

Pytorch常用函数
常用函数
随机数
torch.randn(batch,channels,rows,columns)
说明:
rows:行
colums:列
channels:通道个数
batch:生成的个数
生成batch个具有channels个通道的rows行columns列的tensor
求平均
tensor.mean(-3):表示倒数第3维度求平均
tensor.unsqueeze(-1):在最后增加一个维度。
相乘
torch.Size([3, 1, 1])与torch.Size([3, 5, 5])的相乘,相当于第一维度的数分别乘以对应通道的矩阵
a=
[[1., 2., 3.],
[4., 5., 6.],
[7., 8., 9.]],
[[1., 2., 3.],
[4., 5., 6.],
[7., 8., 9.]],
[[1., 2., 3.],
[4., 5., 6.],
[7., 8., 9.]]
b=
[[0.0000]],
[[0.2000]],
[[0.5000]]
结果为:
[[0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000],
[0.0000, 0.0000, 0.0000]],
[[0.2000, 0.4000, 0.6000],
[0.8000, 1.0000, 1.2000],
[1.4000, 1.6000, 1.8000]],
[[0.5000, 1.0000, 1.5000],
[2.0000, 2.5000, 3.0000],
[3.5000, 4.0000, 4.5000]]
求和
tensor.sum(dimension)
按照dimension维求和,-3表示从倒数第3行。
若一个rgb图像按照-3求和,则是合并所有通道,得到一个2维矩阵
命名
定义名字
torch.tensor([],names=[''])
在names中写入各个维度的名字
重定义名字
tensor.refine_names(...,'name1','name2','name3',...)
使用refine_names函数对tensor重命名
获取名字
tensor.names
('name1','name2','name3')是一个tuple,是tensor的属性
名字对齐
tensor.align_as(goal_tensor)
根据目标goal_tensor,将tensor的名字与其对齐
对齐前两个tensor为:
weights_withname:
tensor([0.0000, 0.2000, 0.5000], names=('channels',))
img_named:
tensor([[[1., 2., 3.],
[4., 5., 6.],
[7., 8., 9.]],
[[1., 2., 3.],
[4., 5., 6.],
[7., 8., 9.]],
[[1., 2., 3.],
[4., 5., 6.],
[7., 8., 9.]]], names=('channels', 'rows', 'columns'))
对齐后:
weights_aligned:
tensor([[[0.0000]],
[[0.2000]],
[[0.5000]]], names=('channels', 'rows', 'columns'))
根据名字求和
tensor.sum('name')
gray_named = (img_named*weights_aligned).sum('channels')
gray_named:
tensor([[0.7000, 1.4000, 2.1000],
[2.8000, 3.5000, 4.2000],
[4.9000, 5.6000, 6.3000]], names=('rows', 'columns'))
删除名字
tensor.rename(None)
执行之后会清空名字。
数据类型
tensor默认数据类型是32位浮点类型,神经网络中的计算通常也是以此类型计算。
CPU中不存在16位浮点类型,但是GPU中存在,可以减少占用空间,但会损失少许精度。
指定类型创建tensor
方式一
torch.ones(10,2,dtype=torch.double)
torch.rand(5,dtype=torch.double)
方式二
torch.ones(10,2).double
torch.rand(5).short()
类型转换
tensor.to(torch.type)
例如
tensor.to(torch.short)
转置
方式一
torch.transpose(tensor,dim1,dim2)
方式二
tensor.transpose(dim1,dim2)
将dim1和dim2交换
原本形状:torch.Size([3, 5, 4])
转置第0维和第2维度后的形状:torch.Size([4, 5, 3])
方式三
tensor.t()
tensor的存储形式
在内存上都是一维存储,tensor通过索引,不同的步长来获取想要的视图形式。多个张量可以索引到同一个存储上。
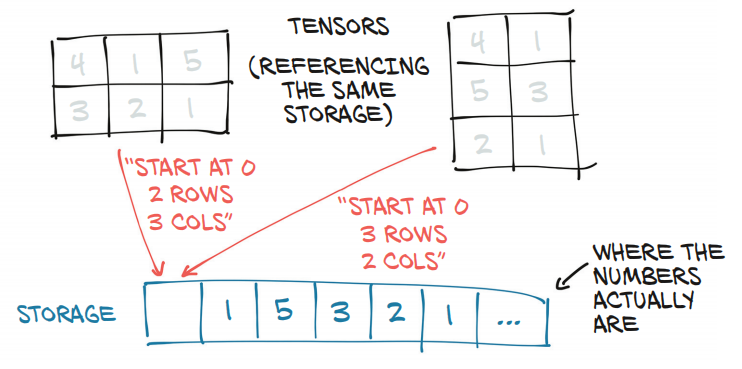
获取存储形式
可以通过tensor.storage()获取到内存上的存储形式。
也可以改变内存上的存储的值,从而改变tensor
points = torch.tensor([[4.0,1],[5.0,3],[2,1]])
points_storage = points.storage()
points_storage[0]=999
points数据清空
tensor.zero_()
获取相对于起始地址的偏移量
tensor.storage_offset()
points = torch.tensor([[4.0,1],[5.0,3],[2,1]])
for item in points:
print(item.storage_offset())输出为0 2 4
获取对象存储的唯一id
id()
points = torch.tensor([[4.0,1],[5.0,3],[2,1]])
points_t=points.t()
print(id(points.storage()))
print(id(points_t.storage()))输出为:
2083071506696
2083071506696
可以发现tensor和其转置都是公用同一个存储。
判断是否连续存储
tensor.is_contiguous()
points = torch.tensor([[4.0,1],[5.0,3],[2,1]])
points.is_contiguous()
points_t = points.t()
points_t.is_contiguous()转置矩阵是不连续的,输出为False,因为转置矩阵的存储是原来的矩阵存储,但是步长不一样。
GPU运算
传送到GPU
方式1
在创建变量时候,指定device为cuda即可
points_gpu = torch.tensor([[4.0,1],[5.0,3],[2,1]],device='cuda')方式2
tensor.to(device='cuda')
方式3
tensor.cuda
指定GPU
device='cuda:number'
传回cpu
gpu_tensor.cpu()
tensor与numpy互相转换
tensor->numpy:tensor.numpy()
numpy->tensor:torch.from_numpy( ndarray )
tensor保存与加载
一般形式存储
方式1
torch.save( tensor, '...xxx.t' )
torch.load('...xxx.t')
方式2
with open('xxx.t','wb') as f:
torch.save(tensor,f)
with open('xxx.t','rb') as f:
torch.load(f)
以h5py形式存储
h5py可以将数据存储到自己的文件中,然后在自己的文件中使用key值获取存储的数据。
导入库
import h5py
存储文件中,以对应key值为,'key'
f = h5py.File('xxx.hdf5','w')
dset = f.create_dataset('key',data=ndarray())
f.close()
读取文件,读取值'key'对应的数据
f = h5py.File('xxx.hdf5'.'r')
dset = f['key']
注意,在读取的时候不能关闭f
本文来自博客园,作者:Laplace蒜子,转载请注明原文链接:https://www.cnblogs.com/RedNoseBo/p/17565437.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号