

推荐系统
什么是推荐系统
根据用户搜索的内容,向用户推荐item。
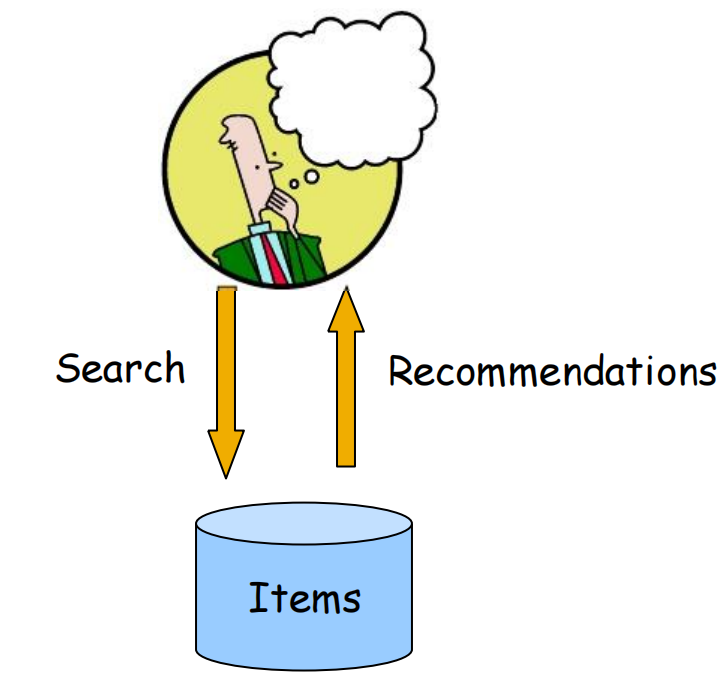
在一个页面中,能够用于做推荐,做展示的部分非常有限。
网络使得产品信息传播的成本几乎为0。
长尾效应
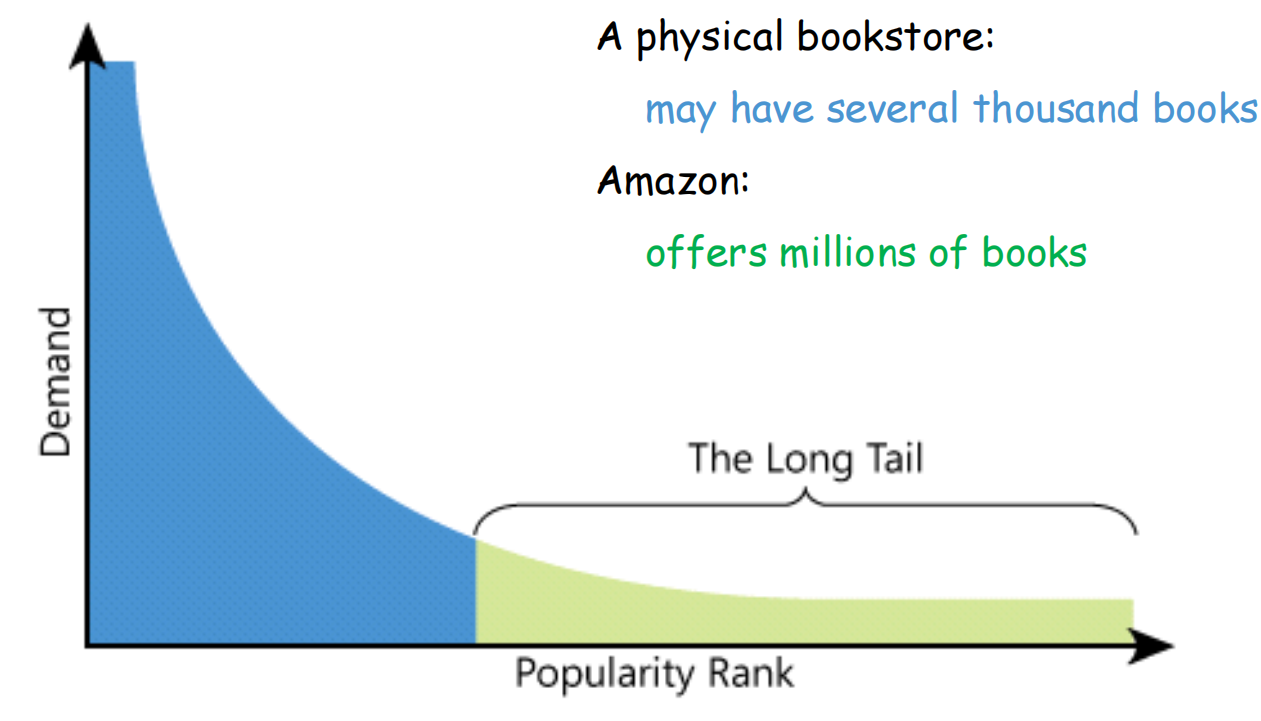
只有少数几个热度非常高的item在前面部分,占据了绝大多数关注量。而后面大量的非热门item几乎没多少关注度。
推荐系统类型
手工策划进行推荐:列出爱好列表
简单统计:如统计top10受欢迎的产品
为用户量身定制:根据用户的爱好,独特的风格进行推荐。
形式化模型
设X为用户集合,S为Item集合。R是评分集合。
效用函数u:X 叉乘 S -> R
也就是不同用户对不同Item的评分。
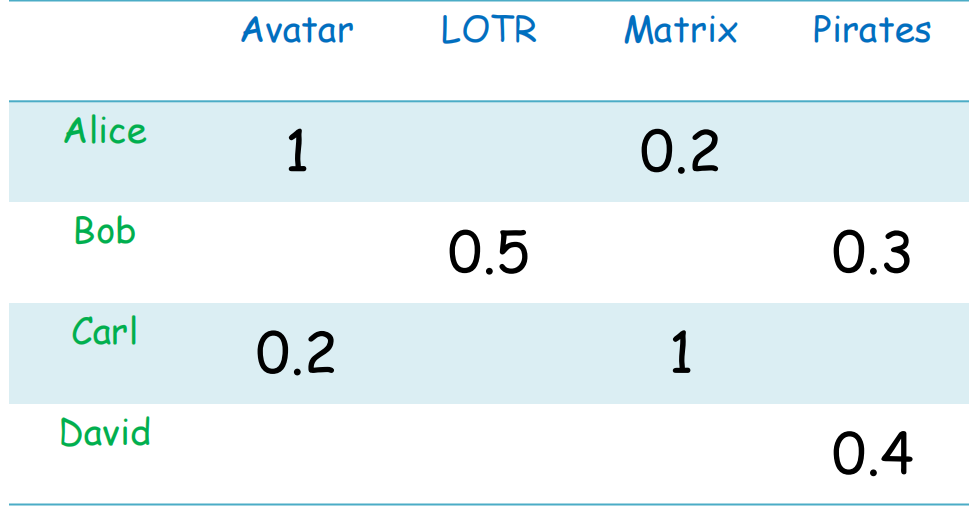
所需解决的问题
如何收集矩阵中那些已知的评分
显式的:做问卷调查。但是不实际,用户不希望被打扰。
隐式的:从用户的动作中学习评分。
如何从已知的评分中推断出未知评分
推断方式
基于内容
协同过滤
基于潜在因素
存在的问题
稀疏问题:效用矩阵U通常是稀疏矩阵,因为很少有用户用过所有产品或看过所有电影,通常每个用户只有关于少数几个Item的评分。
冷启动问题:新的Item没有评分,新的用户没有历史。
如何评价推断方法的好与坏
比较
将预测的值与已知的值比较,如使用平方根误差。rxi是x对i的真实评价,r*xi是x对i的预测评价。
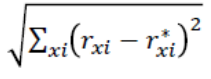
存在的主要问题
Prediction diversity问题:比如看了一个电影,然后只推荐这个系列的电影。
Prediction content问题:不同时间段内,兴趣不同,可能推荐的是前段时间所喜欢的Item。
其他0/1模型
覆盖范围:系统可以进行预测的用item/user的数量。
精度:预测的准确度
接受者操作特征曲线(ROC):在假阳性和假阴性之间做tradeoff
与检索系统的区别
检索系统强调的是query,根据用户的query匹配doc。推荐系统强调的是push,根据用户特征push匹配的item。检索系统和推荐系统都要考虑用户方和供应方的公平性。
基于内容的推荐
主要思想
根据用户x先前给予高评分Item,推荐与之相似的Item。
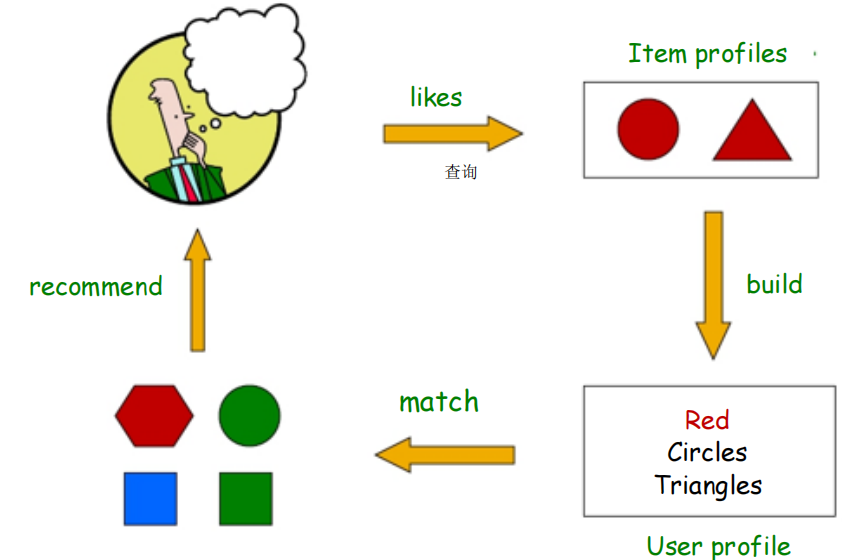
可能对红色感兴趣或者对有角度的也感兴趣
Item Profiles
为每一个item创建一个item profile,profile可以是表示特征的向量。
如电影的作者,标题,演员,导演。
如文本的重要词汇
TF-IDF获取重要的特征
fij表示特征i出现在文档j中的频率
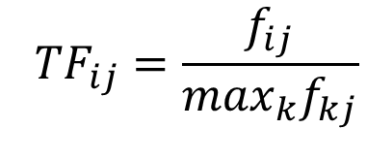
TFij描述的是特征i出现在文档j中的频率,相对于那个出现频率最高的特征出现频率的比例。
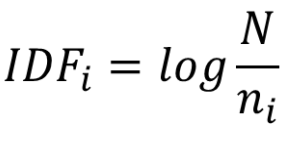
ni是提到特征i的文档的个数
N是总的文档个数
如果ni很小,也就是特征i仅仅出现在少数文档中,说明这个信息很重要,若ni非常大,几乎出现在所有文档中,则说明这种信息都烂大街了。
TF-IDF得分:
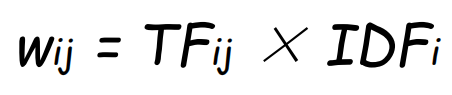
用户profile
用户profile概率
使用weighted average,也就是求所有item评分的均值,每个评分在减去这个均值。
如用户对TC的评分是:3 5
用户对TR的评分是:1 2 4
那么所有item的平均评分是:(1+2+3+4+5)/5 = 3
那么最终权重后的评分分别为
TC:0 2
TR:-1 -2/3 1
评分为负数说明用户可能不喜欢。
余弦相似度计算user profile和item profile的相似度
给定用户profilex和item profile
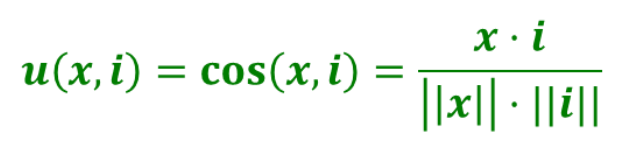
基于内容的方式好处
与其他用户的行为无关
可以推荐满足用户独特行为的item
可以推荐新的或者非流行的item
具有可解释性。
基于内容的方式坏处
难以寻找合适的特征
缺少多样性,只会推荐符合用户特征的商品,如喜欢臭豆腐,只会推荐臭豆腐相关产品
协同过滤
基于相似用户
基本思想
发现与用户x具有相似兴趣的用户,根据其他与用户兴趣,推荐其他用户买过但是用户x没有买过的item。
度量方式
Jaccard相似度量
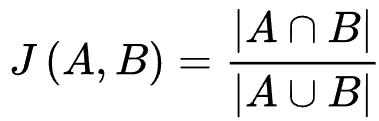
交集和并集的比例。
问题是忽略了评分的值。
余弦相似度
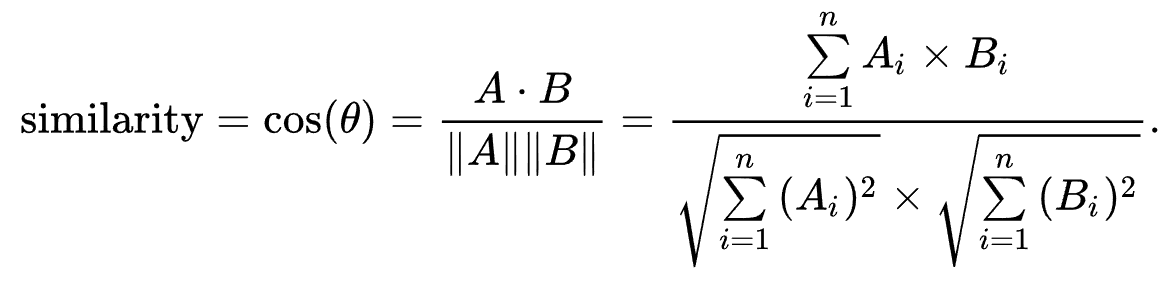
问题是将缺失的评分视为了负样本。
Pearson相关度系数
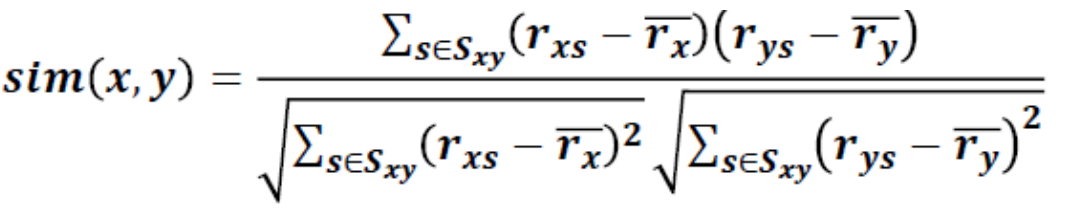
与余弦相似度类似,但是将每个样本做了归一化,也就是减去平均值。
案例

直观上,A和B更相似,因为相同的电影的评分接近,A和C不相似,相同的电影评分相反。
使用Jaccard相似度
A和B的相似度为1/5。A和C的相似度为2/4。与直观相反。
使用余弦相似度
把没有看过的电影评分设置为0,作为一个向量,做余弦相似度。
得到A和B的相似度为0.386,A和C的相似度为0.322。发现差别并不大。
使用Pearson相似度
A和B的相似度为0.092,A和C的相似度为-0.559。可以发现就可以区分开了。
评分预测
设rx为用户x的评分,N为与用户x相似的k个用户集合,都是对Item i的评分。
根据N集合预测用户x对item i评分。
平均值
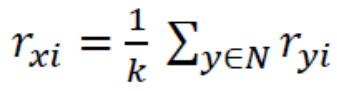
用其他用户对item i评分均值作为x对i评分
相似权重
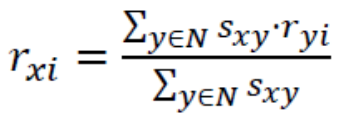
对每个相似于x用户的评分,根据相似度进行加权,权重为sxy,表示用户x与用户y的相似度。
分母为所有权重之和。
基于相似Item
基本思想
对于Item i,找到与item i 相似的item。
基于相似的item对item i评分进行预测。
相似度量和预测方式与user-user一致。
度量
与user-user一致
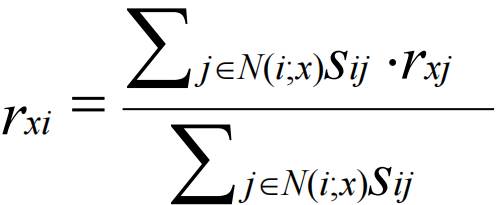
如Pearson相似度,这里sij表示item i与item j的相似度。
N表示相似于item i的item集合。rxi表示用户x对Item i的评分。
案例
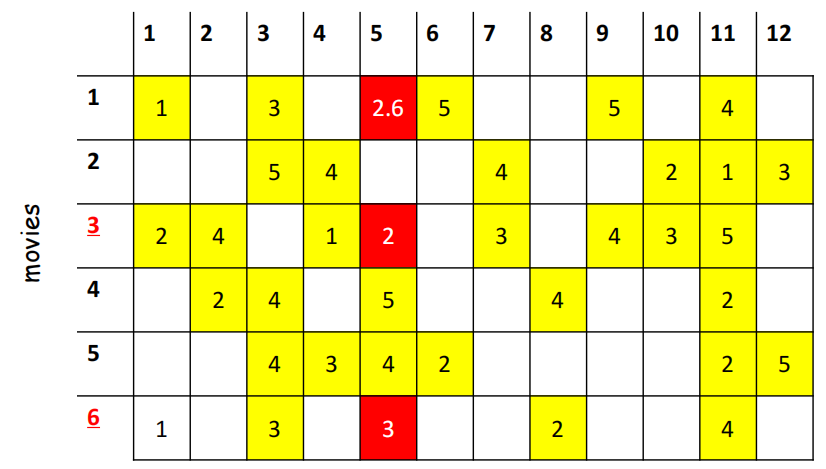
要预测user5对item 1的评分。
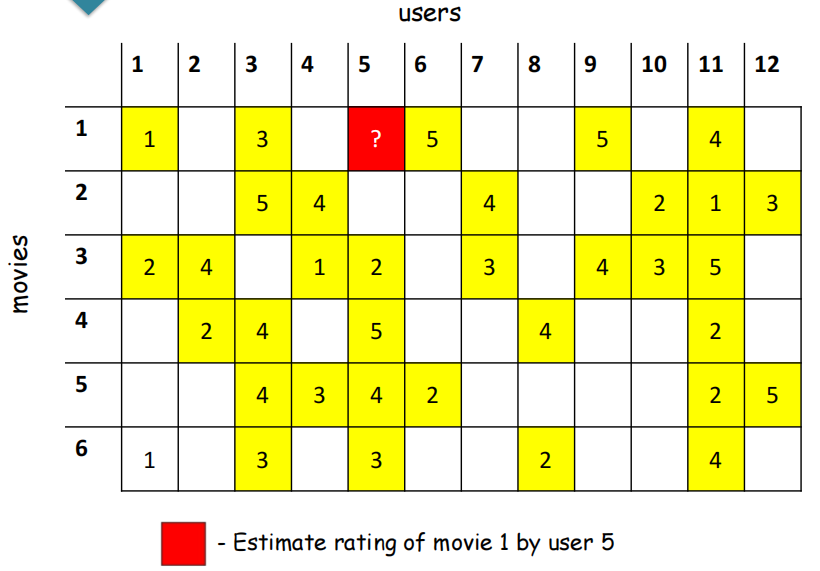
计算每个item与item i的相似度,使用Pearson相关系数,空白位置填0。
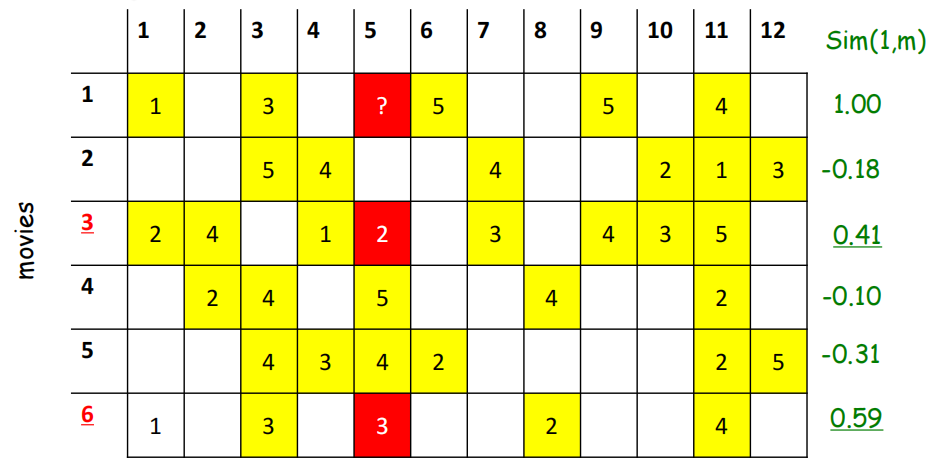
可以发现Item3 和 Item6于 Item1相似。
使用相似权重对Item1的评分进行预测。
s13=0.41,s16=0.59
r15 = (0.41*2 + 0.59*3)/(0.41+0.59)=2.6
协同过滤的优点
可以用于任意Item或任意user
协同过滤的缺点
存在冷启动问题,初始user rating基本都是0。
通常矩阵非常稀疏
难以为没有历史评价的用户进行推荐。
更偏向于推荐非常流行的Item
混合方法
将多种不同的推荐方法结合起来预测。
将一个baseline方法和协同过滤综合起来。
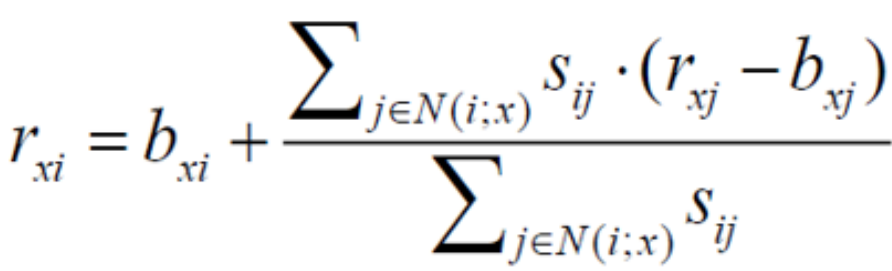
bxi为baseline。
bxi=μ+bx+bi
μ:所有电影的平均评分。
bx:用户x对所有电影评分平均数 与 整个电影评分的平均偏离程度,也就是 average(rating of user x ) - μ 。
bi:用户x对电影i的评分 与 所有电影平均评分的差。
隐因子模型
Bellkor 推荐系统模型
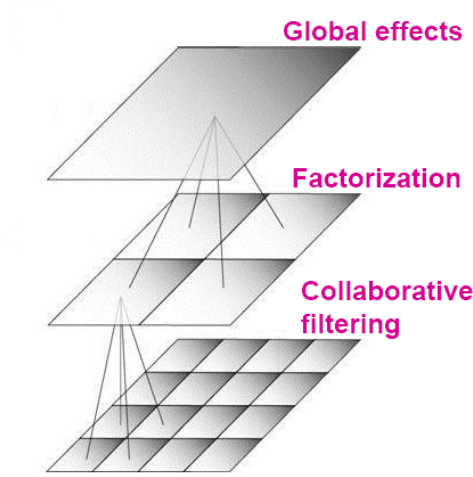
全局:用户/电影的总体偏离程度。就如上所说的baseline。
Factorization:分解,处理区域的影响。
协同过滤:抽取局部模式
全局影响
设平均电影评分为:3.7 stars。
Sixth Sense高于平均评分0.5分。
Joe对电影的平均评分低于电影总平均评分0.2分。
综上所述,μ=3.7,bi=0.5,bx=-0.2。
那么bxi=3.7+0.5-0.2=4
那么根据baseline,Joe将会对Sixth Sense打4分。
局部建模
假如Joe不喜欢和Sign相关的电影
那么Joe将对给Sixth Sense打分3.8分。
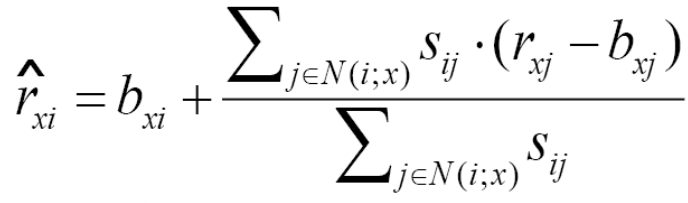
存在的问题是
对于相似度的度量过于随意。
成对的相似性忽略了用户之间相互依赖性
采取加权平均可能受到限制。
机器学习方式学习相似度权重
标签的预测值,wij表示i与j的相似度权重。
![]()
损失函数
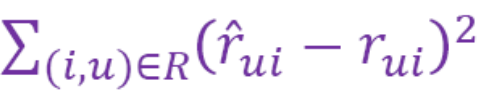
目标是学习到最优的权重wij,于是有优化函数:
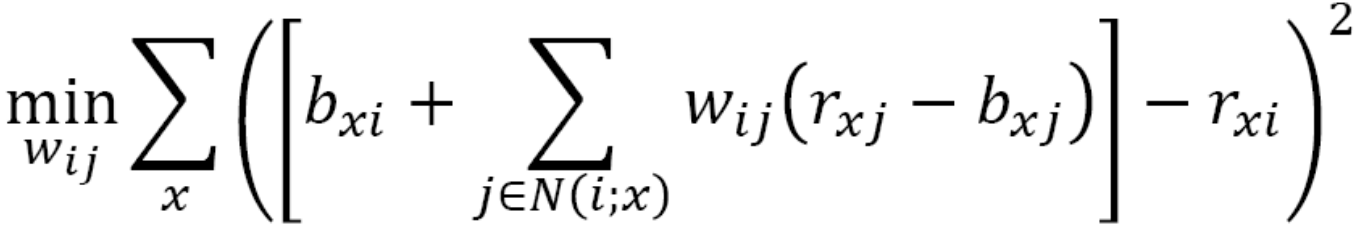
对权重wij求导的到:
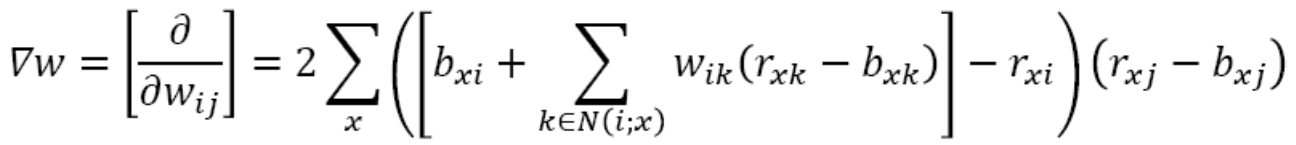
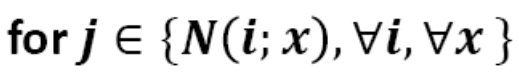
wnew=wold-η▽wold
优化函数已经知道了,接下来需要找到i的邻域中所有的j
隐因子模型
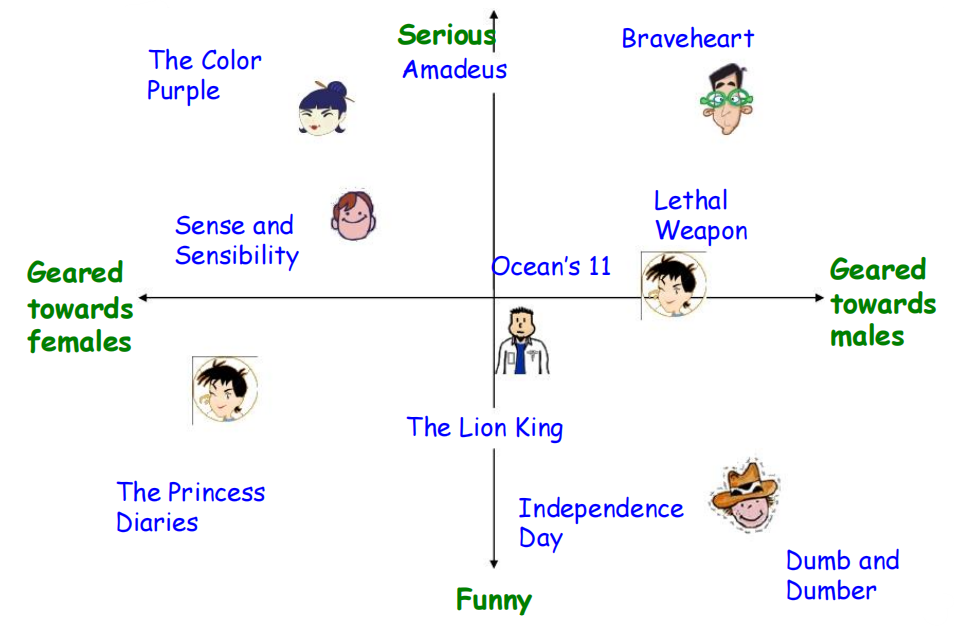
横坐标:男女性向
竖坐标:Serious到Funny。
SVD分解
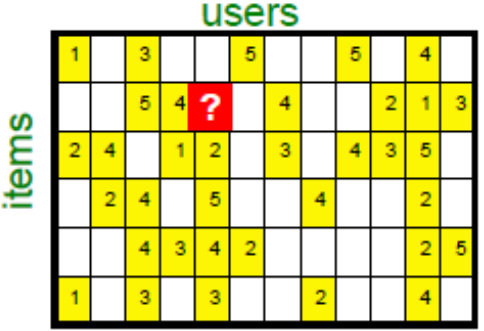
对users-item矩阵进行SVD分解。矩阵中任意一个未知数都可以通过两个矩阵相乘得到。
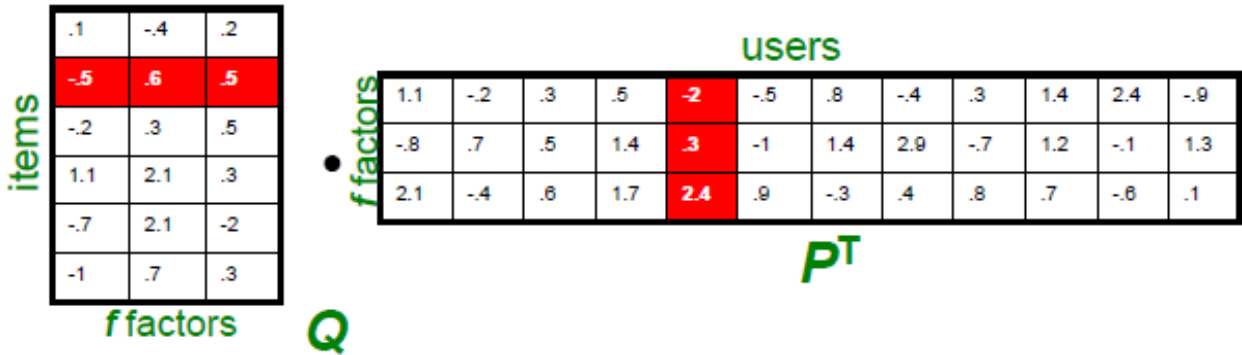
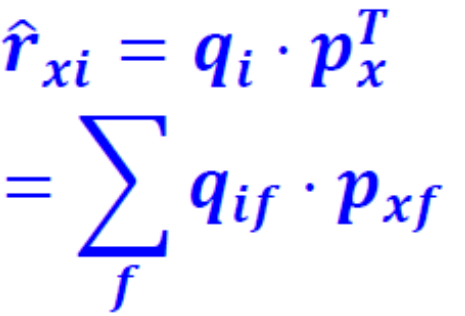
然后最小化误差
![]()
![]()
学习SVD所需参数
但是存在的问题是如果数据项缺失的话无法定义SVD
于是可以使用机器学习方式学习到缺失的项。
损失函数为R中真实的值 与 使用学习到的q和p进行点积得到预测结果的差。
![]()
![]()
因为P和Q矩阵中元素太多了,也就是需要优化的参数过多,为了防止过拟合,要加入正则项。
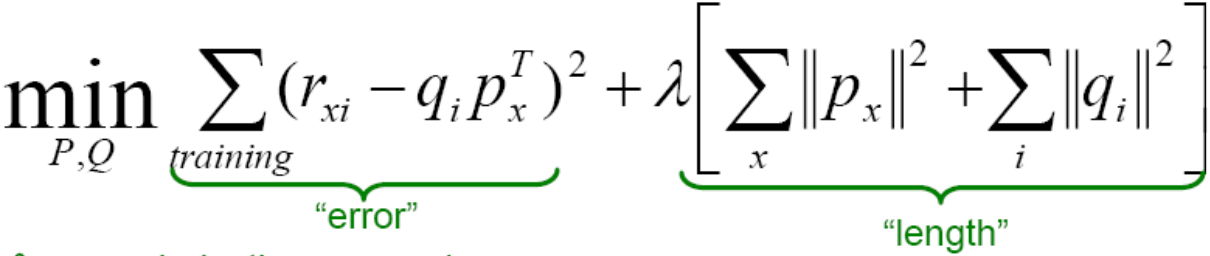
第一项若增大,也就是qipTx减小,那么第二项也就减小。
第一项若减小,也就是qipTx增大,那么第二项会增大。
于是就是要找一个trade off
![]()
P的梯度也是如此计算
梯度下降
梯度下降:每次计算所有样本。
随机梯度下降:每次随机选取一个样本。
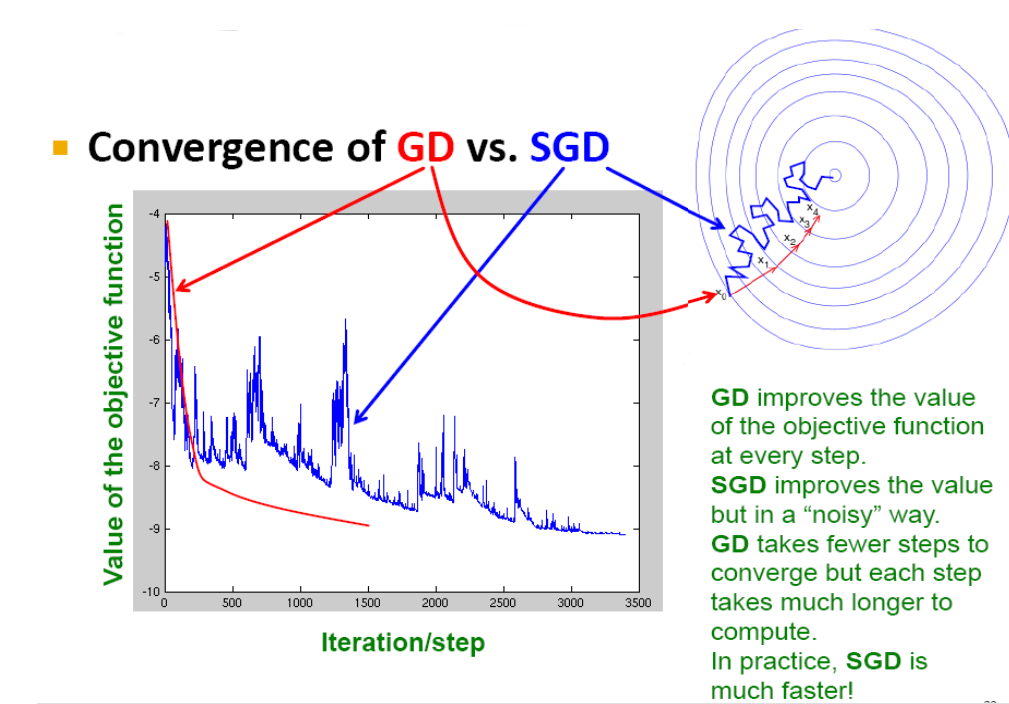
但是实验结果表明,使用随机梯度下降综合性能上优于普通梯度下降。
Baseline预测
从SVD分解上看,User-Movie的交互信息反映了用户与电影的匹配程度。
于是可以在Baseline基础上加加上User-Movie的交互。
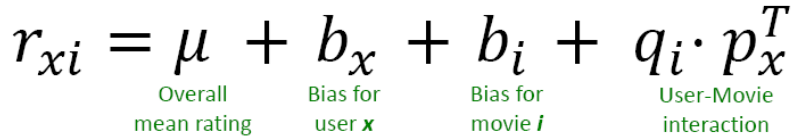
但是这样的话也引入了更多的参数。

时序信息
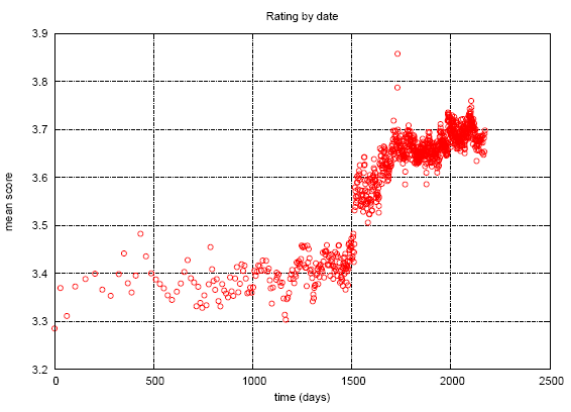
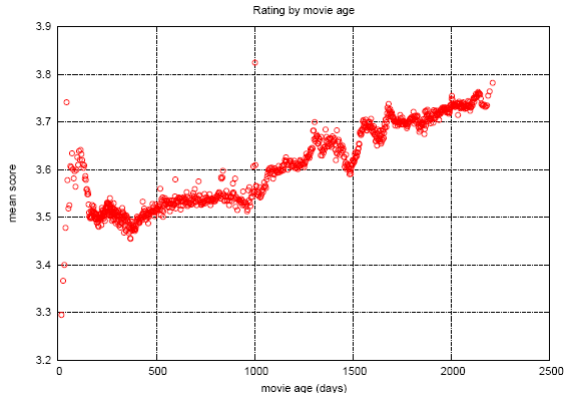
从图表上看,电影的综合评分突然在某一个时间节点之后高了一个档次。可能主要由于交互技术的发展。
Bellkor于是考虑了时序信息。
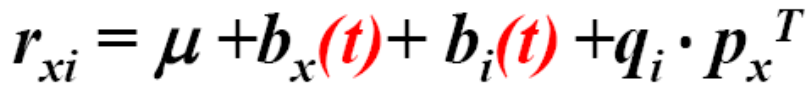
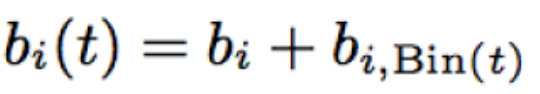
使得bu和bi依赖于时间。每一个bin对应连续的十个星期。
最终Bellkor等人在Netflix比赛中赢得了大奖。
不过在最后的时间节点,其余参与者将所有的模型集成了起来(百来个模型),采用集成学习方式,准确率也提高了10%
启发是若一个模型不咋样,可以采取集成学习方式提高准确率。
本文来自博客园,作者:Laplace蒜子,转载请注明原文链接:https://www.cnblogs.com/RedNoseBo/p/17436015.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号