
MNIST
MNIST数据集合
MNIST数据集共有训练数据60 000项,测试数据10 000项,每一项都是由images和label组成。图像大小都是28 x 28。
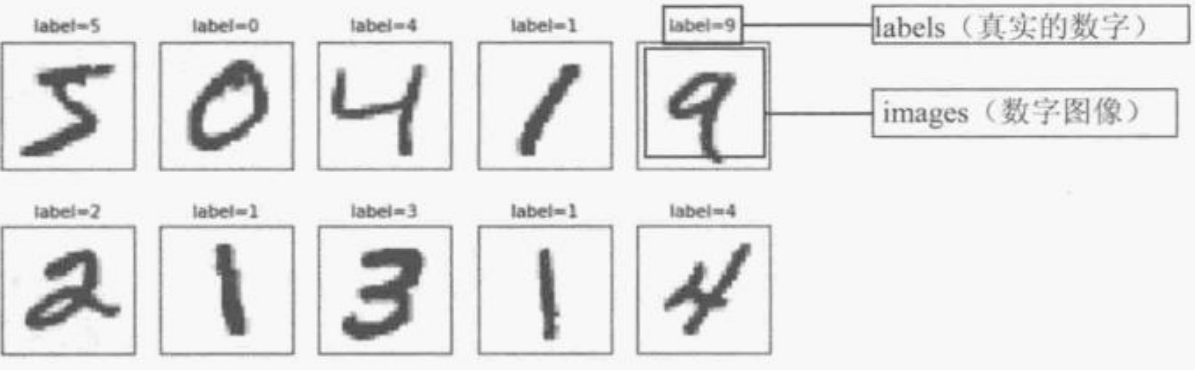
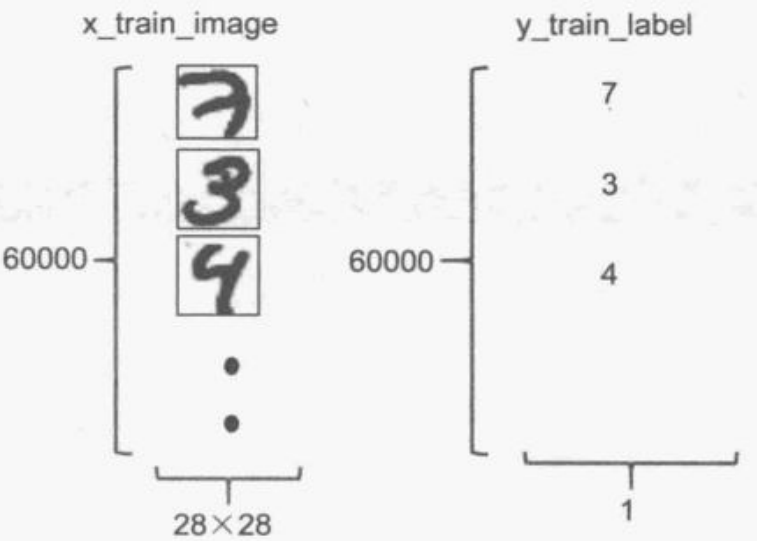
数据预处理
导入需要的模块
import numpy as np
import pandas as pd
from keras.utils import np_utils
import matplotlib.pyplot as pltmatplotlib.pyplot是绘图模块
keras.utils中有个函数可以将label标签转换为独热编码表示,后续会用到
numpy是科学计算库
导入MNIST数据集
from keras.datasets import mnist
(X_train_image,y_train_label),(X_test_image,y_test_label)=mnist.load_data()mnist.load_data()
若不指定括号中的参数,会自动加载“环境路径\Lib\site-packages\keras\datasets”或者“C:\Users\User\.keras\datasets”下的mnist.npz
查看数据集
查看数据集长度
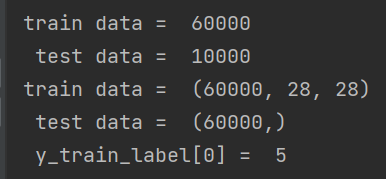
print('train data = ',len(X_train_image)) #训练集长度
print(' test data = ',len(X_test_image)) #测试集长度
print('train data = ',X_train_image.shape) #训练集数据的形状
print(' test data = ',y_train_label.shape) #训练集标签的形状
print(' y_train_label[0] = ', y_train_label[0])#显示训练集第一项的标签输出结果为
显示图像
因为训练集中每一项都是由图像和标签组成,因此要建立一个打印图像的函数,以便于打印图像
def plot_image(image):
fig=plt.gcf();#创建一个图形
fig.set_size_inches(2,2)#设置图形大小
plt.imshow(image,cmap='binary')#plt显示图像,类型为二值图像
plt.show()#开始绘图plt.gcf() 函数作用是创建一个图形
gcf().set_size_inches(size,size) 函数作用是设置图像的大小,单位为英尺
plt.imshow(图像矩阵,cmap='图像类型') 函数用于设置要显示的图像
plt.show() 函数用于绘制图像
显示训练中的第一项
plot_image(X_train_image[0])#绘制训练集第一项的图 
显示多个图像,标签,以及预测值
def plot_images_labels_prediction(images,#数字图像
labels,#真实值
prediction,#预测结果
idx,#开始显示的数据index
num=10#要显示的数据项,默认是10,不超过25
):
fig = plt.gcf();#创建图形
fig.set_size_inches(12,14)#设置图形大小
if num>25: num=25 #限制显示的数据项
for i in range(0,num): #画出num个数字图形
ax=plt.subplot(5,5,1+i) #子图为5行5列,每一项索引为1+i
ax.imshow(images[idx],cmap='binary')#ax中国画出下标为idx的图像,图像为二值图
title="label" + str(labels[idx]) #设置标题
if len(prediction)>0: #如果传入了预测结果,就显示预测结果
title+=",predict="+str(prediction[idx])
ax.set_title(title,fontsize=10)
ax.set_xticks([])#设置不显示x刻度
ax.set_yticks([])#设置不显示y刻度
idx+=1
plt.show()此函数的功能打印一个图像数组中的所有图像,最多显示25幅图像,若预测值缺失,则不打印预测值,idx指定起始图像的索引,num表示打印图像的数量
plot.subplot(row,column,index) 函数将图像切分为指定行指定列的多个子图,子图索引index
subplot().imshow(image,cmap='类型') 函数用于将指定图像放置到子图中。
subplot().set_title() 函数用于设置子图标题
subplot(),set_xticks([]) 函数可以设置x轴的刻度,若参数为空则不显示x轴
subplot(),set_yticks([]) 函数可以设置y轴的刻度,若参数为空则不显示y轴
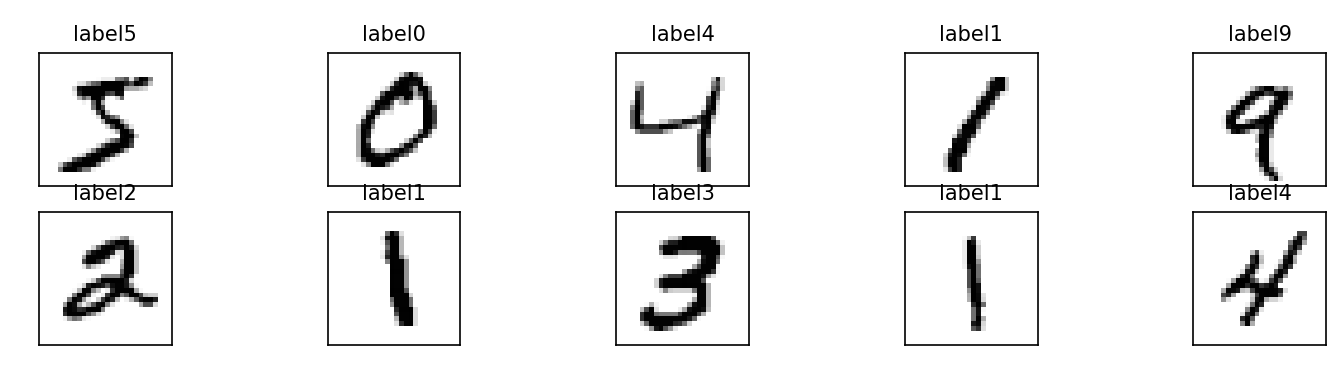
输出图像
plot_images_labels_prediction(X_train_image,y_train_label,[],0,10)结果为:
数据集处理
改变数据集形状
原本训练集形状为(60000,28,28)改变为(60000,784),类型为32位浮点型。
原本测试集形状为(10000,28,28)改变为(10000,784),类型为32位浮点型。
相当于将后面两维合并。
x_Train= X_train_image.reshape(60000,784).astype('float32')
x_Test = X_test_image.reshape(10000,784).astype('float32')
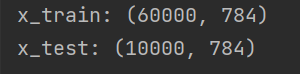
print('x_train:',x_Train.shape)
print('x_test:',x_Test.shape)结果
归一化处理
因为数字图像像素范围通常是从0到255,所以只要将图像矩阵中每个元素除以255即可。
归一化的作用是将值压缩到0到1之间。
x_Train_normalize=x_Train/255
x_Test_normalize=x_Test/255转换为独热编码表示
什么是独热编码
原本数据的类别有多少,就创建多长的数字串,在所属类别位置设置为1。
如数字0到9。就可以常见长度为10的数字串。0就在第1位设置为1表示,1就在第二位设置为1表示。
如数字5,用独热编码表示就是:0 0 0 0 0 1 0 0 0 0
如数字1,用独热编码表示就是:0 1 0 0 0 1 0 0 0 0
转换函数
使用keras.untils工具中的to_categorical( array )函数,将指定数组中的值转换为独热编码表示
y_TrainOneHot = np_utils.to_categorical(y_train_label)
y_TestOneHot = np_utils.to_categorical(y_test_label)
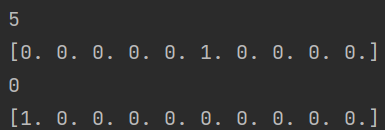
print(y_train_label[0])
print(y_TrainOneHot[0])
print(y_train_label[1])
print(y_TrainOneHot[1])输出结果为
Keras多层感知器识别手写数字
类型1搭建
结构
一个输入层,包含784个输入神经元,
一个隐藏层,包含256个隐藏神经元,
一个输出层,十个输出神经元,对应十个预测结果
数据预处理
x_Train=X_train_image.reshape(60000,784).astype('float32')
x_Test=X_test_image.reshape(10000,784).astype('float32')
x_Train_normalize=x_Train / 255
x_Test_normalize=x_Test/255
y_Train_OneHot=np_utils.to_categorical(y_train_label)
y_Test_OneHot=np_utils.to_categorical(y_test_label)x_Train=X_train_image.reshape(60000,784).astype('float32') #将加载的训练数据从(60000,28,28)改成(60000,784),类型为浮点数
x_Test=X_test_image.reshape(10000,784).astype('float32') #将加载的测试数据从(10000,28,28)改成(10000,784),类型为浮点数
x_Train_normalize=x_Train / 255 #将每一像素归一化,像素区间为255,归到0-1区间,除以255,可以提高准确度,更快收敛。
x_Test_normalize=x_Test/255
y_Train_OneHot=np_utils.to_categorical(y_train_label) #将训练数据标签用独热编码表示
y_Test_OneHot=np_utils.to_categorical(y_test_label) #将测试数据标签用独热编码表示建立模型
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout #引入Dropout层model = Sequential()#建立初始模型,初始什么都没有#隐藏层和输入层是同时建立的
model.add(Dense(units=256, #隐藏层的神经元个数
input_dim=784, #输入层神经元个数
kernel_initializer='normal', #使用normal distribution正态分布的随机数来初始化权重(w)和偏差(b)
activation='relu')) #激活函数为relu#增加输出层
model.add(Dense(units=10, #输出层神经元个数为10
kernel_initializer='normal', #初始化权重w和偏差b使用normal来初始化
activation='softmax')) #激活函数为softmax输出信息
可以使用model.summary()函数来输出模型的参数
print(model.summary())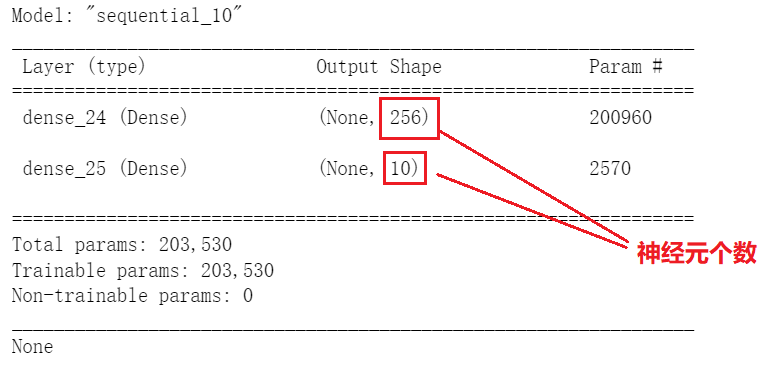
参数的计算方式
Param = (上一层神经元数量) x (本层的神经元数量) + (本层的神经元数量)
参数总和就是各层的参数加起来
训练模型
使用model.compole()函数定义模型的训练方式
#定义训练方式
model.compile(loss='categorical_crossentropy',#设置损失函数,这里使用交叉熵损失
optimizer='adam',#设置优化器,这里使用adam优化器,可以让模型更快收敛,提高准确率
metrics=['accuracy'])#设置评估模型的方式是准确率开始训练模型
train_history=model.fit(x=x_Train_normalize,#输入图像的特征值
y=y_Train_OneHot,#输入标签的真实值
validation_split=0.2, #设置训练与验证数据比例
epochs=10, #设置训练周期
batch_size=200,#每一批次200项数据
verbose=2#显示训练过程
)
因为设置训练与验证数据的比例为0.2,所以训练的数据有60000 x 0.8 = 48000项,每一批次200项,大约分为240批训练
训练完成会计算这个训练周期的准确率与误差
loss:训练数据计算误差
acc:训练数据的准确率
val_loss:验证数据的误差
val_acc:验证数据的准确率
输出训练信息
定义一个输出信息函数,参数为历史,显示的第一项(二维数组,有对应的x和y),显示的第二项(二维数组,有对应的x和y)
import matplotlib.pyplot as plt
def show_train_history(train_history,train,validation):#参数为训练产生的历史,训练数据的执行结果,验证数据的执行结果
plt.plot(train_history.history[train]) #绘制历史中训练数据的执行结果的折线图
plt.plot(train_history.history[validation]) #绘制历史中训练验证的执行结果的折线图
plt.title('Train History')#显示标题
plt.ylabel(train)#y轴标签
plt.xlabel('Epoch')#x轴标签是'Epoch'
plt.legend(['train','validation'] , loc='upper left')#图例显示'train','validation',位置左上角
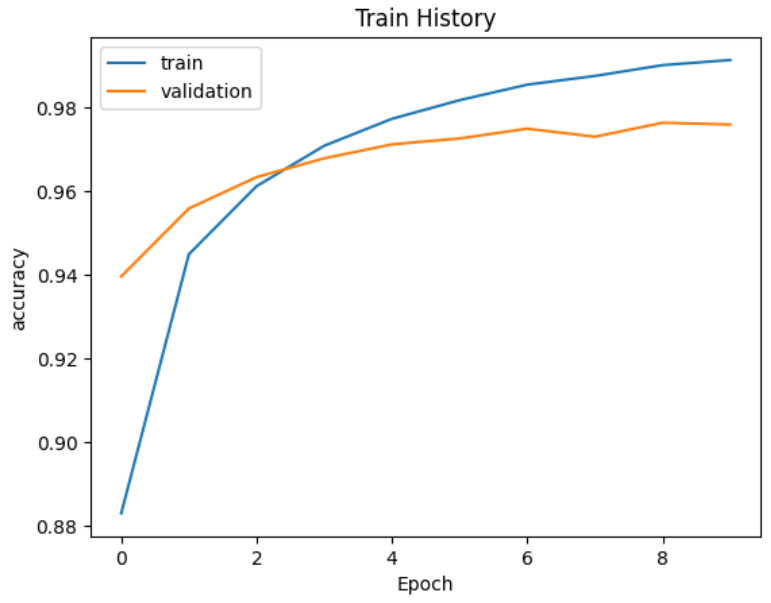
plt.show()show_train_history(train_history,'accuracy','val_accuracy')history参数说明
'accuracy':训练数据准确率
val_accuracy:‘验证数据的准确率’
'loss':训练数据上准确率
'val_loss':验证数据上的准确率
模型评估
使用model.evaluate()函数来评估模型,输入参数为测试数据的归一化的输入,以及测试数据的真实标签的独热编码。
scores=model.evaluate(x_Test_normalize,y_Test_OneHot) #使用model.evaluate评估模型的准确率,结果存放在scores中
print()
print('accuracy=',scores[1])#显示准确率准确率放在索引为1的位置。

使用模型预测数据
使用model.predict()函数来预测数据,输入为测试数据
prediction=model.predict(x_Test) #使用模型预测测试数据
prediction=np.argmax(prediction,axis=1) #将样本最大概率归属类别的值转化为样本的预测数组。
prediction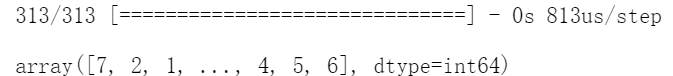
打印测试图像,预测值,以及真实值
plot_images_labels_prediction(X_test_image,y_test_label,prediction,idx=300)
#显示预测结果,输入参数为测试数据图像,测试数据的真实值,预测结果和显示从340个开始显示十个
构建混淆矩阵
使用pandas库的crosstab来构建混淆矩阵,输入数据为测试数据的真实标签,测试数据的预测标签,行名字为label,列名字为predict
import pandas as pd
pd.crosstab(#使用corsstab建立混淆矩阵(误差矩阵)
y_test_label, #测试数据的真实标签
prediction,#测试数据的预测结果
rownames=['label'],#行的名称为label
colnames=['predict'])#列的名称为predict
矩阵的值表示真实标签为 rowa 但是预测到的值为colb的次数
对角线是预测正确的次数。
1被预测正确次数最高,最不容易混淆。
5被预测正确的次数最低,最容易混淆。
构建DataFrame
可以使用pandas库的DataFrame()函数来构建DataFrame,输入为一个列表,分别对应每一列
df=pd.DataFrame({'label':y_test_label,'predict':prediction}) #建立一个DataFrame,包括两列,一列Label和一列predict
df[:10] #输出前10行
df[(df.label==5)&(df.predict==3)] #输出label为5,但是预测为3的值。 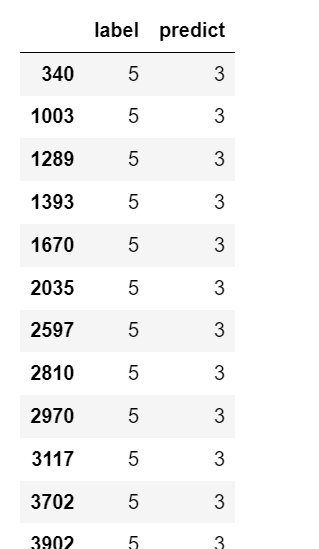
类型2(增加神经元个数)
x_Train=X_train_image.reshape(60000,784).astype('float32')
x_Test=X_test_image.reshape(10000,784).astype('float32')
x_Train_normalize=x_Train / 255
x_Test_normalize=x_Test/255
y_Train_OneHot=np_utils.to_categorical(y_train_label)
y_Test_OneHot=np_utils.to_categorical(y_test_label)
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
model = Sequential()
model.add(Dense(units=1000, #输入层和隐藏层是一起建立的
input_dim=784,
kernel_initializer='normal',
activation='relu'))
model.add(Dense(units=10,
kernel_initializer='normal',
activation='softmax'))
print(model.summary())
model.compile(loss='categorical_crossentropy',#设置损失函数,这里使用交叉熵损失
optimizer='adam',#设置优化器,这里使用adam优化器,可以让模型更快收敛,提高准确率
metrics=['accuracy'])#设置评估模型的方式是准确率
train_history=model.fit(x=x_Train_normalize,#输入图像的特征值
y=y_Train_OneHot,#输入标签的真实值
validation_split=0.2, #设置训练与验证数据比例
epochs=10, #设置训练周期
batch_size=200,#每一批次200项数据
verbose=2#显示训练过程
)
import matplotlib.pyplot as plt
def show_train_history(train_history,train,validation):#参数为训练产生的历史,训练数据的执行结果,验证数据的执行结果
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title('Train History')#显示标题
plt.ylabel(train)#y轴标签
plt.xlabel('Epoch')#x轴标签是'Epoch'
plt.legend(['train','validation'] , loc='upper left')#图例显示'train','validation',位置左上角
plt.show()
show_train_history(train_history,'accuracy','val_accuracy')
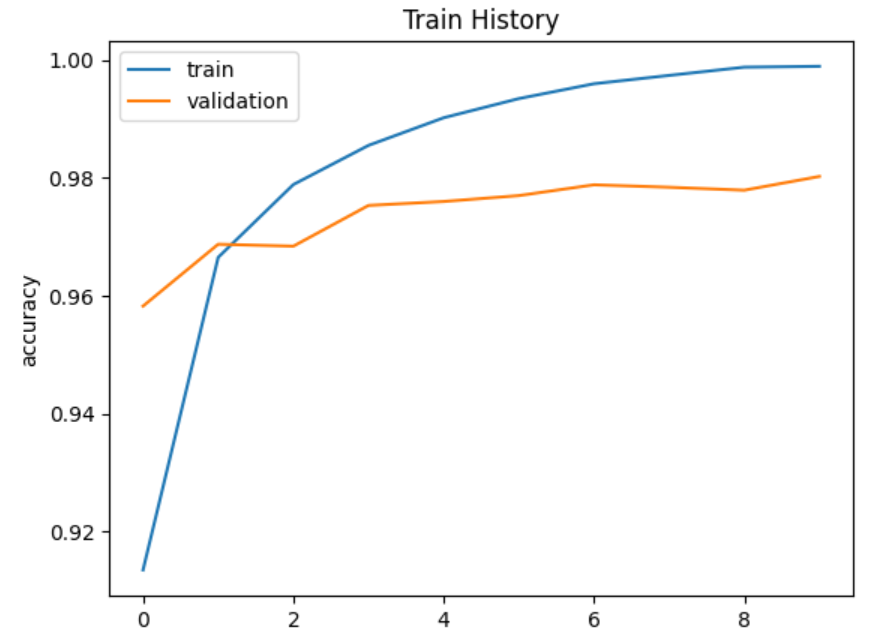
会发现增加神经元个数,出现了过拟合的现象,可以加入Dropout层来防止过拟合
类型3(增加神经元,同时增加Dropout层)
x_Train=X_train_image.reshape(60000,784).astype('float32')
x_Test=X_test_image.reshape(10000,784).astype('float32')
x_Train_normalize=x_Train / 255
x_Test_normalize=x_Test/255
y_Train_OneHot=np_utils.to_categorical(y_train_label)
y_Test_OneHot=np_utils.to_categorical(y_test_label)
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
model = Sequential()
model.add(Dense(units=1000, #输入层和隐藏层是一起建立的
input_dim=784,
kernel_initializer='normal',
activation='relu'))
model.add(Dropout(0.5))#加入Dropout层,丢弃率50%,防止过拟合
model.add(Dense(units=10,
kernel_initializer='normal',
activation='softmax'))
print(model.summary())
model.compile(loss='categorical_crossentropy',#设置损失函数,这里使用交叉熵损失
optimizer='adam',#设置优化器,这里使用adam优化器,可以让模型更快收敛,提高准确率
metrics=['accuracy'])#设置评估模型的方式是准确率
train_history=model.fit(x=x_Train_normalize,#输入图像的特征值
y=y_Train_OneHot,#输入标签的真实值
validation_split=0.2, #设置训练与验证数据比例
epochs=10, #设置训练周期
batch_size=200,#每一批次200项数据
verbose=2#显示训练过程
)
import matplotlib.pyplot as plt
def show_train_history(train_history,train,validation):#参数为训练产生的历史,训练数据的执行结果,验证数据的执行结果
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title('Train History')#显示标题
plt.ylabel(train)#y轴标签
plt.xlabel('Epoch')#x轴标签是'Epoch'
plt.legend(['train','validation'] , loc='upper left')#图例显示'train','validation',位置左上角
plt.show()
show_train_history(train_history,'accuracy','val_accuracy')
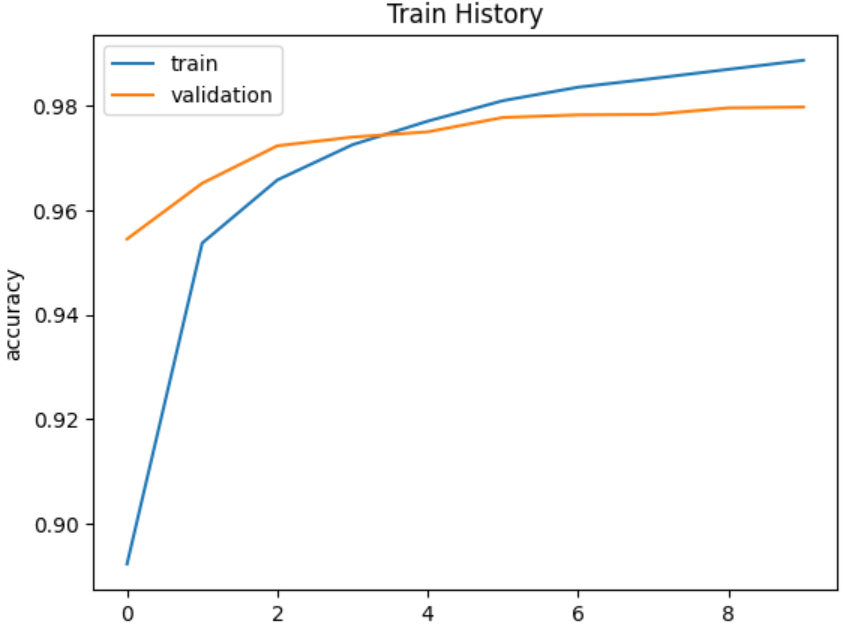
类型4(增加神经元个数,两个隐藏层,两个Dropout层)
x_Train=X_train_image.reshape(60000,784).astype('float32')
x_Test=X_test_image.reshape(10000,784).astype('float32')
x_Train_normalize=x_Train / 255
x_Test_normalize=x_Test/255
y_Train_OneHot=np_utils.to_categorical(y_train_label)
y_Test_OneHot=np_utils.to_categorical(y_test_label)
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Dropout
model = Sequential()
model.add(Dense(units=1000, #输入层和隐藏层是一起建立的
input_dim=784,
kernel_initializer='normal',
activation='relu'))
model.add(Dropout(0.5))#加入Dropout层,丢弃率50%,防止过拟合
model.add(Dense(units=1000, #再加一层隐藏层
kernel_initializer='normal',
activation='relu'))
model.add(Dropout(0.5)) #加入Dropout层次
model.add(Dense(units=10,
kernel_initializer='normal',
activation='softmax'))
print(model.summary())
model.compile(loss='categorical_crossentropy',#设置损失函数,这里使用交叉熵损失
optimizer='adam',#设置优化器,这里使用adam优化器,可以让模型更快收敛,提高准确率
metrics=['accuracy'])#设置评估模型的方式是准确率
train_history=model.fit(x=x_Train_normalize,#输入图像的特征值
y=y_Train_OneHot,#输入标签的真实值
validation_split=0.2, #设置训练与验证数据比例
epochs=10, #设置训练周期
batch_size=200,#每一批次200项数据
verbose=2#显示训练过程
)
import matplotlib.pyplot as plt
def show_train_history(train_history,train,validation):#参数为训练产生的历史,训练数据的执行结果,验证数据的执行结果
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title('Train History')#显示标题
plt.ylabel(train)#y轴标签
plt.xlabel('Epoch')#x轴标签是'Epoch'
plt.legend(['train','validation'] , loc='upper left')#图例显示'train','validation',位置左上角
plt.show()
show_train_history(train_history,'accuracy','val_accuracy')
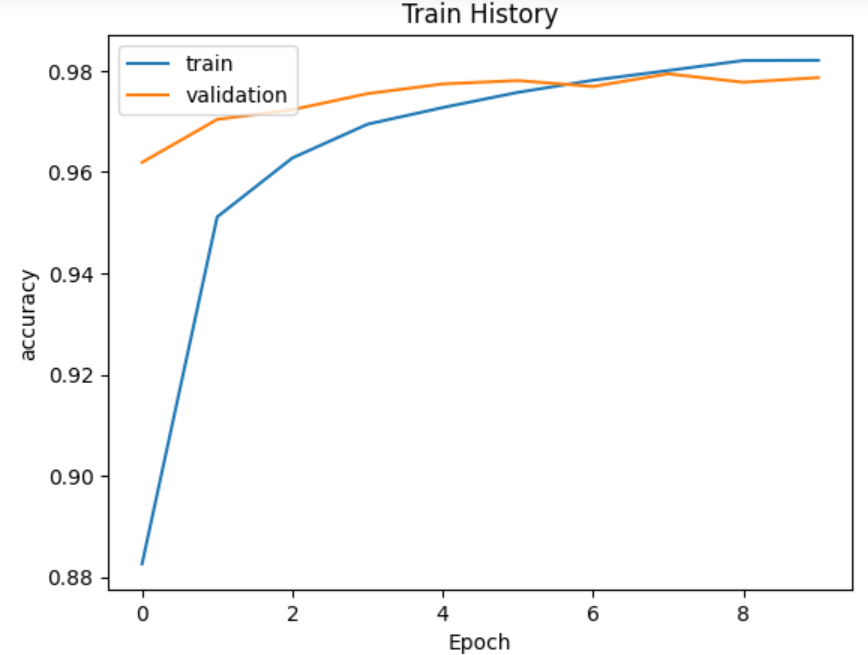
总结
四个模型比较
1个输入层,1个隐藏层(256个神经元),1个输出层
1个输入层,1个隐藏层(1000个神经元),1个输出层
1个输入层,1个隐藏层(1000个神经元),1个Dropout层,1个输出层
1个输入层,2个隐藏层(1000个神经元),2个Dropout层,1个输出层
比较如下:
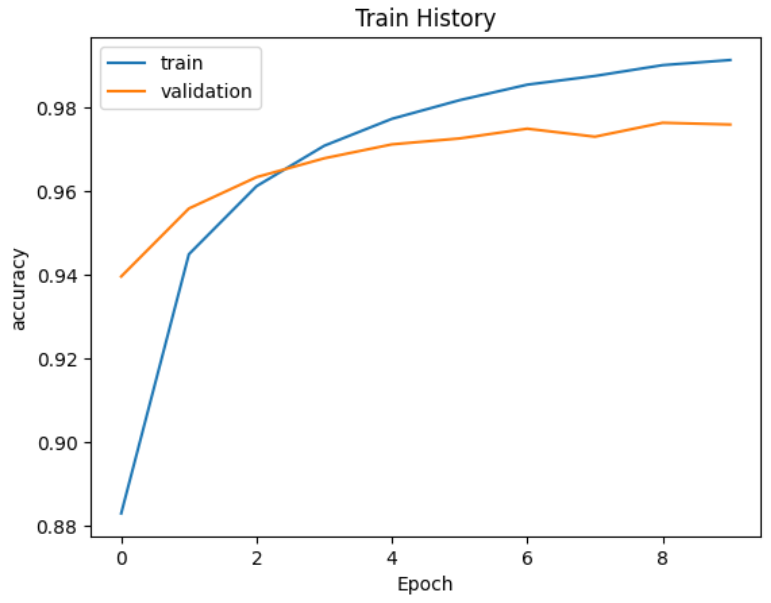
可以发现并不是隐藏层神经元个数越多越好
解决过拟合:使用Dropout层
最终2个隐藏层2个Dropout层效果最好。
建立模型总结
输入层神经元个数要和输入值的个数对应,输出层神经元个数就是要预测的结果个数。
函数总结
np.utils.to_categorical( array ):将array转换为独热编码表示
np.array.reshape():改变array的形状
np.array.reshape().astype(''):改变array的形状的同时制定类型
Sequential():创建初始模型
model.add( Dense() ):增加一层,输入层要指定input_dim,输出层要指定units,同时制定初始化方式和激活函数。隐藏层只要指定units个数,初始化方式和激活函数
model.add( Dropout() ):增加一个Dropout层,参数为丢弃概率,取值0-1
model.summary():返回模型的参数
model.compile():定义模型训练方式,可以指定损失函数,优化器,和评估方式
model.fit():开始训练模型,包括输入数据,真实标签,训练数据和验证数据的比例,训练周期,每一批次数据项个数,verbose=2表示显示训练过程
model.evaluate():评估模型的准确率。输入为测试数据输入,测试数据标签。
model.predict():使用模型预测数据,参数为测试数据。
pandas.crosstab():创建混淆矩阵,参数为行的值,列的值,以及行标签和列标签。
pandas.DataFrame():创建DataFrame,输入格式为{'列名字':列的值,...}
Keras卷积神经网络识别手写数字
卷积神经网络与多层感知器的差异
CNN增加了卷积层1,池化层1,卷积层2,池化层2来提取特征。
卷积层的意义
将原本一个图像经过卷积运算产生多个图像,如同相片叠加起来。效果类似滤镜,可以提取不同的特征,如边缘,线条和角等。
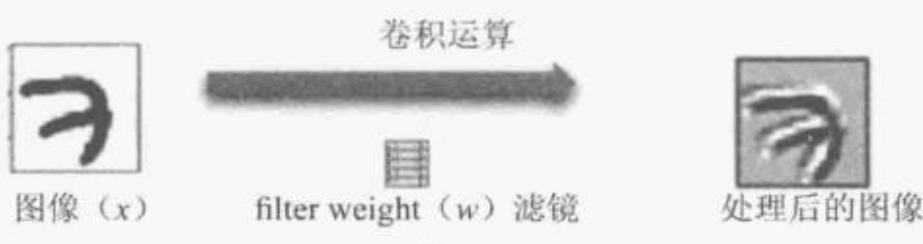
Max-Pool运算说明
可以对图像缩减采样,会将图片缩小,但是不会改变头像的数量。
缩减采样的好处:
-
-
- 减少需要处理的数据点
- 让图像位置差异变小,位置的不同可能影响识别。
- 参数的数量和计算量下降,可以控制过拟合。
-
多次试验,Dropout都取0.25效果最好,准确率达到0.9922
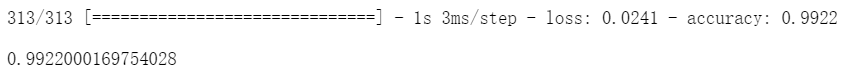
搭建CNN进行手写数字识别
网络结构
卷积层1 -> 池化层1 -> 卷积层2 -> 池化层2 -> Dropout层1 -> 平坦层 -> 隐藏层 -> Dropout层2 -> 输出层
与多层感知器的区别
将图像经过两个卷积层和池化层后,再将将图像平坦化,送入多层感知器。
创建功能函数以及导入相关库
from keras.datasets import mnist
from keras.utils import np_utils
import numpy as np
np.random.seed(10)
from keras.models import Sequential
from keras.layers import Dense,Flatten,Conv2D,MaxPooling2D,Dropout
import matplotlib.pyplot as plt
def show_train_history(train_history,train,validation):#参数为训练产生的历史,训练数据的执行结果,验证数据的执行结果
plt.plot(train_history.history[train])
plt.plot(train_history.history[validation])
plt.title('Train History')#显示标题
plt.ylabel(train)#y轴标签
plt.xlabel('Epoch')#x轴标签是'Epoch'
plt.legend(['train','validation'] , loc='upper left')#图例显示'train','validation',位置左上角
plt.show()
def plot_images_labels_prediction(images,#数字图像
labels,#真实值
prediction,#预测结果
idx,#开始显示的数据index
num=10#要显示的数据项,默认是10,不超过25
):
fig = plt.gcf();#创建图形
fig.set_size_inches(12,14)#设置图形大小
if num>25: num=25 #限制显示的数据项
for i in range(0,num): #画出num个数字图形
ax=plt.subplot(5,5,1+i) #子图为5行5列,每一项索引为1+i
ax.imshow(images[idx],cmap='binary')#ax中国画出下标为idx的图像,图像为二值图
title="label" + str(labels[idx]) #设置标题
if len(prediction)>0: #如果传入了预测结果,就显示预测结果
title+=",predict="+str(prediction[idx])
ax.set_title(title,fontsize=10)
ax.set_xticks([])#设置不显示x刻度
ax.set_yticks([])#设置不显示y刻度
idx+=1
plt.show()数据预处理
(x_Train,y_Train),(x_Test,y_Test) = mnist.load_data() #加载数据集x_Train4D = x_Train.reshape(x_Train.shape[0],28,28,1).astype('float32') #因为图像是灰度图像,所以图像第三维是1,并转换为浮点型
x_Test4D = x_Test.reshape(x_Test.shape[0],28,28,1).astype('float32')
x_Train4D_normalize = x_Train4D / 255 #归一化处理
x_Test4D_normalize = x_Test4D / 255
y_TrainOneHot = np_utils.to_categorical(y_Train) #独热编码处理
y_TestOneHot = np_utils.to_categorical(y_Test)搭建模型
model = Sequential()
model.add(Conv2D(filters=16, #卷积核的个数为16个,会产生16个输出
kernel_size=(5,5), #卷积核的大小
padding='same', #设置填充,让图像保持原大小
input_shape=(28,28,1), #第一第二维都是28,第三维因为图像是灰度图像,所以为1
activation='relu')) #激活函数relu
model.add(MaxPooling2D(pool_size=(2,2))) #加入池化层,池化窗口的大小为2 x 2,2x2会将图像大小减半
model.add(Conv2D(filters=36, #设置36个卷积核,会产生36个输出图像
kernel_size=(5,5), #卷积核的大小为5x5
padding='same', #设置填充后保持原图像大小
activation='relu')) #激活函数为relu
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))#加入Dropout层,随机丢弃25%神经元,防止过拟合。
model.add(Flatten())#建立平坦层,将上一层池化层的输出转换为一维向量,36个7x7图像,也就是36x7x7=1764个float数。对应1764个神经元
model.add(Dense(128,activation='relu')) #隐藏层128个神经元
model.add(Dropout(0.25))
model.add(Dense(10,activation='softmax'))查看模型参数
print(model.summary())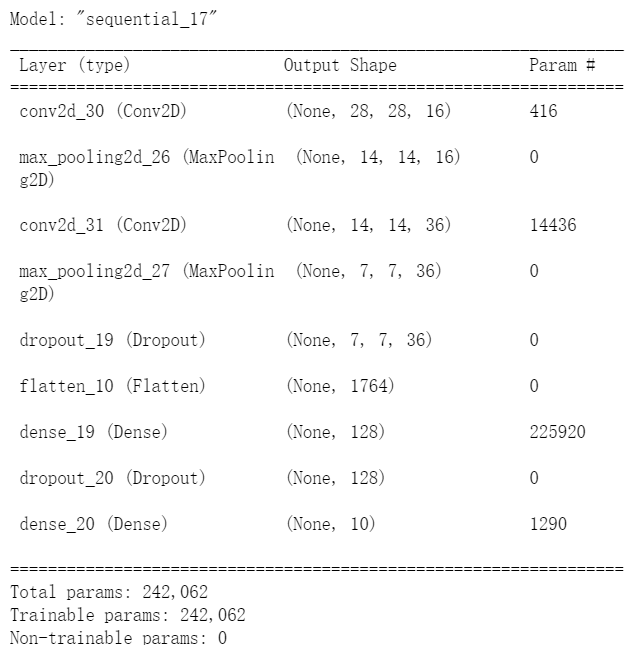
设置训练方式
3个参数,定义损失函数,优化器,评分标准
model.compile(loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])开始训练模型
6个参数,包括输入数据,标签,训练集和验证集比例,训练周期,每一批次的数据个数,是否显示训练过程
train_history = model.fit(x=x_Train4D_normalize,
y=y_TrainOneHot,
validation_split=0.2,
epochs=10,
batch_size=300,
verbose=2)
显示模型正确率
注意:在tensorflow2.0一下版本,准确率的标签是'acc',验证集上的准确率标签是'val_acc',在Tensorflow2.0以上版本则分别是'accuracy'和'val_accuracy'
show_train_history(train_history,'accuracy','val_accuracy')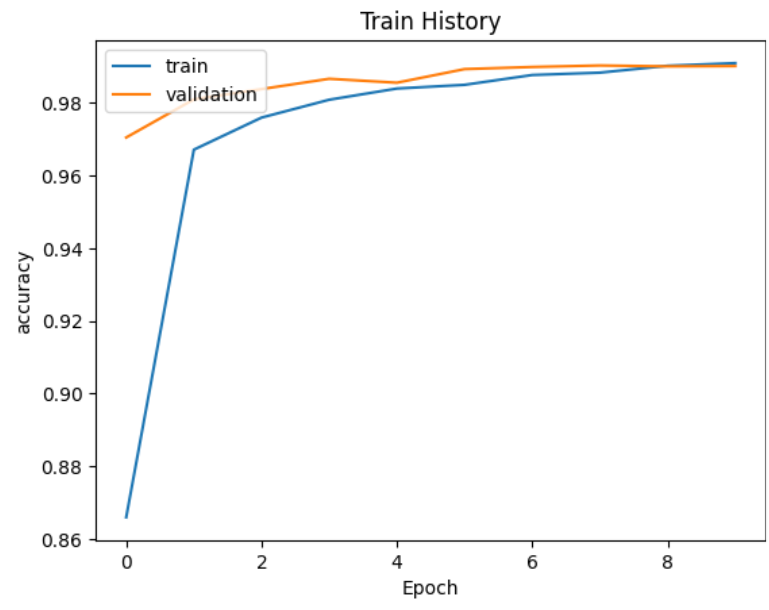
显示模型损失
show_train_history(train_history,'loss','val_loss')
评估模型
使用测试数据评估模型准确率
socres=model.evaluate(x_Test4D_normalize,y_TestOneHot)
socres[1] ![]()
使用模型预测数据,并显示预测结果
prediction = model.predict(x_Test4D)
prediction=np.argmax(prediction,axis=1)
prediction[:10]![]()
绘制图像,比较预测值和真实值
plot_images_labels_prediction(x_Test,y_Test,prediction,idx=0)
建立混淆矩阵
import pandas as pd
pd.crosstab(y_Test,prediction,
rownames=['label'],
colnames=['prediction']) 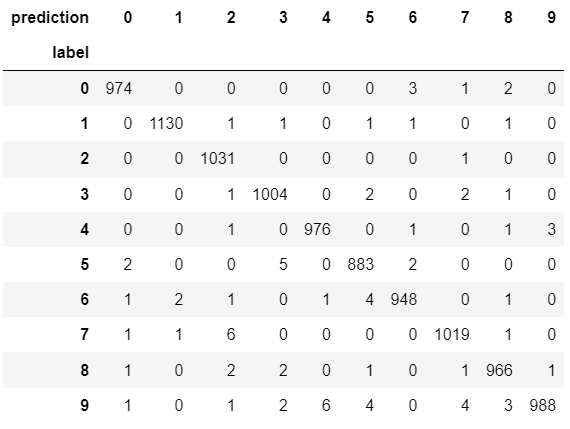
本文来自博客园,作者:Laplace蒜子,转载请注明原文链接:https://www.cnblogs.com/RedNoseBo/p/17161827.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号