
Pytorch-机器学习
线性模型
y = w * x + b
def model(t_u,w,b):
return w*t_u+bw为权重,b为偏置项,是可学习参数。
损失函数
预测值与真实值之间的误差,以均方损失误差MSE为例。
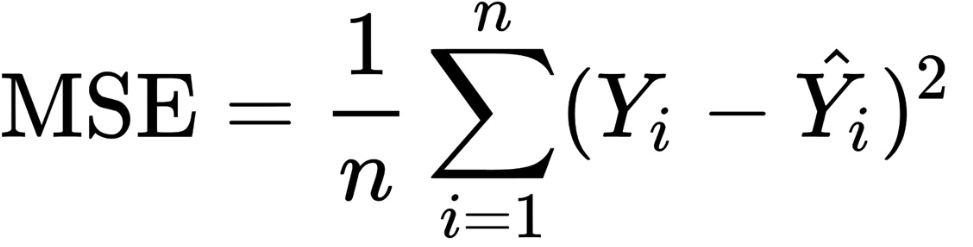
def loss_fn(t_p,t_c):
squared_diffs = (t_p-t_c)**2
return squared_diffs.mean()
线性模型预测
t_c = [0.5, 14.0, 15.0, 28.0, 11.0, 8.0, 3.0, -4.0, 6.0, 13.0, 21.0]
t_u = [35.7, 55.9, 58.2, 81.9, 56.3, 48.9, 33.9, 21.8, 48.4, 60.4, 68.4]
t_c = torch.tensor(t_c)
t_u = torch.tensor(t_u)#初始化参数
w = torch.ones(())
b = torch.zeros(())#模型预测
t_p = model(t_u,w,b)预测结果
tensor([35.7000, 55.9000, 58.2000, 81.9000, 56.3000, 48.9000, 33.9000, 21.8000,
48.4000, 60.4000, 68.4000])
#计算损失
loss = loss_fn(t_p,t_c)
losstensor(1763.8848)
梯度下降
基本形式
![]()
θ为参数,η为学习率
则对于参数w和b为:
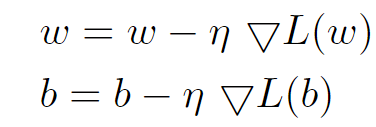
求梯度
损失函数对w和b的导数分别为:
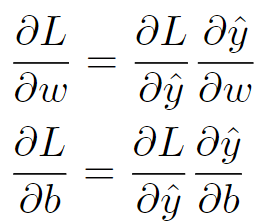
因此可以先求损失函数对y的导数,再分别求y对w和b的导数。
损失函数对y_hat的导数
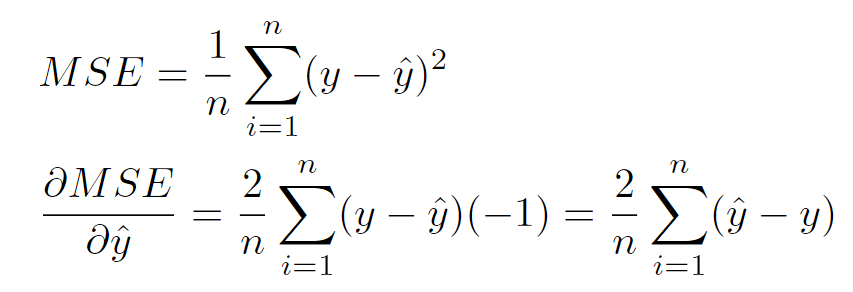
def dloss_fn(t_p,t_c):
dsq_diffs = 2 * (t_p - t_c) /t_p.size(0)
return dsq_diffsy_hat对w和b的导数
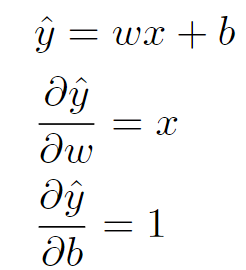
y_hat对w的导数
def dmodel_dw(t_u,w,b):
return t_uy_hat对b的导数
def dmodel_db(t_u,w,b):
return 1.0因此求梯度函数为
def grad_fn(t_u,t_c,t_p,w,b):
dloss_dtp = dloss_fn(t_p,t_c)
dloss_dw = dloss_dtp * dmodel_dw(t_u,w,b)
dloss_db = dloss_dtp * dmodel_db(t_u,w,b)
return torch.stack([ dloss_dw.sum(),dloss_db.sum() ])梯度下降求解函数为
def training_loop(n_epochs,learning_rate,params,t_u,t_c):
#n_epochs:周期数
#learning_rate:学习率
#params:参数w和参数b
#t_u:输入
#t_c:真实标签
for epoch in range(1,n_epochs+1):
w,b=params
t_p=model(t_u,w,b)
loss = loss_fn(t_p,t_c)
grad =grad_fn(t_u,t_c,t_p,w,b)
params = params - learning_rate * grad
print('Epoch %d, Loss %f' %(epoch,float(loss)))
return paramstraining_loop(
n_epochs=100,
learning_rate=1e-4,
params=torch.tensor([1.0,0.0]),
t_u = t_u,
t_c = t_c
)...
Epoch 97, Loss 29.025410
Epoch 98, Loss 29.024492
Epoch 99, Loss 29.023582
Epoch 100, Loss 29.022667
tensor([ 0.2327, -0.0438])
正则化处理
对输入进行正则化
t_un = 0.1*t_uparams=training_loop(
n_epochs=5000,
learning_rate=1e-2,
params=torch.tensor([1.0,0.0]),
t_u = t_un,
t_c = t_c
)...
Epoch 4996, Loss 2.927648
Epoch 4997, Loss 2.927647
Epoch 4998, Loss 2.927647
Epoch 4999, Loss 2.927647
Epoch 5000, Loss 2.927648
可视化
from matplotlib import pyplot as plt
t_p = model(t_un,*params) #星号表示解包一个tuple,将其每个元素一一对应传入到函数
fig = plt.figure(dpi=100)
plt.xlabel("Temperature (°Fahrenheit)")
plt.ylabel("Temperature (°Celsius)")
plt.plot(t_u.numpy(),t_p.detach().numpy()) #detach将其从计算图中分离出来,虽然指向原来的内存,但是不会更新
plt.plot(t_u.numpy(),t_c.numpy(),'o')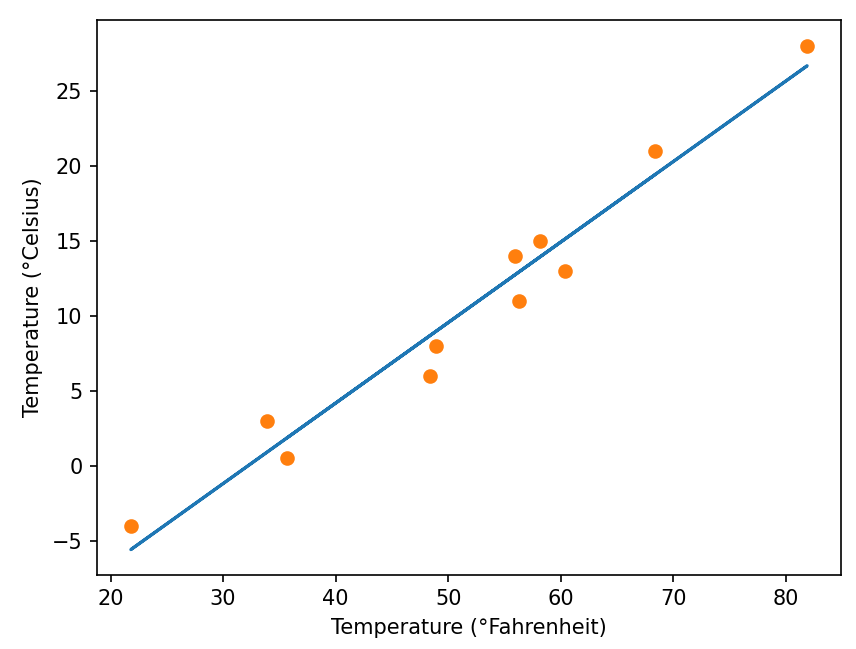
自动计算梯度
pytorch在定义tensor时,可以将requires_grad设置为True,表示追踪对该张量的所有操作,保存梯度。设置为False表示不保存梯度。初始梯度为0。
反向传播:使用tensor的backward()函数,会从该tensor向自己的祖先节点反向更新路径上requires_grad为True的tensor的梯度。是一个累加的过程,调用两次则梯度会叠加两次。
梯度属性:tensor.grad,可以使用tensor.grad is not None判断梯度不为空。
梯度清空:使用tensor.grad.zero_()来清空梯度
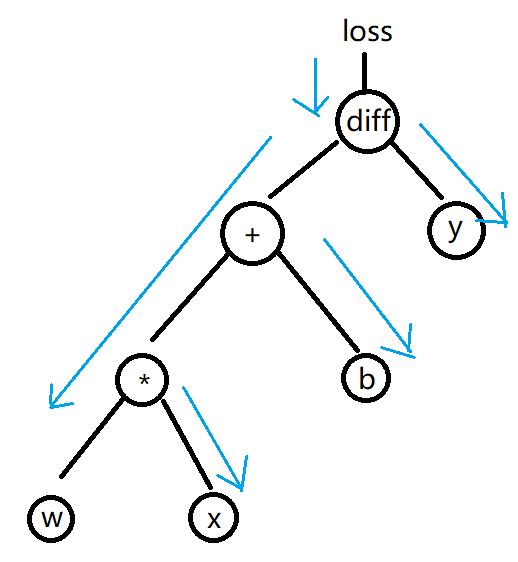
def training_loop(n_epochs,learning_rate,params,t_u,t_c):
for epoch in range(1,n_epochs+1):
if params.grad is not None:
params.grad.zero_()
t_p = model(t_u,*params)
loss = loss_fn(t_p,t_c)
loss.backward()
with torch.no_grad(): #创建不保存梯度的上下文环境,防止创建的计算题干扰
params-=learning_rate * params.grad
if epoch%500==0:
print('Epoch %d, Loss %f' % (epoch, float(loss)))
return params
training_loop(
n_epochs=5000,
learning_rate=1e-2,
params=torch.tensor([1.0,0.0],requires_grad=True),
t_u=t_un,
t_c=t_c
)...
Epoch 3500, Loss 2.927830
Epoch 4000, Loss 2.927679
Epoch 4500, Loss 2.927652
Epoch 5000, Loss 2.927647
tensor([ 5.3671, -17.3012], requires_grad=True)
优化器
可以将参数和学习率放到优化器中,进行训练
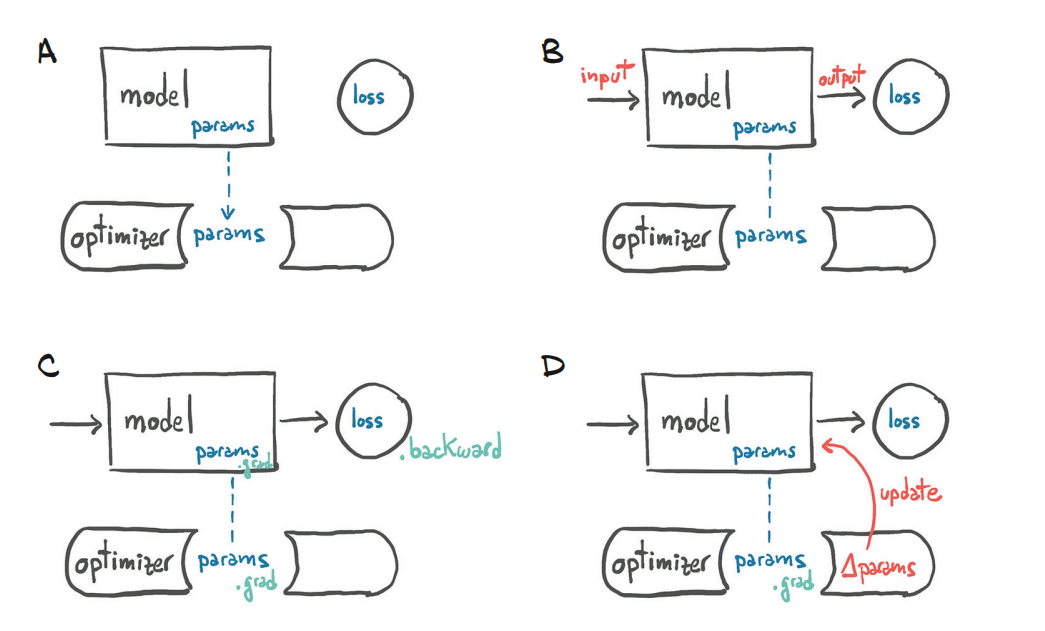
导入并查看优化器
import torch.optim as optim
dir(optim)['ASGD', 'Adadelta', 'Adagrad', 'Adam', 'AdamW', 'Adamax', 'LBFGS', 'NAdam', 'Optimizer', 'RAdam', 'RMSprop', 'Rprop', 'SGD', 'SparseAdam', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__path__', '__spec__', '_functional', '_multi_tensor', 'lr_scheduler', 'swa_utils']
定义优化器,以SGD为例
注意:梯度通过loss.backward()计算,梯度更行参数通过优化器的step()来更新。
params = torch.tensor([1.0,0.0],requires_grad=True)
learning_rate = 1e-5
optimizer = optim.SGD([params],lr=learning_rate)
#optimizer = optim.Adam([params],lr=learning_rate)
def training_loop(n_epochs,optimizer,params,t_u,t_c):
for epoch in range(1,n_epochs+1):
t_p = model(t_u,*params)
loss = loss_fn(t_p,t_c)
optimizer.zero_grad() #将上一次梯度记录清空
loss.backward()
optimizer.step()#优化器寻找params.grad并更行params
#优化器只负责通过梯度下降优化,不负责产生梯度,梯度时通过loss.backward()来计算
if epoch%500==0:
print('Epoch %d, Loss %f' % (epoch, float(loss)))
return params
分割训练集和验证集
torch.randperm(n)函数用于产生从0到n的序列,并且乱序。
n_samples = t_u.shape[0]
n_val = int(0.2 * n_samples)
shuffled_indices = torch.randperm(n_samples)#将0~n_samples随机打乱后获得数字序列
train_indices = shuffled_indices[:-n_val]#从0到倒数第n_val-1个
val_indices = shuffled_indices[-n_val:]#从倒数第n_val个到最后
train_t_u = t_u[train_indices]
train_t_c = t_c[train_indices]
val_t_u = t_u[val_indices]
val_t_c = t_c[val_indices]
train_t_un = 0.1 * train_t_u
val_t_un = 0.1 * val_t_u
在训练集上训练,在验证集上独立测试
def training_loop(n_epochs,optimizer,params,train_t_u,val_t_u,train_t_c,val_t_c):
for epoch in range(1,n_epochs+1):
train_t_p = model(train_t_u,*params)
train_loss = loss_fn(train_t_p,train_t_c)
val_t_p = model(val_t_u,*params)
val_loss = loss_fn(val_t_p,val_t_c)
optimizer.zero_grad()
train_loss.backward() #若再调用val_loss的反向传递,会导致param上的梯度累加
optimizer.step()
if epoch <= 3 or epoch%500==0:
print(f"Epoch {epoch}, Training loss {train_loss.item():.4f},"
f" Validation loss {val_loss.item():.4f}")
return paramsparams = torch.tensor([1.0,0.0],requires_grad=True)
learning_rate=1e-2
optimizer = optim.SGD([params],lr=learning_rate)
training_loop(
n_epochs=3000,
optimizer=optimizer,
params=params,
train_t_u=train_t_un,
val_t_u=val_t_un,
train_t_c=train_t_c,
val_t_c=val_t_c
)...
Epoch 2000, Training loss 3.1950, Validation loss 2.2072
Epoch 2500, Training loss 3.1878, Validation loss 2.2028
Epoch 3000, Training loss 3.1869, Validation loss 2.2012
上述中,计算验证集时也产生了计算图,但是没有调用val_loss的反向传播,因此不会影响参数的更行
进一步优化,可以在计算验证集的时候,取消所有参数的梯度,节省计算资源
有两种方式取消梯度
with torch.no_grad()表示创建没有梯度的上下文,在此上下文内计算的所有参数都不会保存梯度。
with torch.set_grad_enabled( True or False )表示接下来的上下文是否启用梯度。
def training_loop(n_epochs,optimizer,params,train_t_u,val_t_u,train_t_c,val_t_c):
for epoch in range(1,n_epochs+1):
train_t_p = model(train_t_u,*params)
train_loss = loss_fn(train_t_p,train_t_c)
with torch.no_grad():
#no_grad表示禁用梯度计算。在此代码块内计算不会计算梯度,即使requires_grad为True,在此模式下也会变为False
#若不使用,则在验证集上验证的时候也会计算梯度。浪费资源
val_t_p = model(val_t_u,*params)
val_loss = loss_fn(val_t_p,val_t_c)
assert val_loss.requires_grad == False
optimizer.zero_grad()
train_loss.backward()
optimizer.step()
return params
def calc_forward(t_u,t_c,is_train):
with torch.set_grad_enabled(is_train):
#set_grad_enabled根据其参数模式来启用或禁用梯度
t_p = model(t_u,*params)
loss = loss_fn(t_p,t_c)
return loss本文来自博客园,作者:Laplace蒜子,转载请注明原文链接:https://www.cnblogs.com/RedNoseBo/p/17572769.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号