
DSA
领域专用架构(DSA,Domain-Specific Architectures)
DSA设计原理
使用专门的存储器来最小化数据移动。(专门存储器,减少数据移动)
投入更多的运算单元和更多的存储器资源。(更多运算单元,更多存储器)
使用与应用领域匹配的最简单的并行结构。(简单并行架构)
将数据大小和类型减少到符合领域最简单的需求。(最简单的数据类型)
使用面向特定应用领域的特定编程语言。(面向编程语言)
TPU
TPU处理单元
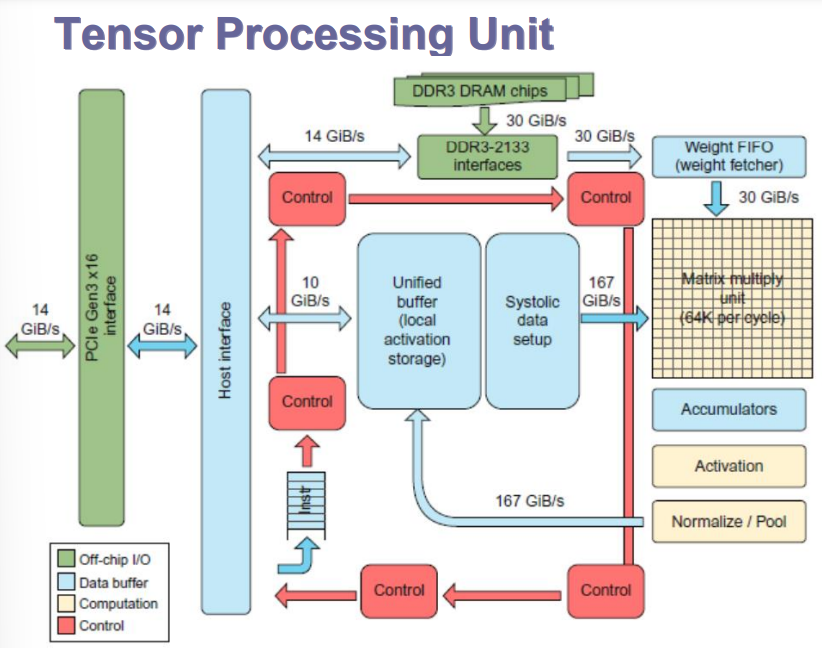
简化控制,控制逻辑相对较少。
TPU ISA定义(五类指令)
Read_Host_Memory:读内存,从CPU内存读入统一的缓冲区(从CPU读数据)
Read_Weights:将权重存储器中的权重数据读入权重FIFO。(从权重存储器读取权重)
MatrixMatrixMultiply/卷积:矩阵乘法。(卷积)
计算激活函数 (激活)
Write_Host_Memory:-将加速器自有的统一缓冲区中的数据写入主机内存。(写数据到主机)
TPU构造
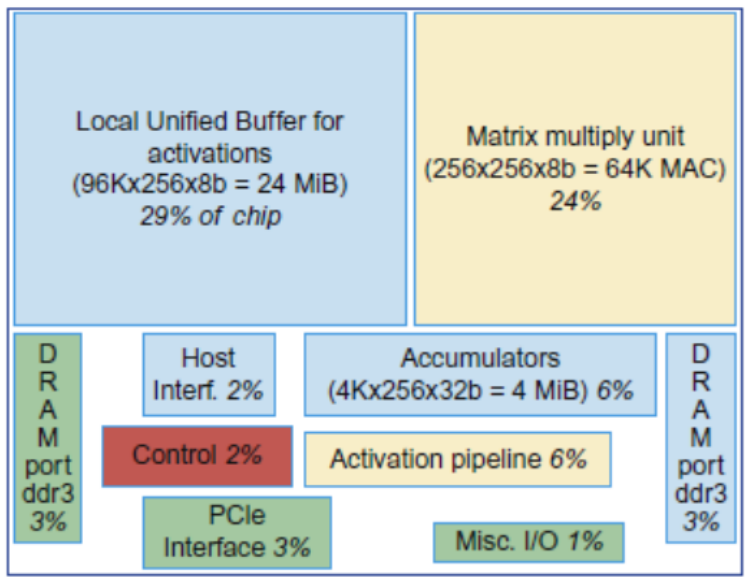
控制单元只占了2%。最大的两个分别是:本地统一缓冲区(29%),和矩阵乘法单元(24%)。
TPU设计原理(基本符合DSA设计原理)
专用存储器:24个MiB专用缓冲区,4个MiB累加器缓冲区
大量运算和存储资源:60%的存储器,250倍算术运算单元
最简单的并行形式:2维SIMD并行性
数据大小和类型:8位整数
编程语言:tensorflow。
Catapult设计原理
专用存储器:5个MiB专用存储器。
大量运算和存储资源:3926个算术运算单元
最简单的并行形式:CNN的2维SIMD并行性,搜索评分的MISD(多指令多数据)并行性。
数据大小和类型:8位整数和64位浮点数混合
编程语言:Verilog RTL。
Visual Core设计原理
专用存储器:每个核128+64个MiB专用存储器。
大量运算和存储资源:每个核包含16x16个2D处理单元阵列,2D移动网络。
最简单的并行形式:2D SIMD(单指令多数据) 和 VLIM(超长指令集)
数据大小和类型:8位整数和16位整数混合。
编程语言:图像处理的Halide和CNN的Tensorflow。
生态分析
站在芯片厂家的视角:希望把用户捆绑到自己私有的架构平台上,让用户形成依赖。
站在用户的视角:不愿意形成对特定厂家依赖,需要具备一定的通用性,方便应用跨硬件平台迁移
厂商博弈的最终结果:形成一个开源开放的行业生态(长远趋势)。
本文来自博客园,作者:Laplace蒜子,转载请注明原文链接:https://www.cnblogs.com/RedNoseBo/p/17354640.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号