
电影评论情感分析
数据集
数据集下载地址
https://ai.stanford.edu/~amaas/data/sentiment/解压压缩文件
功能函数
去除标签函数
html标签的正则表达式为:<[^>]+>
import re #引入正则表达式功能
def rm_tags(text):
re_tag = re.compile(r'<[^>]+>') #定义正则表达式
return re_tag.sub('',text) #将text中符合正则表达式的替换掉读取文件函数
文件目录结构
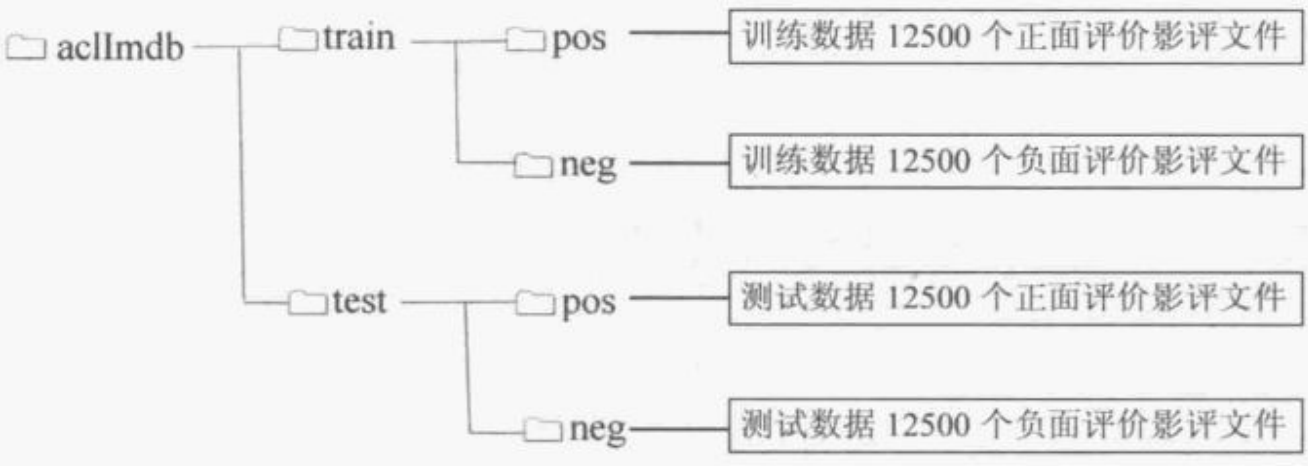
import os
def read_files(filetype): #filetype表示是训练数据还是测试数据
path='D:\\Andaconda\\envs\\TensorflowEnv\\Lib\\site-packages\\keras\\datasets\\aclImdb\\'
file_list=[] #创建文件列表
positive_path = path + filetype +"/pos/" #正面评价的文件目录为positive_path
for f in os.listdir(positive_path): #将positive_path目录下所有的文件加入file_list
file_list += [positive_path+f]
negative_path = path + filetype +"/neg/" #负面的文件目录为negative_path
for f in os.listdir(negative_path): #将negative_path目录下所有的文件加入file_list
file_list += [negative_path+f]
print('read',filetype,'files:',len(file_list))#显示读取的filetype("train"或"test")目录下的文件个数
all_labels = ( [1] * 12500 + [0] * 12500) #前部分产生12500项1,后部分产生12500项0,
all_texts =[]
for fi in file_list: #遍历文件列表
with open(fi,encoding = 'utf8') as file_input: #使用utf8格式打开一个文件,文件为file_input
all_texts += [rm_tags(" ".join(file_input.readlines()))]#使用file_input_readlines()读取文件,直到读取完所有文字
#用join连接所有文件内容,然后使用rm_tag删除tag,最后加入到all_tests中
return all_labels,all_texts #返回标签使用os.listdir(path)可以读取到一个文件夹下所有的文件名。
python表达式中,[] * number 可以将前面的列表元素复制number次,两个列表之间用+号表示合并两个列表。
使用open(path,encoding='') as file_input 可以以指定编码打开指定路径的文件,文件指针保存在file_input
file_input.readlines()表示读取整个文件,直到遇到文件结束符
file_input.readline()表示读取一行。
读取训练集和测试集
y_train,train_text= read_files("train")
y_test,test_text=read_files("test")将文字转换为数字列表
Tokenizer(num_words)可以建立指定单词个数的字典
Tokenizer().fit_on_texts(array),这里list结构是(2500,)可以将所有单词按照出现的次数进行排序,取前面指定个数的单词。
token.texts_to_sequences(array)函数可以将array中的文字,根据建立好的字典,转换成数字列表
token = Tokenizer(num_words=2000)#建立2000个单词的字典
token.fit_on_texts(train_text) #按照每一个英文单词在影评中出现的次数排序,前2000个会列入字典x_train_seq =token.texts_to_sequences(train_text) #将文字转换成数字列表
x_test_seq=token.texts_to_sequences(test_text) 
由于每个片段的单词个数是不定的,所以数字的个数也是不定的,但是要输入到感知器中,必须要固定数字个数,所以要使用pad_sequences,截长补短,超过了指定个数,在前面补0,超过了指定个数,就截取前面的文字
from keras.utils import pad_sequences
x_train = pad_sequences(x_train_seq,maxlen=100) #将数字都填充为100长度,截长补短,短了在前面加0,长了就截取前面的
x_test=pad_sequences(x_test_seq,maxlen=100) ![]()

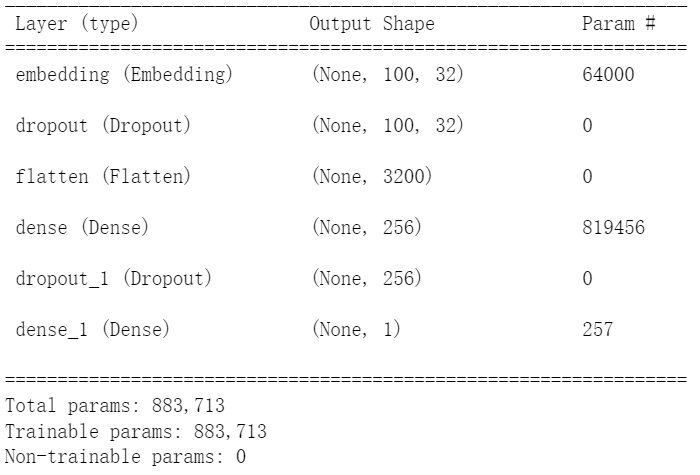
搭建多层感知器模型
导入模块
避免踩坑
Embedding层是从keras.layers中引入的,keras.layers.embedding中也有个Embedding层,但是引入之后不会自动建立输入层,调试麻烦。
from keras.models import Sequential
import keras
from keras.layers.core import Dense,Dropout,Activation,Flatten
from keras.layers import Input,Embeddingmodel=Sequential()
model.add(Embedding(output_dim=32,#将数字列表转换为32维向量
input_dim=2000, #输入有2000个项。
input_length=100))#数字列表的每一项有100个数字
model.add(Dropout(0.2))
model.add(Flatten()) #输入的每一项有100个数字,每一项转换为32维向量,平坦层也就一共有3200个神经元
model.add(Dense(units=256,#隐藏层有256个神经元,与平坦层全连接
activation='relu'))
model.add(Dropout(0.35))
model.add(Dense(units=1,#输出层只有1个神经元,输出1代表正面评价,0代表负面评价
activation='sigmoid'))Embedding(output_dim,input_dim,input_length)函数可以建立嵌入层,将所有数字列表,建立成一个指定维度的向量。
output_dim是输出单元个数,也就是要将词语建立成多少维向量。
input_dim是输入项的个数。
input_length是输入的每一项的长度。
网络结构
将标签集合转换为numpy数组
因为经过函数读取文件后,标签集是一个list集合,不是ndarray,不转换在训练时候无法自动分割验证集
import numpy as np
y_train=np.array(y_train) #因为y_train是list类型,要转换为ndarray类型,方便训练时候分割验证集,否则会报错
y_test=np.array(y_test)训练模型
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
train_history = model.fit(x_train,
y_train,
batch_size=100,
epochs=10,
verbose=2,
validation_split=0.2)评估模型
scores = model.evaluate(x_test,y_test)
scores[1]![]()
预测测试数据
predict = model.predict(x_test) #np.armax(pred,axis=-1)返回值为最大值的索引,只能对多分类模型或者是以softmax作为输出层激活函数的二分类模型
#因为predict是保存了所属所有类别的概率,而np.argmax是返回概率最高的哪一个索引
predict=np.int64(predict>0.5)
要注意softmax函数和sigmoid函数的区别
softmax函数用于多分类问题。 softmax综合了所有输出值的归一化。得到的预测每一项包含预测为所有类别的概率的列表,用于多分类。
sigmoid函数用于多标签问题,选取多个标签作为正确答案。得到的预测值是一个概率,在0到1之间,用于二分类。
建立对比函数
SentimentDict={1:"正面的",0:"负面的"}
def display_test_Sentiment(i):
print(test_text[i])
print('label真实值:',SentimentDict[y_test[i]],
'预测结果:',SentimentDict[prediction[i]])输出真实值和标签值对比
改变预测集的形状。
prediction = predict.reshape(-1)![]()
display_test_Sentiment(10)
自己输入数据测试
input_text="II wanted to LOVE THIS MOVIE WAITING so long to disappoint 1 or 2 songs fine but like 10 songs that's ridiculous KILLLED THE whole Movie for me ."
input_seq=token.texts_to_sequences([input_text]) #转换为数字列表
pad_input_seq=pad_sequences(input_seq,maxlen=100) #截长补短获得预测结果并输出
predict_result=model.predict(pad_input_seq)
predict_result ![]()
搭建RNN预测
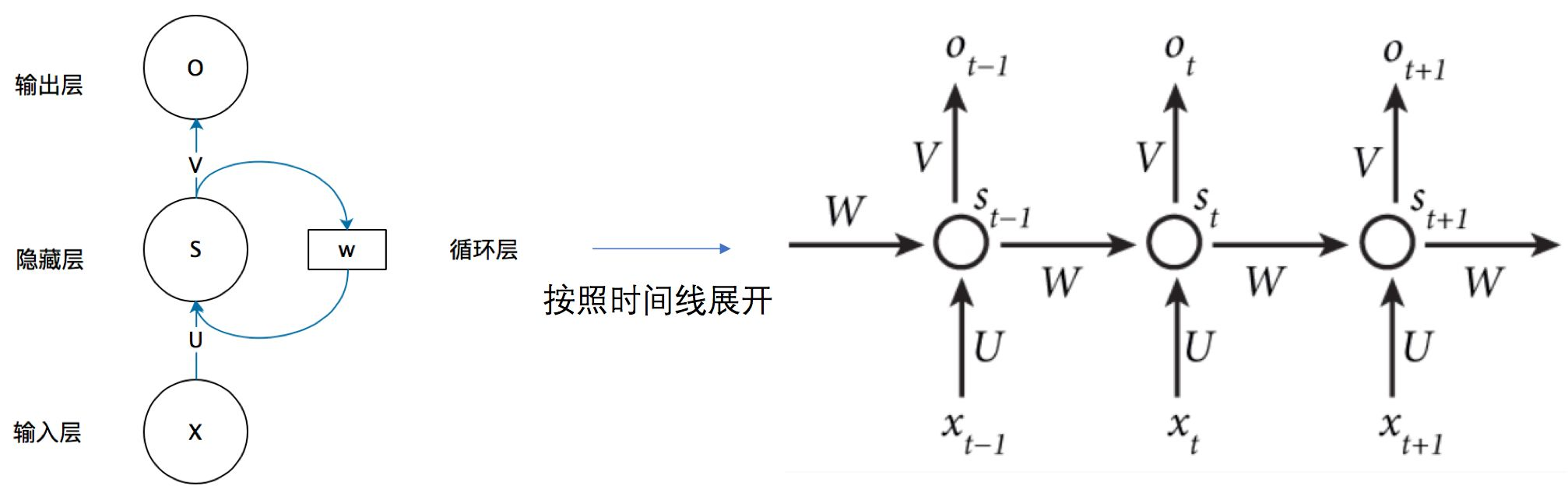
当前层输出经过一系列操作,得到输出后,将这个输出经过权重保存在隐藏层中,下一次输入要经过这个隐藏层处理。所以可以看成上一个时间点的输出作为当前时间点的隐藏状态,代表网络的记忆。
隐藏层更新方法:St=f(UXt+WSt-1),U和W都是模型参数。
主要是就该模型的搭建部分,以及词典长度和项的部分。
Embedding层与RNN层是全连接的。
import urllib.request
import os
import tarfile
from keras.preprocessing import sequence
from keras.preprocessing.text import Tokenizer
import re
def rm_tags(text):
re_tag = re.compile(r'<[^>]+>')
return re_tag.sub('',text)
import os
def read_files(filetype):
path='D:\\Andaconda\\envs\\TensorflowEnv\\Lib\\site-packages\\keras\\datasets\\aclImdb\\'
file_list=[] #创建文件列表
positive_path = path + filetype +"/pos/" #正面评价的文件目录为positive_path
for f in os.listdir(positive_path): #将positive_path目录下所有的文件加入file_list
file_list += [positive_path+f]
negative_path = path + filetype +"/neg/" #负面的文件目录为negative_path
for f in os.listdir(negative_path): #将negative_path目录下所有的文件加入file_list
file_list += [negative_path+f]
print('read',filetype,'files:',len(file_list))#显示读取的filetype("train"或"test")目录下的文件个数
all_labels = ( [1] * 12500 + [0] * 12500) #前部分产生12500项1,后部分产生12500项0,
all_texts =[]
for fi in file_list: #遍历文件列表
with open(fi,encoding = 'utf8') as file_input: #使用utf8格式打开一个文件,文件为file_input
all_texts += [rm_tags(" ".join(file_input.readlines()))]#使用file_input_readlines()读取文件,直到读取完所有文字
#用join连接所有文件内容,然后使用rm_tag删除tag,最后加入到all_tests中
return all_labels,all_texts #返回标签y_train,train_text= read_files("train")
y_test,test_text=read_files("test")token = Tokenizer(num_words=3800)#建立2000个单词的字典
token.fit_on_texts(train_text) #按照每一个英文单词在影评中出现的次数排序,前2000个会列入字典
x_train_seq =token.texts_to_sequences(train_text) #将文字转换成数字列表
x_test_seq=token.texts_to_sequences(test_text)from keras.utils import pad_sequences
x_train = pad_sequences(x_train_seq,maxlen=380) #将数字都填充为100长度,截长补短,短了在前面加0,长了就截取前面的
x_test=pad_sequences(x_test_seq,maxlen=380)
import numpy as np
y_train=np.array(y_train) #因为y_train是list类型,要转换为ndarray类型,方便训练时候分割验证集,否则会报错
y_test=np.array(y_test)from keras.models import Sequential
import keras
from keras.layers.core import Dense,Dropout,Activation,Flatten
from keras.layers import Input,Embedding
from keras.layers import SimpleRNNmodel=Sequential()
model.add(Embedding(output_dim=32,
input_dim=3800,
input_length=380))
model.add(Dropout(0.35))
model.add(SimpleRNN(units=16))
model.add(Dense(units=256,activation='relu'))
model.add(Dropout(0.35))
model.add(Dense(units=1,activation='sigmoid'))
model.summary()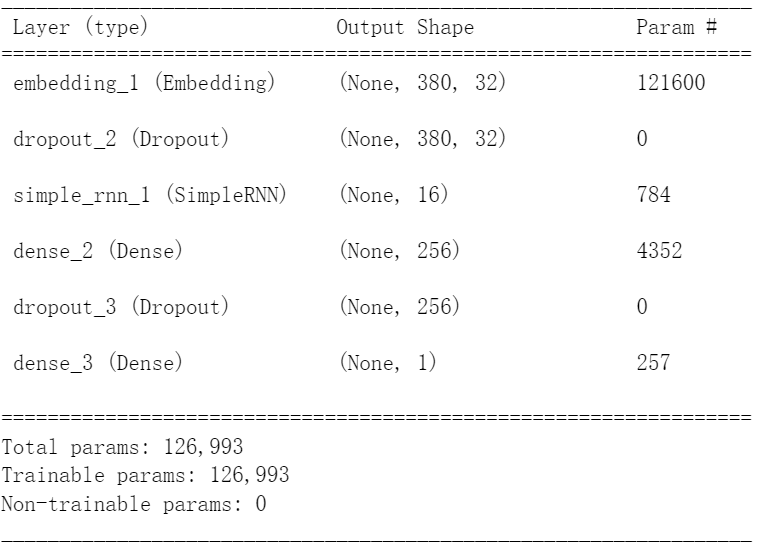
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
train_history = model.fit(x_train,
y_train,
batch_size=100,
epochs=10,
verbose=2,
validation_split=0.2)scores=model.evaluate(x_test,y_test,verbose=1)
scores[1]
搭建LSTM预测
RNN在训练是计算和反向传播梯度,梯度倾向于每一时刻都递增或减少,这样长期下来,梯度逐渐会发散到无穷大或者减少为0,这就是RNN的梯度爆炸和梯度消失问题。
RNN因此会丧失连接到远处的信息的能力。RNN也被称为短期记忆网络。
LSTM基于RNN进行了改进

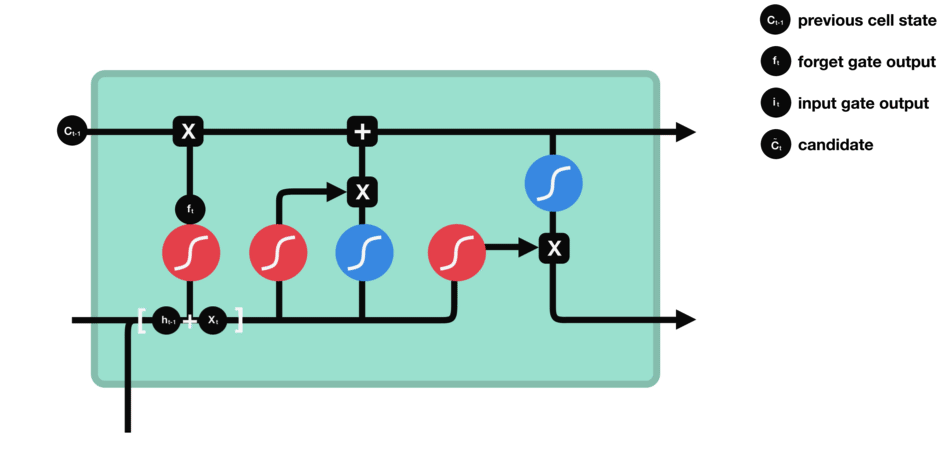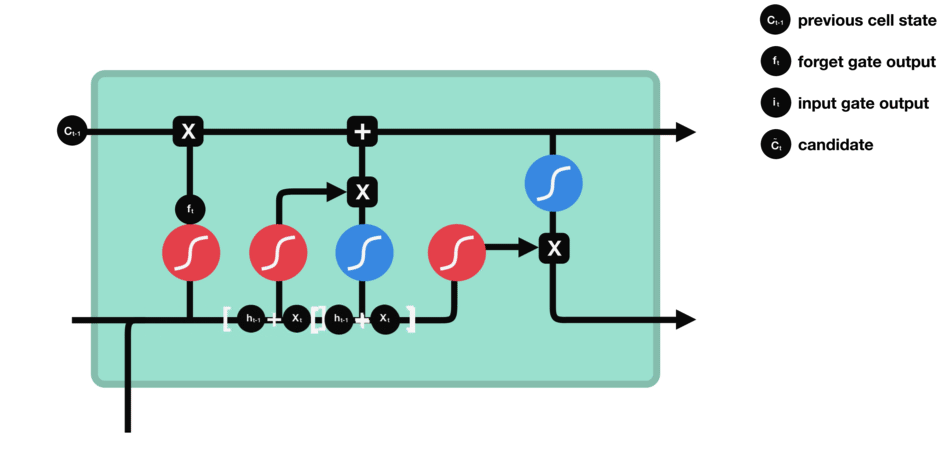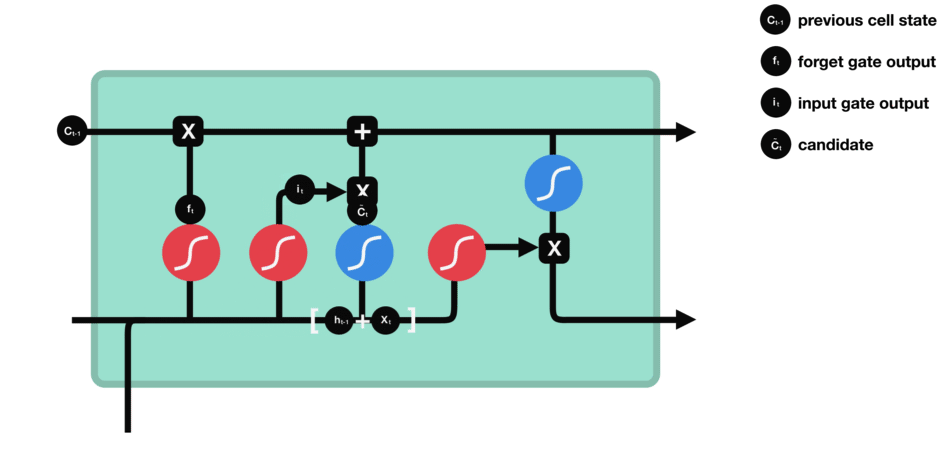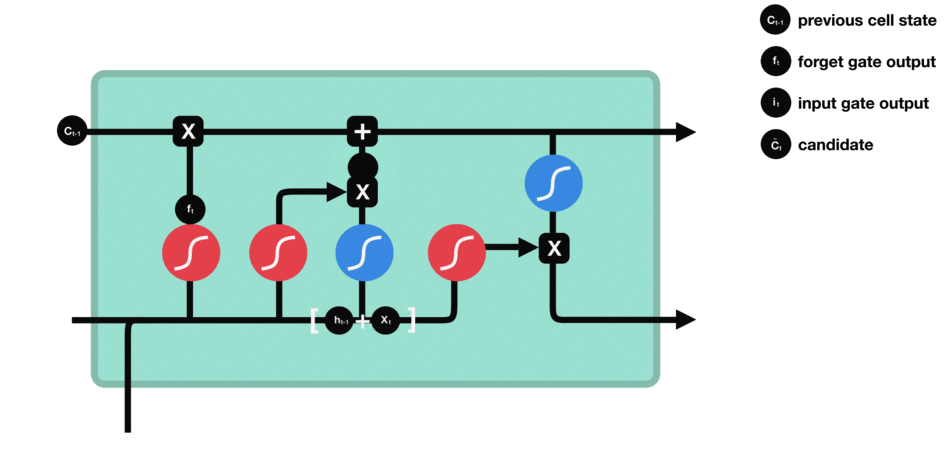
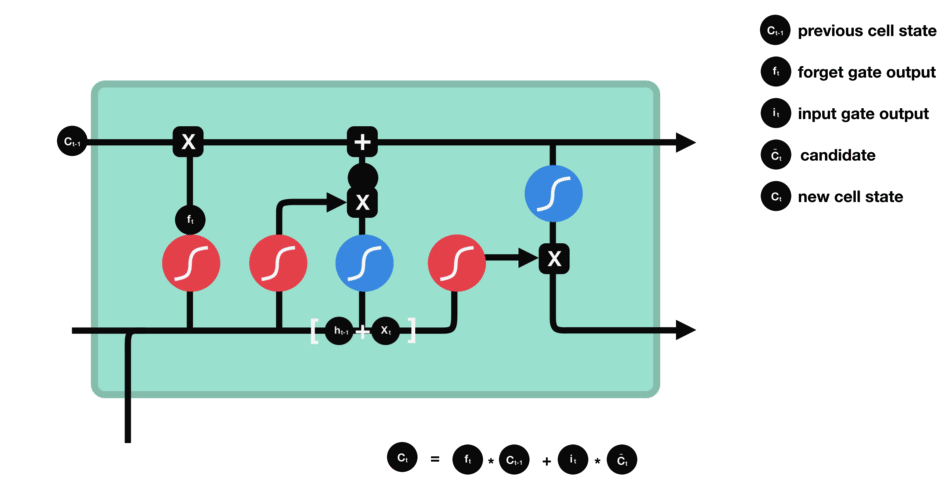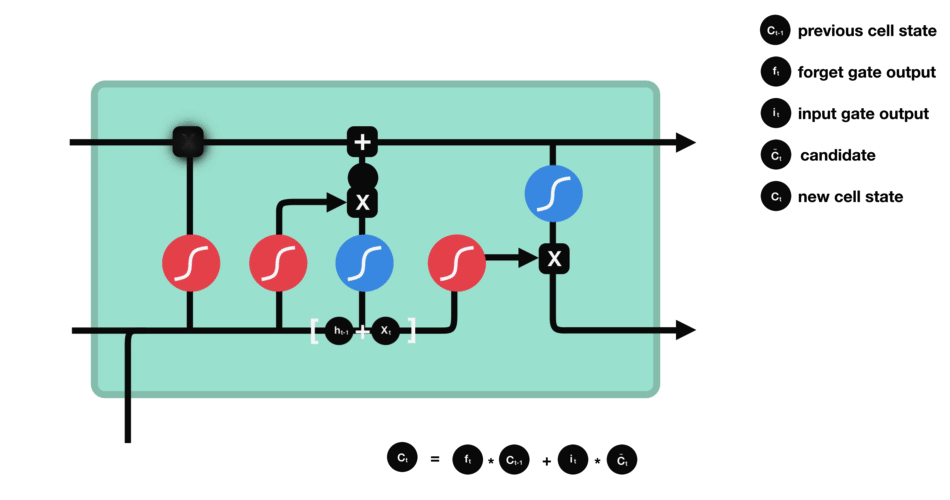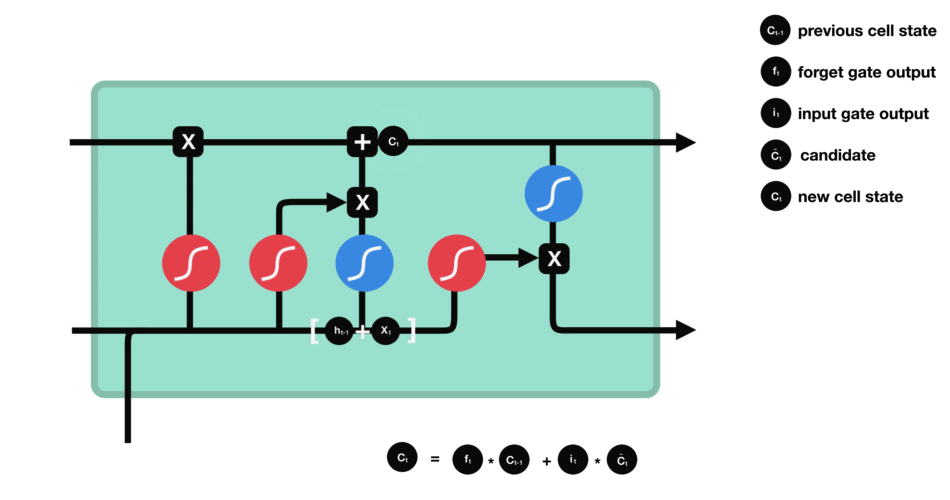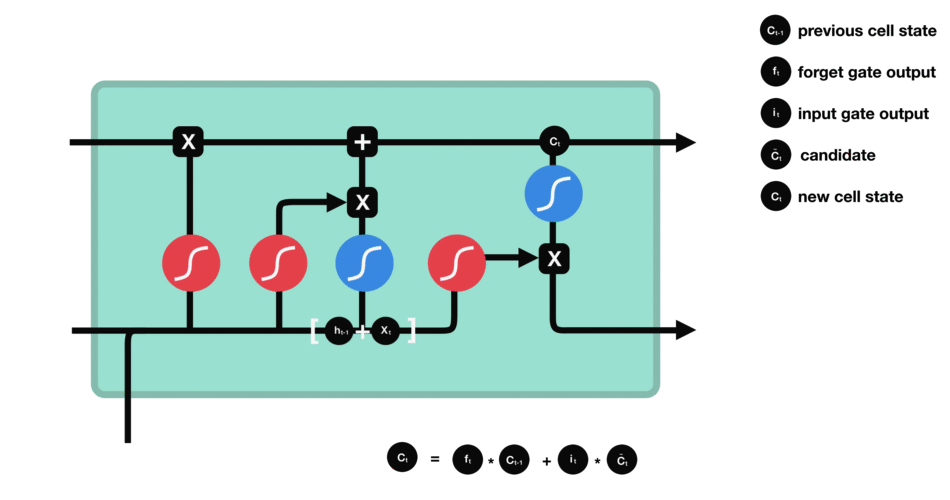
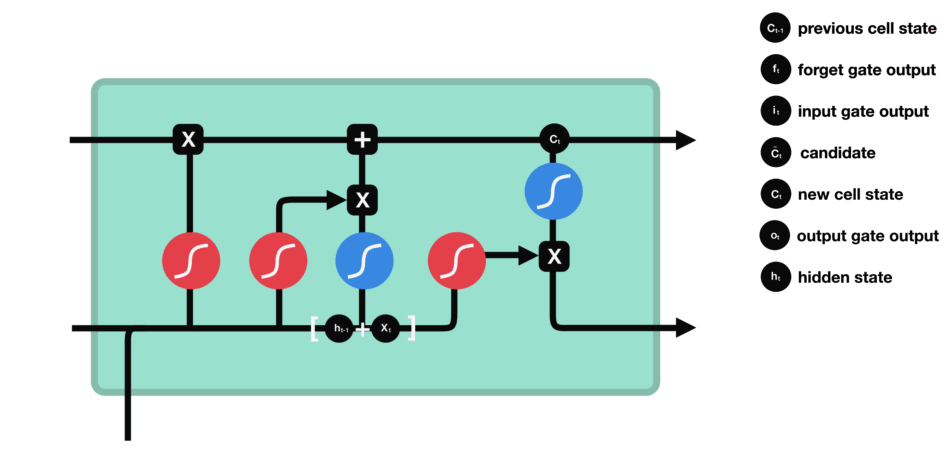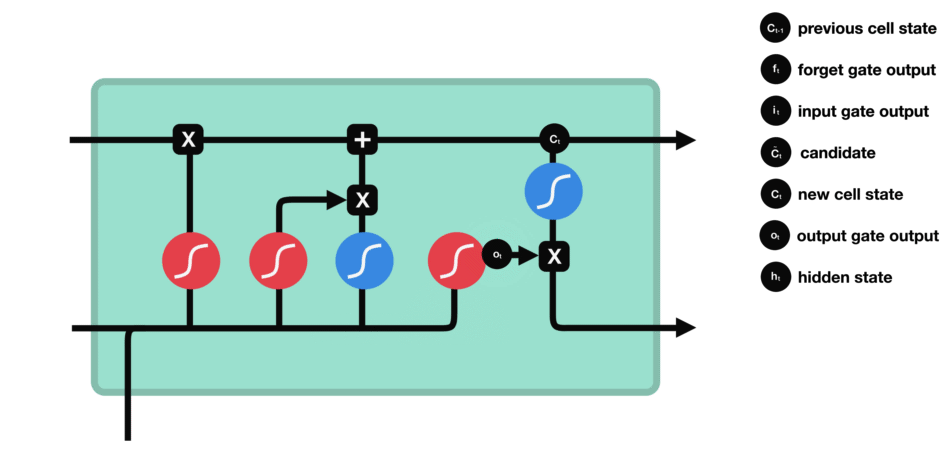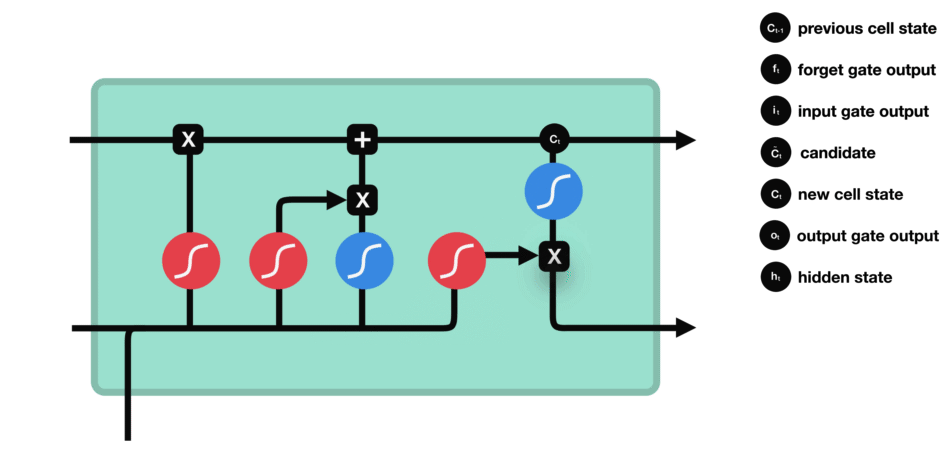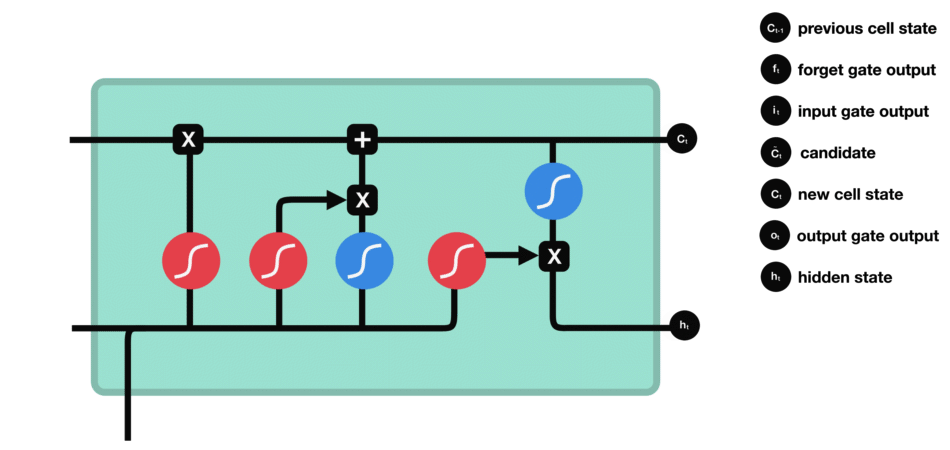
LSTM用一些列门来控制记忆细胞状态
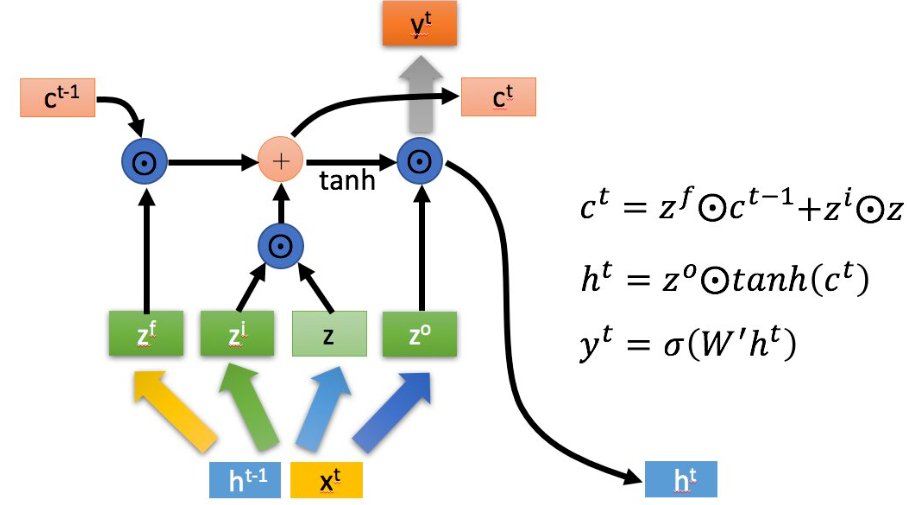
输入门:决定哪些信息要被增加到cell
遗忘门:决定哪些信息要从cell删减
输出门:决定哪些信息要从cell输出
import urllib.request
import os
import tarfile
from keras.preprocessing import sequence
from keras.preprocessing.text import Tokenizer
import re
def rm_tags(text):
re_tag = re.compile(r'<[^>]+>')
return re_tag.sub('',text)
import os
def read_files(filetype):
path='D:\\Andaconda\\envs\\TensorflowEnv\\Lib\\site-packages\\keras\\datasets\\aclImdb\\'
file_list=[] #创建文件列表
positive_path = path + filetype +"/pos/" #正面评价的文件目录为positive_path
for f in os.listdir(positive_path): #将positive_path目录下所有的文件加入file_list
file_list += [positive_path+f]
negative_path = path + filetype +"/neg/" #负面的文件目录为negative_path
for f in os.listdir(negative_path): #将negative_path目录下所有的文件加入file_list
file_list += [negative_path+f]
print('read',filetype,'files:',len(file_list))#显示读取的filetype("train"或"test")目录下的文件个数
all_labels = ( [1] * 12500 + [0] * 12500) #前部分产生12500项1,后部分产生12500项0,
all_texts =[]
for fi in file_list: #遍历文件列表
with open(fi,encoding = 'utf8') as file_input: #使用utf8格式打开一个文件,文件为file_input
all_texts += [rm_tags(" ".join(file_input.readlines()))]#使用file_input_readlines()读取文件,直到读取完所有文字
#用join连接所有文件内容,然后使用rm_tag删除tag,最后加入到all_tests中
return all_labels,all_texts #返回标签y_train,train_text= read_files("train")
y_test,test_text=read_files("test")
token = Tokenizer(num_words=3800)#建立2000个单词的字典
token.fit_on_texts(train_text) #按照每一个英文单词在影评中出现的次数排序,前2000个会列入字典
x_train_seq =token.texts_to_sequences(train_text) #将文字转换成数字列表
x_test_seq=token.texts_to_sequences(test_text)
from keras.utils import pad_sequences
x_train = pad_sequences(x_train_seq,maxlen=380) #将数字都填充为100长度,截长补短,短了在前面加0,长了就截取前面的
x_test=pad_sequences(x_test_seq,maxlen=380)
import numpy as np
y_train=np.array(y_train) #因为y_train是list类型,要转换为ndarray类型,方便训练时候分割验证集,否则会报错
y_test=np.array(y_test)from keras.models import Sequential
import keras
from keras.layers.core import Dense,Dropout,Activation,Flatten
from keras.layers import Input,Embedding
from keras.layers import LSTMmodel=Sequential()
model.add(Embedding(output_dim=32,
input_dim=3800,
input_length=380))
model.add(Dropout(0.2))
model.add(LSTM(units=32))
model.add(Dense(units=256,
activation='relu'))
model.add(Dropout(0.2))
model.add(Dense(units=1,
activation='sigmoid'))
model.summary()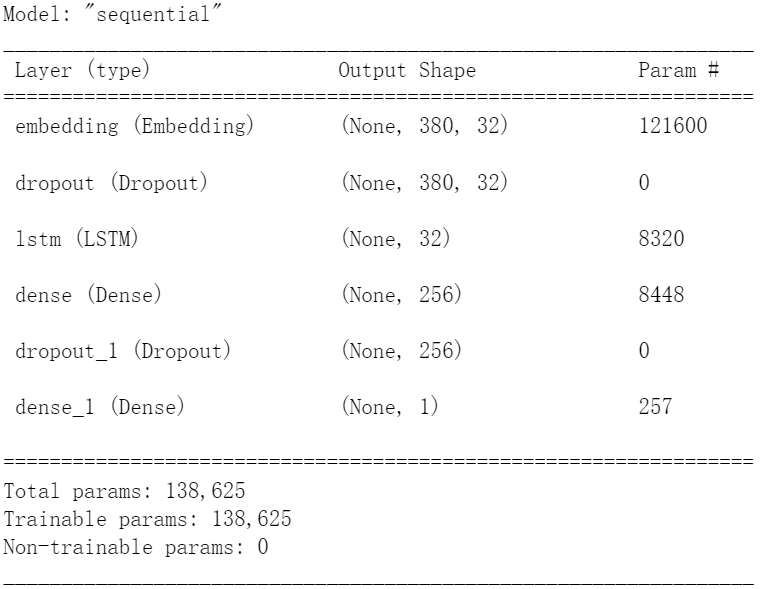
model.compile(loss='binary_crossentropy',
optimizer='adam',
metrics=['accuracy'])
train_history = model.fit(x_train,
y_train,
batch_size=100,
epochs=10,
verbose=2,
validation_split=0.2)scores=model.evaluate(x_test,y_test,verbose=1)
scores[1]![]()
本文来自博客园,作者:Laplace蒜子,转载请注明原文链接:https://www.cnblogs.com/RedNoseBo/p/17213841.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号