
目标检测算法——手撕Faster R-CNN
Faster R-CNN网络结构
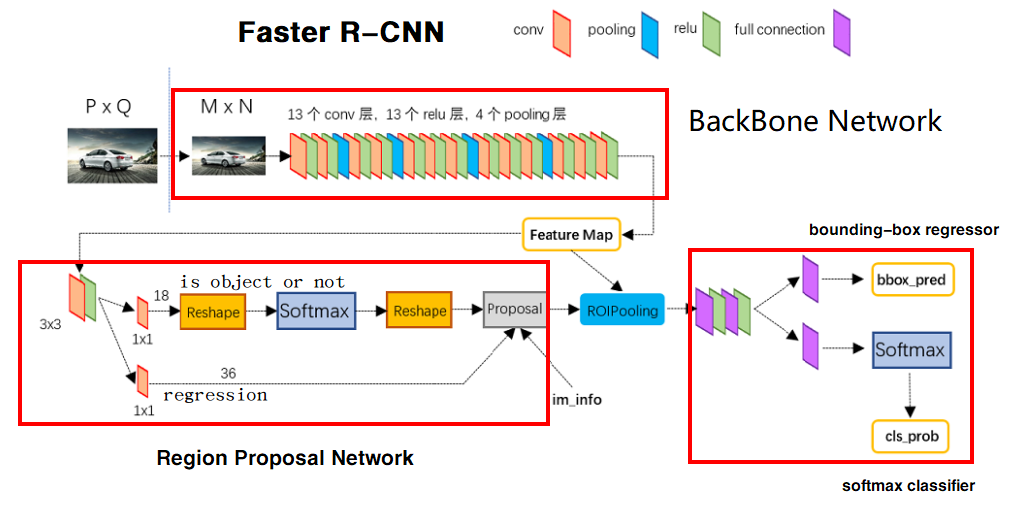
Faster R-CNN有四个子模块组成
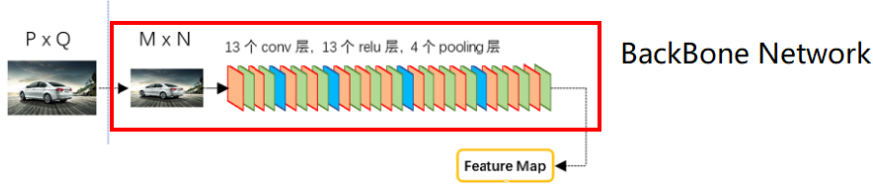
主干网络
主干网络可以是预训练好的ResNet50,VGG16等网络,将图片压缩为固定尺寸的Feature Map。已经预训练完毕。
ResgionProposalNetwork
根据Feature Map生成与原图尺寸对应的建议框。需要训练。
ROIPooling
给定Feature Map和一系列建议框,将Feature Map中对应的每个建议框内容截取为相同形状,作为分类器的输入,因为建议框大小不同,但是卷积神经网络输入要求尺寸相同。
注意:RoIPooling用的是原图压缩后的Feature Map,而不是直接使用原图,而建议框的尺寸对应的是原图尺寸,因此在RoIPooling内部工作中,要先对Feature Map缩放到原尺寸,然后进行截取。
RoIHead
对每个区域分别进行分类预测和回归预测。需要训练。
主干网络(以ResNet为例)
ResNet主要由ConvBlock和IdentityBlock组成。主干网络的输入为 BatchSize x 3 x 600 x 600,输出为 BatchSize x 1024 x 38 x38,也就是Feature Map的形状
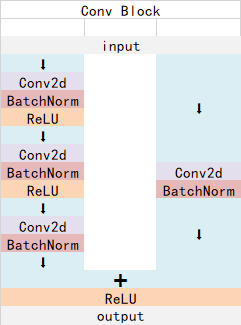


ConvBlock有残差连接,会改变形状。IdentityBlock没有残差连接,不会改变形状。
ConvBlock的stride为1时,输出通道数为原来的4倍,不改变宽高;stride为2时,输出通道数为原来2倍,宽高缩小为2倍。
ConvBlock代码
class ConvBlock(nn.Module):
def __init__(self,in_channels,stride=1):
super(ConvBlock,self).__init__()
out_channels=in_channels
if stride==2:
#stride为2时,输出通道的基数为输入通道的1/2,后面乘4倍,就是原来的2倍。
#stride为1时,输出通道的基数等于输入通道,后面乘4倍,就是输入通道的4倍。
out_channels=in_channels//2
self.conv1 = nn.Conv2d(in_channels=in_channels,out_channels=out_channels,kernel_size=1,stride=1,bias=False)
self.bn1 = nn.BatchNorm2d(num_features=out_channels)
self.conv2 = nn.Conv2d(in_channels=out_channels,out_channels=out_channels,kernel_size=3,stride=stride,padding=1,bias=False)
self.bn2 = nn.BatchNorm2d(num_features=out_channels)
self.conv3 = nn.Conv2d(in_channels=out_channels,out_channels=out_channels*4,kernel_size=1,stride=1,bias=False)
self.bn3 = nn.BatchNorm2d(num_features=out_channels*4)
self.resconv = nn.Conv2d(in_channels=in_channels,out_channels=out_channels*4,kernel_size=1,stride=stride,bias=False)
self.resbn = nn.BatchNorm2d(num_features=out_channels*4)
self.relu = nn.ReLU(inplace=True)
def forward(self,x):
out = self.conv1(x)
out = self.bn1(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.conv3(out)
out = self.bn3(out)
residual = self.resconv(x)
residual = self.resbn(residual)
out += residual
out = self.relu(out)
return out
IdentityBlock代码
class IdentityBlock(nn.Module):
def __init__(self, in_channels):
super(IdentityBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels=in_channels, out_channels=in_channels // 4, kernel_size=1, stride=1, bias=False)
self.bn1 = nn.BatchNorm2d(num_features=in_channels // 4)
self.conv2 = nn.Conv2d(in_channels=in_channels // 4, out_channels=in_channels // 4, kernel_size=3, stride=1,padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(num_features=in_channels // 4)
self.conv3 = nn.Conv2d(in_channels=in_channels // 4, out_channels=in_channels, kernel_size=1, stride=1,bias=False)
self.bn3 = nn.BatchNorm2d(num_features=in_channels)
self.relu = nn.ReLU(inplace=True)
def forward(self, x):
out = self.conv1(x)
out = self.bn1(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.conv3(out)
out = self.bn3(out)
out = self.relu(out)
return out
ResNet50代码
class ResNet50(nn.Module):
def __init__(self,classNumber=1000):
super(ResNet50, self).__init__()
#输入600,600,3
self.conv1 = nn.Conv2d(in_channels=3,out_channels=64,kernel_size=7,stride=2,padding=3,bias=False)
self.bn1 = nn.BatchNorm2d(num_features=64)
self.relu = nn.ReLU(inplace=True)
# 300,300,64 -> 150,150,64
self.maxpool = nn.MaxPool2d(kernel_size=3,stride=2,ceil_mode=True)
self.cb1 = ConvBlock(in_channels=64,stride=1)
self.ib11 = IdentityBlock(in_channels=256)
self.ib12 = IdentityBlock(in_channels=256)
self.cb2 = ConvBlock(in_channels=256, stride=2)
self.ib21 = IdentityBlock(in_channels=512)
self.ib22 = IdentityBlock(in_channels=512)
self.ib23 = IdentityBlock(in_channels=512)
self.cb3 = ConvBlock(in_channels=512, stride=2)
self.ib31 = IdentityBlock(in_channels=1024)
self.ib32 = IdentityBlock(in_channels=1024)
self.ib33 = IdentityBlock(in_channels=1024)
self.ib34 = IdentityBlock(in_channels=1024)
self.ib35 = IdentityBlock(in_channels=1024)
def forward(self,x):
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.maxpool(out)
out = self.cb1(out)
out = self.ib11(out)
out = self.ib12(out)
out = self.cb2(out)
out = self.ib21(out)
out = self.ib22(out)
out = self.ib23(out)
out = self.cb3(out)
out = self.ib31(out)
out = self.ib32(out)
out = self.ib33(out)
out = self.ib34(out)
out = self.ib35(out)
return outRegionProposalNetwork
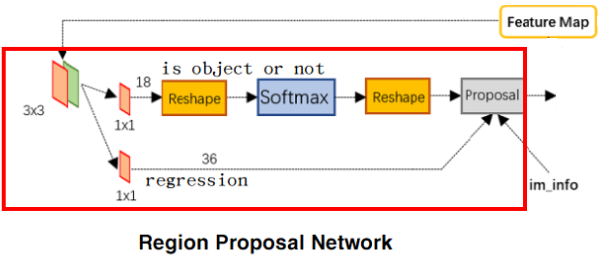
输入形状
输入的Feature Map形状为 BatchSize x 1024 x 38 x 38。
特征整合
Feature Map再经过3x3的卷积层处理,形状不变,仍然为 BatchSize x 1024 x 38 x 38,作用为对特征进行整合。
生成基础先验框
经过整理后的Feature Map的形状为38 x 38,不考虑通道数,在每个像素位置生成9个Anchor,
Feature Map大小为38x38,原图大小为600x600,在特征图每个像素点都生成9个先验框,对应原图就是每个16个像素取一个像素为中心点生成9个先验框。
以下图为例,每个网格代表一个像素点,9x9的原图压缩为3x3的特征图,特征图上每个像素点对应原图上一个3x3的蓝色方框,取原图上方框的中心则是以步长为3取。
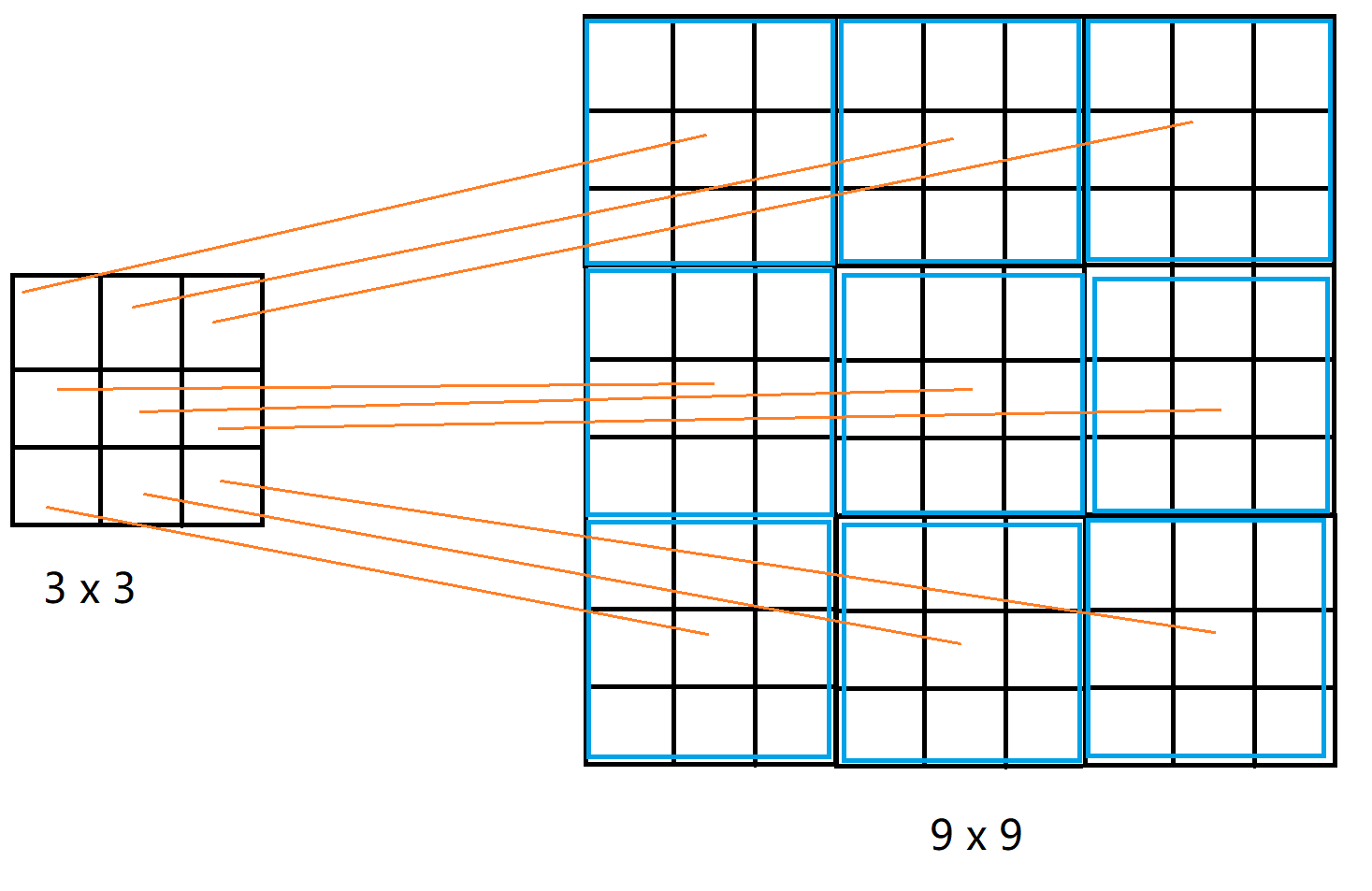
从600x600压缩到38x38,在原图上,每个中心点都有9个先验框,中心点间隔为16。
确定好了中心后,就是对每个中心点生成先验框,先验框的形状如下:
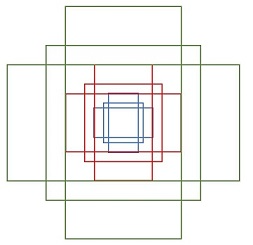
随机选取不同中心点的不同先验框,如下图所示:
生成先验框代码
import numpy as np
import torch
def GenerateOneAnchor(base_size=16,ratios=[0.5,1,2],base_scales=[8,16,32]):
#生成一个网格的先验框列表,3中宽高比,3中缩放尺度,每种比例和缩放尺度生成一个先验框,也就是一共9个先验框
# scales表示对基础尺寸base_size的缩放,
# ratio为高和宽的比值,高度宽度比为0.5时,高度:XXX * 0.5,宽度:XXX * 1/0.5 = XXX * 2
# 遍历方式为:对每种高宽比,生成不同缩放尺度的base_size先验框
#初始化先验框
baseAnchor = np.zeros( (len(ratios) * len(base_scales) , 4 ) ,dtype=np.float32)
for i in range(len(ratios)):
for j in range(len(base_scales)):
#h,w表示每个先验框的高度和宽度
h = base_size * base_scales[j] * np.sqrt(ratios[i]) # 0.5, 1, 2
w = base_size * base_scales[j] * np.sqrt(1./ratios[i]) #1/0.5=2,1/1=1,1/2=0.5
#每个先验框四个坐标,得到中心点的坐标后,分别计算每个先验框左下和右上点
index = i * len(base_scales) + j
baseAnchor[index, 0] = -h / 2.
baseAnchor[index, 1] = -w / 2.
baseAnchor[index, 2] = h / 2.
baseAnchor[index, 3] = w / 2.
return baseAnchor
def GenerateAnchorForOriginalImage(anchor,feat_stride,height,width):
#按照压缩的图片像素点,在原图上中心点生成先验框
#因为原图尺寸为600,压缩后的图片尺寸为38,相当于压缩了16倍,因此压缩后图片的每个像素点对应原图的位置应该是以16为步长。feat_stride传入为16
#生成原图上的中心点
shift_x = np.arange(0,width * feat_stride,feat_stride)
shift_y = np.arange(0,height * feat_stride,feat_stride)
#中心点组合,生成网格,shift_x为网格点的x坐标,shift_y为网格点的y坐标
shift_x,shift_y=np.meshgrid(shift_x,shift_y)
#ravel将数组拉成一维,然后按照维度1组合,坐标x和y两两组合在一起。
#最终得到压缩后图片所有像素点的先验框在原图上的坐标,也就是原图上每个先验框的中心点位置
shift = np.stack( (shift_x.ravel() , shift_y.ravel() , shift_x.ravel() , shift_y.ravel(),), axis=1 )
#anchor形状为9x4,A保存先验框个数
A = anchor.shape[0]
#shift保存的是所有网格中心点的坐标,shape的第一个维是所有中心点的个数,也就是38 x 38 = 1444
K = shift.shape[0]
#将基础先验框1x9x4,加到K个坐标上,假设K=1。则是将矩阵9 x 4 与 矩阵 1 x 4 相加,也就是将1x4分别加到9行上。
anchor = anchor.reshape( (1,A,4) ) + shift.reshape((K,1,4))
anchor = anchor.reshape((K*A,4)).astype(np.float32)
#K*A也就是(38 x 38) x 9 = 12996,因此最终获得的anchor形状为 12996x4
return anchor分类预测
卷积
经过18个1x1的卷积核处理后形状变为 BatchSize x 18 x 38 x 38(卷积核个数=输出通道个数)。
第一次ReShape
合并最后两维(38 x 38),并将第2维设置为2,得到形状为BatchSize x 2 x 12996 ( BatchSize x 2 x(9 x 38 x 38)),表示每个图片两组长度为12996的概率,第1组表示12996个先验框属于背景的概率,第2组表示先验框属于前景的概率。
为了方便表示,将形状改为BatchSize x 12996 x 2,意为每个图片12996个先验框,每个先验框存储两个值,分别表示属于背景和属于前景的概率。
Softmax处理
上一步处理后,输入的形状为BatchSize x 12996 x 2 ,对最后一维进行softmax处理。
Softmax处理后的形状为 BatchSize x 12996 x 2。第1维“BatchSize”表示图片,第2维“12992”表示图片的先验框,第3维的“2”表示图片的某个先验框属于前景和背景的概率。
第二次Reshpe
由于只需要获得每个先验框属于物体的概率,只需要取出第3维索引为1的那一组概率。得到的形状为 BatchSize x 12996。存储每个图片中12996个先验框每个先验框属于物体的概率。
回归预测
经过36个1x1的卷积核处理后形状变为 BatchSize x 36 x 38 x 38(卷积核个数=输出通道个数)。
将形状ReShape为 BatchSize x 4 x12996 ( BatchSize x 4 x(9 x 38 x 38) ),表示每个图片有4组长度为12996的偏移量,4组分别表示所有先验框中心点x坐标偏移量,中心点y坐标偏移量,宽度偏移量,高度偏移量(与基础先验框的左下右上xy坐标表示有区别)。
为了方便表示,将36放在最后一维,合并中间,最后一维变为4,得到形状 BatchSize x 12996 x 4,表示每个图片12996个先验框,每个先验框4个偏移量。
Proposal
经过分类预测得到形状为BatchSize x 12996的图片先验框属于前景的概率。这个概率可以作为先验框的得分。
经过回归预测得到形状为BatchSize x 12996 x 4 的图片先验框的坐标偏移信息。
现在用回归预测结果BatchSize x 12996 x 4对基础先验框进行修正得到建议框。
然后使用分类预测结果得分(概率),选择得分高的建议框返回。
偏移量的学习
绿色框代表Ground Truth (G),用(Gx,Gy,Gw,Gh)表示;红色框代表基础先验框Anchor (A),用(Ax,Ay,Aw,Ah)表示;蓝色框代表最终逼近得到的建议框,用G'表示。

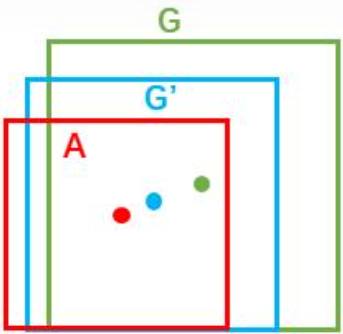
现在需要通过学习获得偏移量d,使得A尽可能的逼近G得到G'。
在学习过程中,Ground Truth框和Anchor框的偏移量作为标签,记为(tx,ty,tw,th),原论文中的计算方式为:
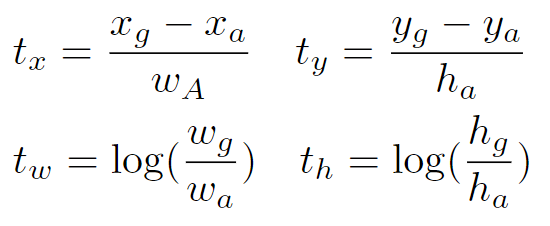
-
-
-
-
- xg为G框中心点x坐标,yg为G框中心点y坐标,xa为A框中心点x坐标,ya为A框中心点y坐标。
- wg为G框宽度,hg为G框高度,wa为A框宽度,ha为A框高度。
-
-
-
使用d*(A)表示预测的偏移量,星号*分别代表dx(A),dy(A),dw(A),dh(A)。d*(A)。
![]()
-
-
-
-
- F(A)表示anchor A在Feature Map中的特征向量(在回归预测中,Feature Map经过卷积之后得到特征BatchSize x12996 x 4 ,每个先验框的特征向量即F(A) )。
- W*T是权重超参数,通过学习得到。
-
-
-
论文中使用的是smooth-L1损失(综合了L1损失和L2损失的优点):
![]()
为了表述清晰,使用L1损失:
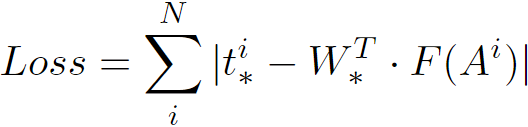
优化目标为寻找合适的权重参数矩阵W:
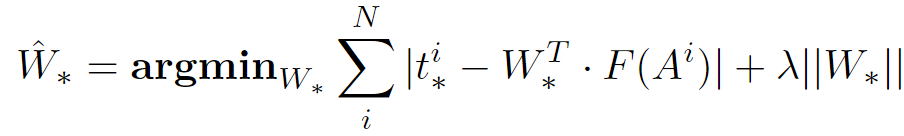
i:Anchor的下标
N:Anchor的总数
*:分别表示x,y,w,h。
一共需要优化出四个权重参数矩阵W,分别表示Wx,Wy,Ww,Wh。
训练好了之后就可以根据基础先验框来预测偏移量了。
“交并比”计算GroundTruth和先验框的差距
两个框之间的重叠程度可以使用“交并比”来衡量。
IoU = 交集 / 并集

交集求解
现在已知两个框的左下坐标和右上坐标,关键在于求出相交区域的面积,首先要求得相交区域的宽和高。
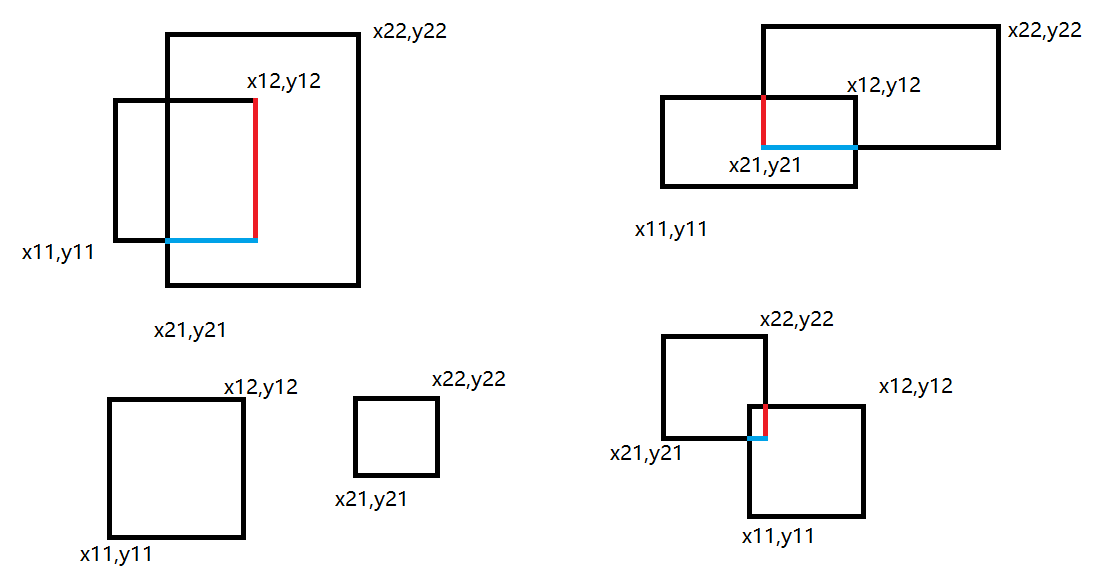
交集求解
两个矩形的右上坐标中,x取最小的一个,两个矩形的左下坐标中,x取最大的,两者相减即使宽度。高度计算亦是如此。
如第一个图中,宽度=x12-x21,高度=y12-y11。
并集求解
并集=两个矩形总面积-两个矩形交集
算法实现
两组框的IoU计算
#输入:两个框数组,两组形状分别为 k x 4和 m x 4,其中k,m表示框的个数,4表示左下角xy坐标和右上角xy坐标
#bboxa中每一个框分别要与bboxb中所有框计算
#输出:每一对框的交并比,形状为k x m
def bbox_iou(bboxa, bboxb):
#优化计算方式实现
if bbox_a.shape[1] != 4 or bbox_b.shape[1] != 4:
print(bbox_a, bbox_b)
raise IndexError
#将bbox_a中间扩展1维度变成 k x 1 x 4,与bbox_b的所有框比较m x 4
#相当于将bbox_a中,每个1x4的框广播到bbox_b中进行运算,结果形状为k x m x 4
tl = np.maximum(bbox_a[:, None, :2], bbox_b[:, :2]) #比较每两对左下坐标,x,y均取最大的
br = np.minimum(bbox_a[:, None, 2:], bbox_b[:, 2:]) #比较每两对右上坐标,x,y均取最小的
#若最小的右上角坐标,都要大于最大的左下角坐标,说明没有交集,为False,等于乘0,否则乘1
area_i = np.prod(br - tl, axis=2) * (tl < br).all(axis=2)
#每个框排列形式:x1,y1,x2,y2。每个框的运算为[x2,y2] - [x1,y1] = [x2-x1,y2-y1],每个框再按照axis=1相乘(x2-x1)*(y2-y1)即为面积
area_a = np.prod(bbox_a[:, 2:] - bbox_a[:, :2], axis=1)
area_b = np.prod(bbox_b[:, 2:] - bbox_b[:, :2], axis=1)
return area_i / (area_a[:, None] + area_b - area_i)
非极大值抑制
可以防止一个区域内框的个数过多,留下来的框之间的IoU值小于阈值。
算法的输入:按照得分降序排序的框列表detection_class,形状为n x 4,非极大值抑制的阈值nms_thres,默认为0.7。
算法流程:
1.取出detection_class中最前面的框,加入到max_detections列表中。
2.将刚刚加入max_detections列表中的框,与detection_class中剩余的所有框计算IoU值。
3.更新detection_class,只保留剩余的框中IoU小于阈值的框。
4.重复1~3步,直到detection_class中框的个数小于等于1。
代码实现:
非极大值抑制
def nms(detections_class,nms_thres=0.7):
#detection_class是一系列输入的框,形状为 n x 4,且已经是按照得分降序排序
max_detections = []
while np.shape(detections_class)[0]:
max_detections.append(np.expand_dims(detections_class[0],0)) #将首个框扩展第0维加入,形状为1 x 4
if len(detections_class) == 1:
break
#语法说明:
#因为bbox_iou是列表,但元素的类型是numpy数组,内容形式是[ 1x4的np数组,1x4的np数组,...,1x4的np数组]。
#因此取出最后一个元素就使用索引-1,便取出一个1x4的np数组
#因为上一步是将detections_class中第一个框追加到列表中,因此取最后一个元素就是刚刚取出的框
ious = bbox_iou(max_detections[-1][:,:4],detections_class[1:,:4])[0] #刚加入的框和剩余的所有框计算iou,detections_class从1开始取,第0个已经取走
detections_class = detections_class[1:][ious<nms_thres] #剩余的列表中,保留iou小于阈值的
if len(max_detections)==0:
return []
max_detections = np.concatenate(max_detections,axis=0)
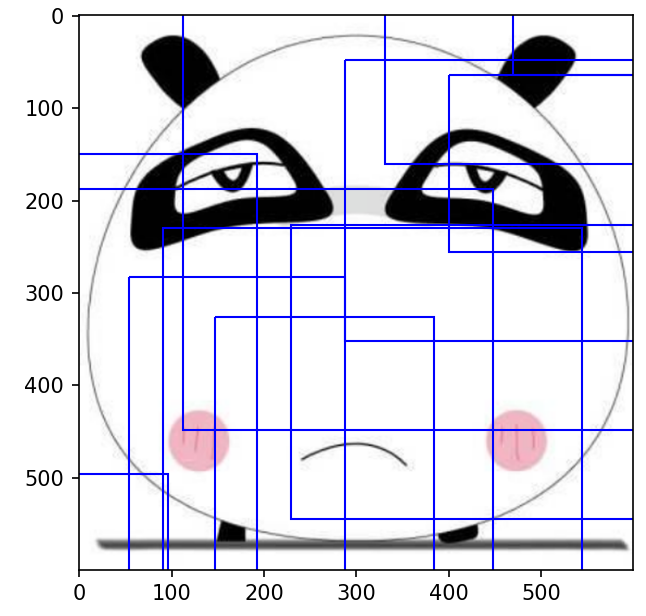
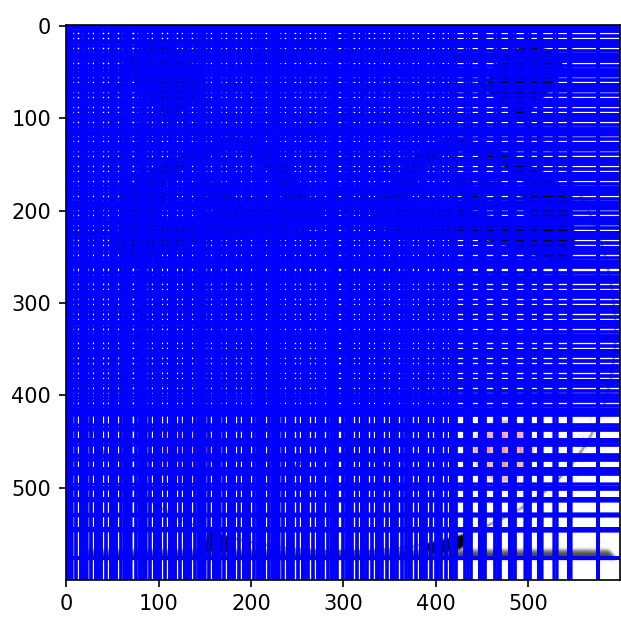
return max_detections非极大值抑制前,特征图中每个像素点生成先验框绘制在原图中如图所示:
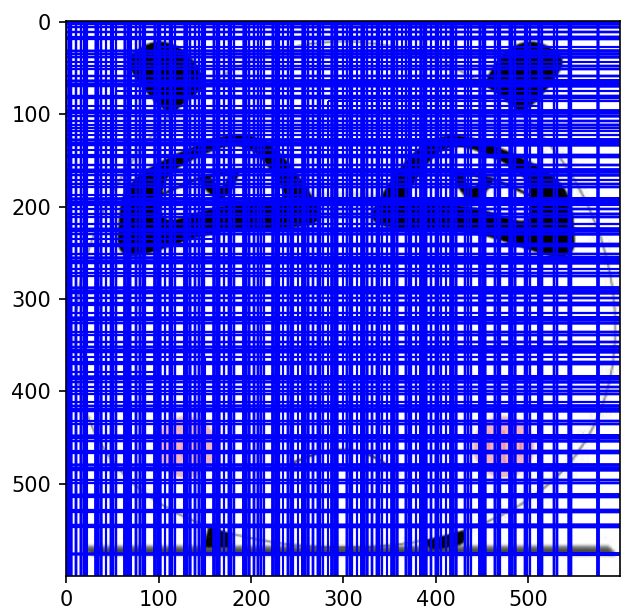
极性非极大值抑制之后如图所示,明显稀疏了许多。
对基础先验框修正过程
现有了基础先验框的信息12996 x 4(对应600x600图片上的坐标)和回归预测的偏移量信息BatchSize x 12996 x 4。
回归预测结果每个先验框保存的4个信息分别是先验框中心点x坐标偏移量,y坐标偏移量,宽度变化,高度变化,但是基础先验框的信息保存的是左下角xy坐标和右上角xy坐标,因此要统一。
首先将基础先验框转换为中心点坐标与宽高形式,然后再使用偏移量对其进行修正。
原论文中的公式计算方式为,先对中心点做平移,再对宽高做缩放,如下图所示:
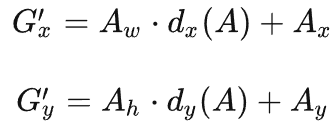
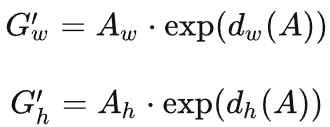
修正之后,再将建议框转换为左下坐标和右上坐标表示。
修正函数
#根据预测的偏移量修正基础先验框
def loc2bbox(src_bbox, loc):
if src_bbox.size()[0] == 0:
return torch.zeros((0, 4), dtype=loc.dtype)
#计算宽高,以及中心点xy坐标
src_width = torch.unsqueeze(src_bbox[:, 2] - src_bbox[:, 0], -1)
src_height = torch.unsqueeze(src_bbox[:, 3] - src_bbox[:, 1], -1)
src_ctr_x = torch.unsqueeze(src_bbox[:, 0], -1) + 0.5 * src_width
src_ctr_y = torch.unsqueeze(src_bbox[:, 1], -1) + 0.5 * src_height
#获得回归预测结果中的x,y变化,以及宽高变化
dx = loc[:, 0::4]
dy = loc[:, 1::4]
dw = loc[:, 2::4]
dh = loc[:, 3::4]
#原论文中的公式,调整中心点x,y以及宽高
ctr_x = dx * src_width + src_ctr_x
ctr_y = dy * src_height + src_ctr_y
w = torch.exp(dw) * src_width
h = torch.exp(dh) * src_height
#将调整后的信息,转换为左下角和右上角坐标形式
dst_bbox = torch.zeros_like(loc)
dst_bbox[:, 0::4] = ctr_x - 0.5 * w
dst_bbox[:, 1::4] = ctr_y - 0.5 * h
dst_bbox[:, 2::4] = ctr_x + 0.5 * w
dst_bbox[:, 3::4] = ctr_y + 0.5 * h
#返回后调整后的左下角和右上角
return dst_bbox建议框的筛选
获得了建议框之后,对建议框进行删选:
-
-
-
- 删除超出边界的建议框。
- 删除宽高小于最小值的建议框。
-
-
删除了无用的建议框后,根据分类预测的得分,选择得分top n的建议框进行非极大值抑制。
RoI Pooling层
到此为止,我们已经从Region Proposal Network中获得了Feature Map的建议框。
因为这些建议框的大小是不固定的,而分类器的卷积神经网络输入要求是固定尺寸。
RoI Pooling层的作用
将尺寸不一致的特征图变换为统一尺寸,且不破坏图像的原有信息。
Crop和Warp操作

如上图所示,crop是截取部分图片改变图片形状,warp则是将图片进行变形,crop破坏了图片的原有信息,warp破坏了图片的原有结构信息,无论是哪种方法都不可取。
RoI Pooling代码应用
RoI Pooling的初始化参数为:
-
-
-
- OutputSize:输出尺寸。
- spatial_scale:原图到特征图的放缩尺度。
-
-
RoI Pooling的输入为:
-
-
-
- Feature Map:特征图
- RoI:对应Feature Map坐标的建议框,格式为第一维表示建议框索引,第二维4个参数,表示左下坐标和右上坐标。
-
-
#----------------------------------------初始化RoIPooling----------------------------------------
self.roi = RoIPool((roi_size,roi_size),spatial_scale)
#----------------------------对RoIPooling输入数据进行处理-----------------------------------------------
rois = torch.flatten(rois,0,1)#在第0维和第1维之间平坦化
roi_indices=torch.flatten(roi_indices,0,1)
#zero_like生成相同形状的全0 array,img_size为原始图片尺寸,x为特征图,roi为原始图片的建议框坐标
rois_feature_map = torch.zeros_like(rois)
rois_feature_map[:, [0, 2]] = rois[:, [0, 2]] / img_size[1] * x.size()[3]
rois_feature_map[:, [1, 3]] = rois[:, [1, 3]] / img_size[0] * x.size()[2]
indices_and_rois = torch.cat( [roi_indices[:,None],rois_feature_map],dim=1 )
#第一列表示图像index,其余四列表示左下角和右上角坐标
#利用建议框对公用特征层进行截取
#RoI将不同尺寸的建议框映射到固定大小的特征图上
pool = self.roi(x,indices_and_rois)RoI Pooling原理
RoI Pooling主要过程
-
-
-
- 第一次量化对齐网格。
- 第二次量化给特征网格划分子区域。(要输出尺寸为多大就划分多少个子区域)
- 对每个子区域进行最大池化。
-
-
第一次量化
由于在上一阶段RPN阶段中,对bbox回归得到的是对应原图坐标的bbox坐标。若直接对应到特征图(除以缩放尺度),得到的坐标是一个浮点数,也就一位置坐标会在单元格之间。
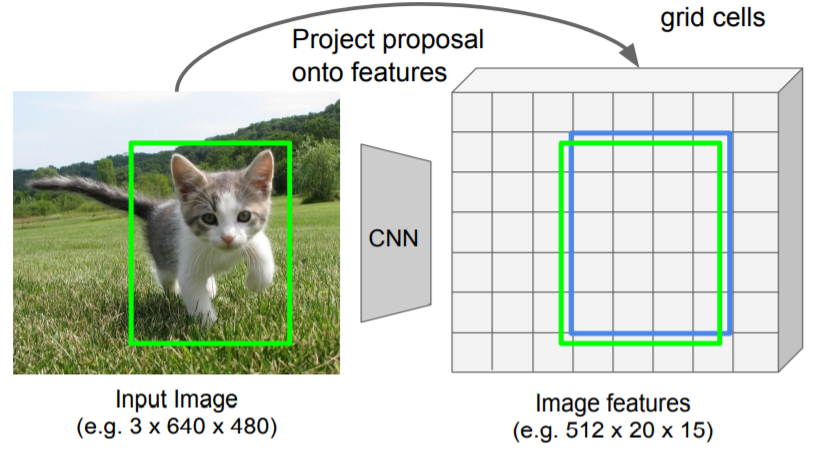
如上图所示,绿色框为原图bbox坐标对应特征图的bbox坐标,是一个浮点数,在单元格之间,蓝色为对齐后的bbox坐标。
第一次量化是将原图中对应特征图的bbox坐标对齐到特征图的网格点上。
第二次量化
假设想要统一的特征图尺寸为2x2,那么就要对bbox区域划分子网格,将其划分为2x2的子区域。
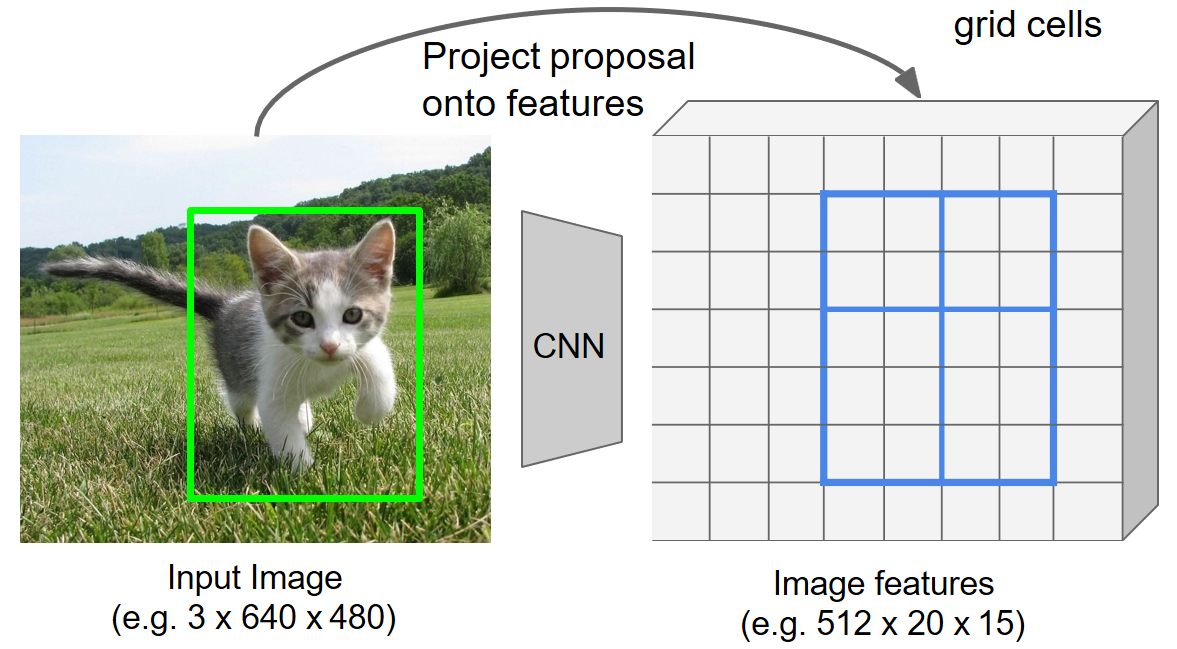
如上图所示,候选框为4x5的网格大小,输出要求的特征图大小为2x2,因此要将4x5的网格划分成2x2的子区域,X坐标方向4/2可以除得尽,但是Y轴方向5/2除不尽。
因此第二次量化采用向上和向下取整的方式,划分的子区域分别为2x2和2x3个网格大小。
最大池化操作
经过两次量化后,得到了子区域的划分结果。
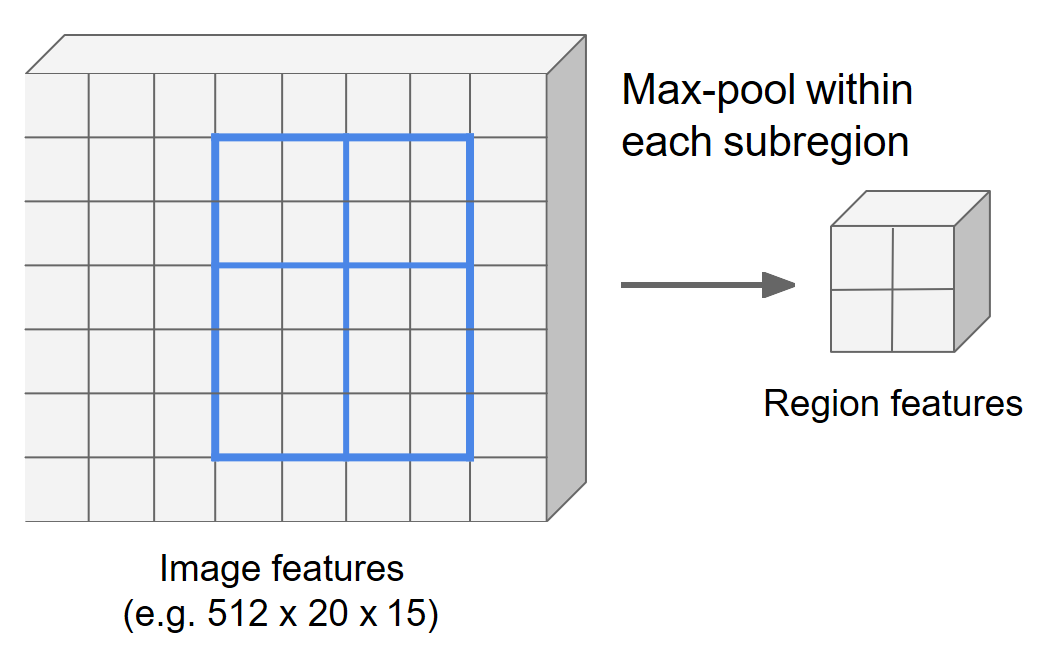
现在对每个子区域进行最大池化,最后就得到了2x2的特征区域。
RoIHead
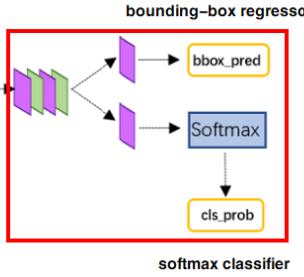
到此为止,我们已经获得了一系列尺寸统一的候选区域,Fast R-CNN中指定每个候选区的输出尺寸14 x 14,因此1024 x 38 x 38 的特征图经过RoI Pooling层,候选区输出形状为 1024 x 14 x 14。
现在需要对输入的候选区域进行卷积处理,再分别进行分类预测和回归预测。分类器也需要训练。
卷积处理
卷积模型依旧沿用ResNet50部分结构,顺序依次为ConvBlock(stride=2)和2个IdentityBlock(),最后接一个平均池化层(核尺寸为7,步长为7,填充为0)。
分类模型的输入为RoINumber x 1024 x 14 x 14,输出为RoINumber x 2048 x 1 x 1,然后将平铺为 RoINumber x 2048。
卷积处理结构
nn.Sequential(
ConvBlock(in_channels=1024,stride=2),
IdentityBlock(in_channels=2048),
IdentityBlock(in_channels=2048),
nn.AvgPool2d(kernel_size=7,stride=7,padding=0))分类
分类使用的是全连接层,全连接层的输出为类别总数n_class,得到的形状为 RoINumber x n_class,得到的就是每个建议框分别对应1000个类别的概率。
回归
回归预测也是用全连接层,输出为类别总数n_class * 4,表示建议框的调整参数,得到的形状为 RoINumber x (n_class * 4)。
RoIHead代码
import torch.nn as nn
from utils import *
from torchvision.ops import RoIPool
class Resnet50RoIHead(nn.Module):
def __init__(self,n_class,roi_size,spatial_scale,classifier):
#spatial_scale输入为1。
super(Resnet50RoIHead,self).__init__()
self.classifier = classifier
self.n_class = n_class
self.roi_size = roi_size
self.spatial_scalse = spatial_scale
self.cls_loc = nn.Linear(2048,n_class*4) #对建议框的调整参数
self.score = nn.Linear(2048,n_class) #建议框内是否包含物体以及物体种类
normal_init(self.cls_loc,0,0.001)
normal_init(self.score, 0, 0.01)
self.roi = RoIPool((roi_size,roi_size),spatial_scale)
#RegionProposalNetwork训练好了之后,得到得分高的建议框
def forward(self,x,rois,roi_indices,img_size):
#x:公用特征层图片
#roi_indices:建议框序号
n,_,_,_ = x.shape
#---------------RoI Pooling处理------------
if x.is_cuda:
roi_indices = roi_indices.cuda()
rois = rois.cuda()
rois = torch.flatten(rois,0,1)#在第0维和第1维之间平坦化
roi_indices=torch.flatten(roi_indices,0,1)
#zero_like生成相同形状的全0 array
rois_feature_map = torch.zeros_like(rois)
rois_feature_map[:, [0, 2]] = rois[:, [0, 2]] / img_size[1] * x.size()[3]
rois_feature_map[:, [1, 3]] = rois[:, [1, 3]] / img_size[0] * x.size()[2]
indices_and_rois = torch.cat( [roi_indices[:,None],rois_feature_map],dim=1 )
#第一列表示图像index,其余四列表示左下角和右上角坐标
#利用建议框对公用特征层进行截取
#RoI将不同尺寸的建议框映射到固定大小的特征图上
pool = self.roi(x,indices_and_rois) #输出为14x14大小
#卷积处理
fc7 = self.classifier(pool)#fc7形状为300x2048x1x1
fc7 = fc7.view(fc7.size(0),-1) #fc7形状为300x2048
#回归预测
roi_cls_locs = self.cls_loc(fc7)
roi_cls_locs = roi_cls_locs.view(n,-1,roi_cls_locs.size(1))
#分类预测
roi_scores = self.score(fc7)
roi_scores = roi_scores.view(n,-1,roi_scores.size(1))
return roi_cls_locs,roi_scores总结
一共有三个网络:主干网络,RegionProposalNetwork,RoIHead。其中主干网络是预训练完毕的,需要训练RegionProposalNetwork和RoIHead两个网络。
RegionProposalNetwork通过训练生成初步的建议框。
RoIHead通过训练,对建议框继续调整,最终给出坐标位置。
本文来自博客园,作者:Laplace蒜子,转载请注明原文链接:https://www.cnblogs.com/RedNoseBo/p/17590175.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号