.size())
x = F.grid_sample(x,grid)
return x
def forward(self,x):
x = self.stn(x)
x = self.conv1(x)
x = F.max_pool2d(x,2)
x = F.relu(x)
x = self.conv2(x)
x = self.conv2_drop(x)
x = F.max_pool2d(x,2)
x = F.relu(x)
x = x.view(-1,320)
x = self.fc1(x)
x = F.relu(x)
x = F.dropout(x,training=self.training)
x = self.fc2(x)
return F.log_softmax(x,dim=1)
model = STN().to(device)
optimizer = optim.SGD(model.parameters(), lr=0.01)
def train(epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % 500 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
#
# 一种简单的测试程序,用于测量STN在MNIST上的性能。.
#
def test():
with torch.no_grad():
model.eval()
test_loss = 0
correct = 0
for data, target in test_loader:
data, target = data.to(device), target.to(device)
output = model(data)
# 累加批量损失
test_loss += F.nll_loss(output, target, size_average=False).item()
# 获取最大对数概率的索引
pred = output.max(1, keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'
.format(test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
def convert_image_np(inp):
"""Convert a Tensor to numpy image."""
inp = inp.numpy().transpose((1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
inp = std * inp + mean
inp = np.clip(inp, 0, 1)
return inp
# 我们想要在训练之后可视化空间变换器层的输出
# 我们使用STN可视化一批输入图像和相应的变换批次。
def visualize_stn():
with torch.no_grad():
# Get a batch of training data
data = next(iter(test_loader))[0].to(device)
input_tensor = data.cpu()
transformed_input_tensor = model.stn(data).cpu()
in_grid = convert_image_np(
torchvision.utils.make_grid(input_tensor))
out_grid = convert_image_np(
torchvision.utils.make_grid(transformed_input_tensor))
# Plot the results side-by-side
f, axarr = plt.subplots(1, 2)
axarr[0].imshow(in_grid)
axarr[0].set_title('Dataset Images')
axarr[1].imshow(out_grid)
axarr[1].set_title('Transformed Images')
if __name__=='__main__':
'''
for epoch in range(1, 20 + 1):
train(epoch)
test()
'''
visualize_stn()
# 在某些输入批处理上可视化STN转换
plt.ioff()
plt.show()本文来自博客园,作者:Laplace蒜子,转载请注明原文链接:https://www.cnblogs.com/RedNoseBo/p/17693069.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号