

神经网络
神经网络基本概念
神经元基本结构
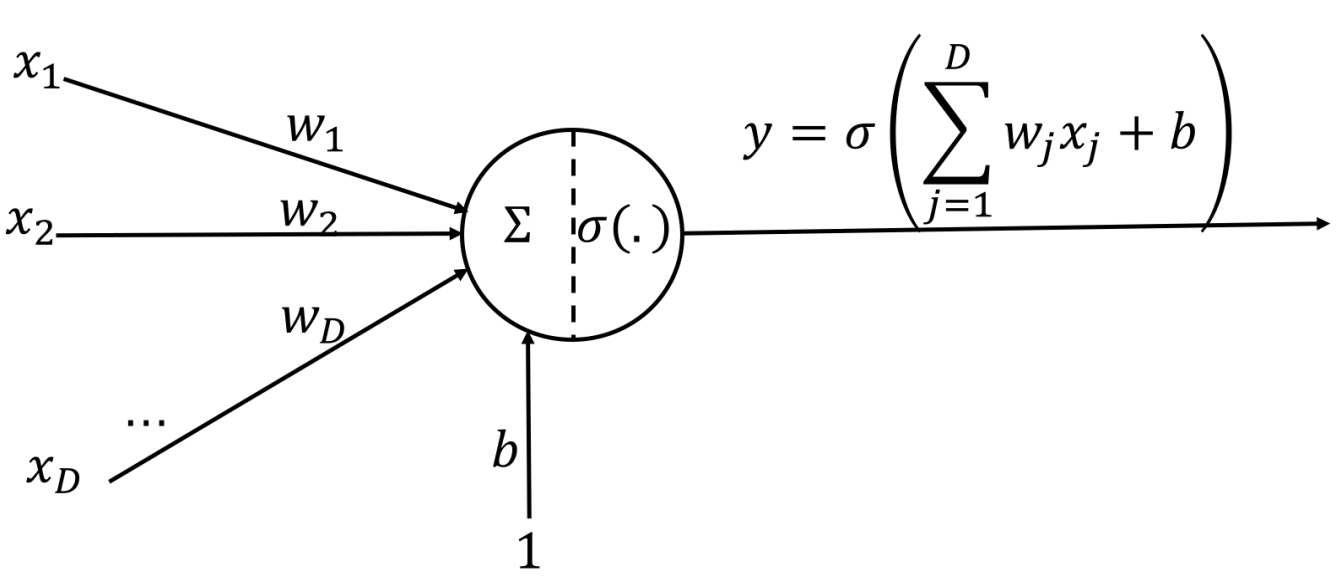
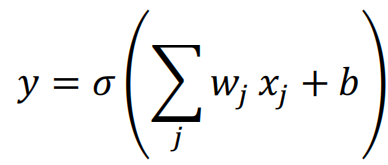
σ为激活函数,w为权重,x为输入,b为偏置项。
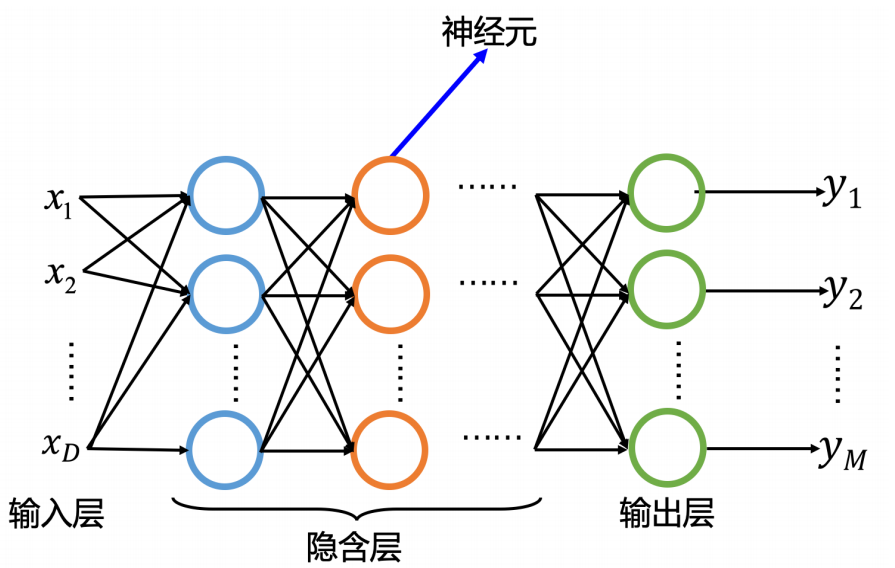
前馈全连接神经网络
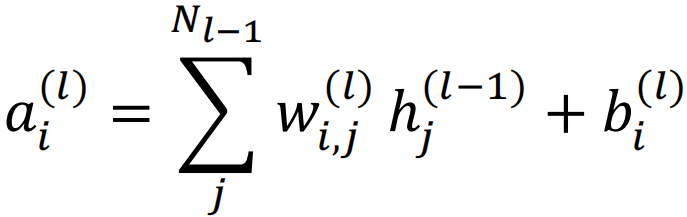
![]()
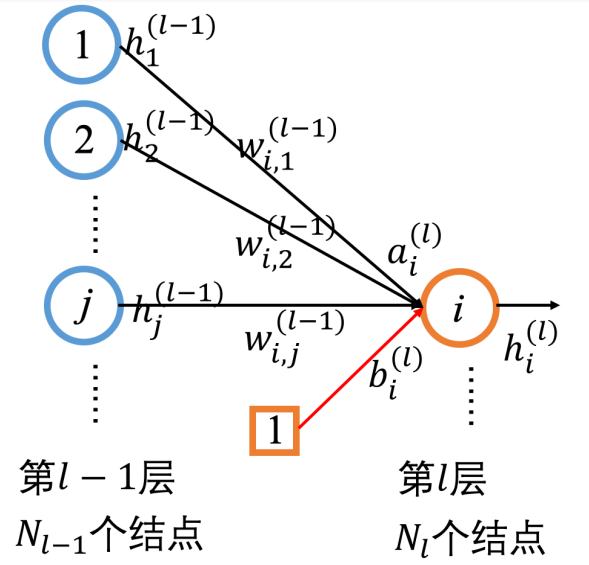
ai(l)表示第l层第i个神经元的输出,向量a(l)表示第l层所有神经元的输出;
wi,j(l)表示第l-1层第j个神经元到第l层第i个神经元之间连接权重。向量W(l)表示第l-1层神经元到第l层神经元之间的连接权重。
bi(l)表示第l层第i个神经元的偏置,向量b(l)表示第l层所有神经元的偏置。
hi(l)表示第l层第i个神经元经过激活函数的输出。向量h(l)表示第l层所有神经元经过激活函数的输出。
向量矩阵写法:
![]()
![]()
卷积神经网络(CNN)
属于前馈神经网络,至少包含一个卷积层。
特点
非全连接:卷积层的输入和输出之间不是全连接,输出节点只和一部分输入节点连接。
权值共享:不同位置的输出节点与输入节点的连接权重相等
应用方面
经常用来处理具有网格结构的数据,如时间序列数据,图像数据。
典型结构
卷积层:提取信号中局部特征;
池化层:降低分辨率/扩大感受野,大幅度降低参数量(降维)
全连接层:同传统全连接神经网络,用于输出结构。
卷积层
卷积定义
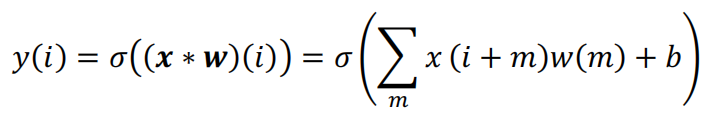
卷积是一种线性运算。用于提取局部特征。CNN中,卷积核w是通过学习得到的。σ(.)为激活函数。b为卷积的偏置项。
如果输入是二维图像,那么卷积核也是二维的。
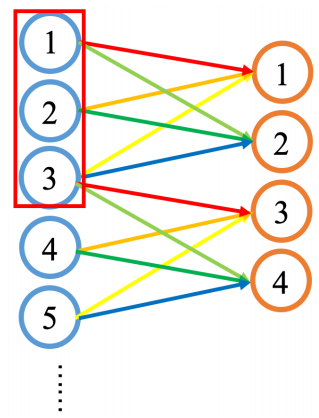
如图所示,卷积层的神经元与前一层神经元是局部连接,只连接了3个,称卷积的感受野为3。卷积层权值是共享的,图中输出神经元1和3的权重相同,2和4相同。
卷积层采用局部连接和权值共享使得参数大大减少,预防模型过拟合。
填充
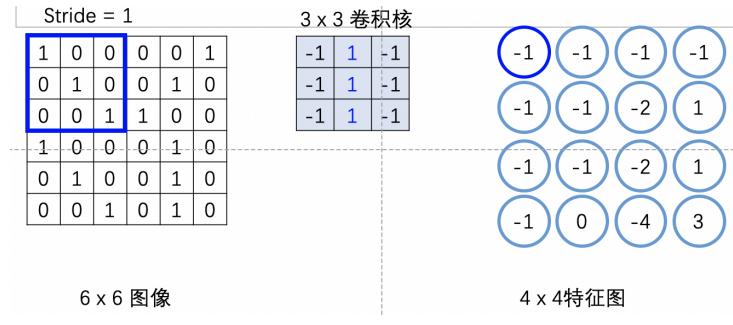
不填充产生的问题:如给定一个6 X 6的图像,若用步幅为1的3 X 3卷积后,最终得到大小为4 X 4的图像,输出图像变小。
填充就是通过在图片外围补充一些像素点,扩充输入图像,填充区域越大,输出特征越大。
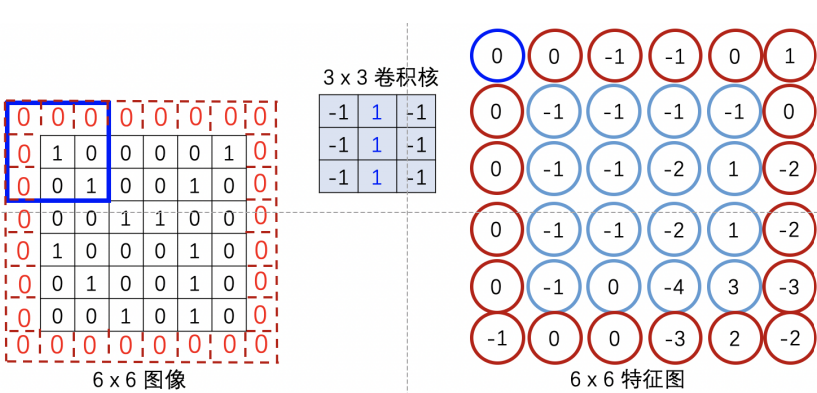
输出特征图宽度W2与输入图像宽度W1的关系:
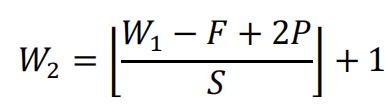
F:卷积核宽度。
P:单边填充区域宽度
S:步幅
池化层
池化实际上是一种采样。池化可以使得特征具备一定的平移不变性,也可以迅速减少特征维度,在一定程度上控制了过拟合。
由于池化层会快速减少数据的维度,因此CNN通常在多个卷积之后插入池化层,甚至不再使用池化层。
最大池化和平均池化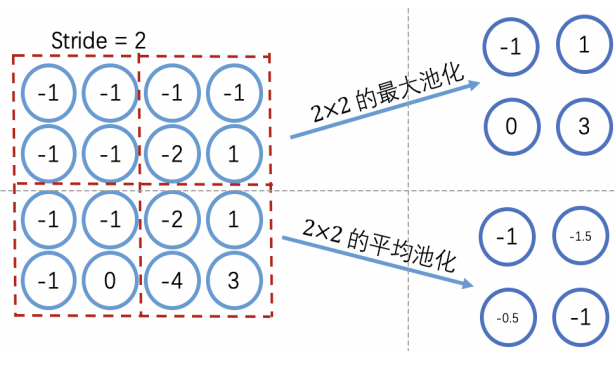
一般最大池化表现更好。
AlexNet
模型AlexNet是2012年ImageNet比赛冠军
结构
共有9层,前5层是卷积层,后面3层是全连接层,最后是输出层。
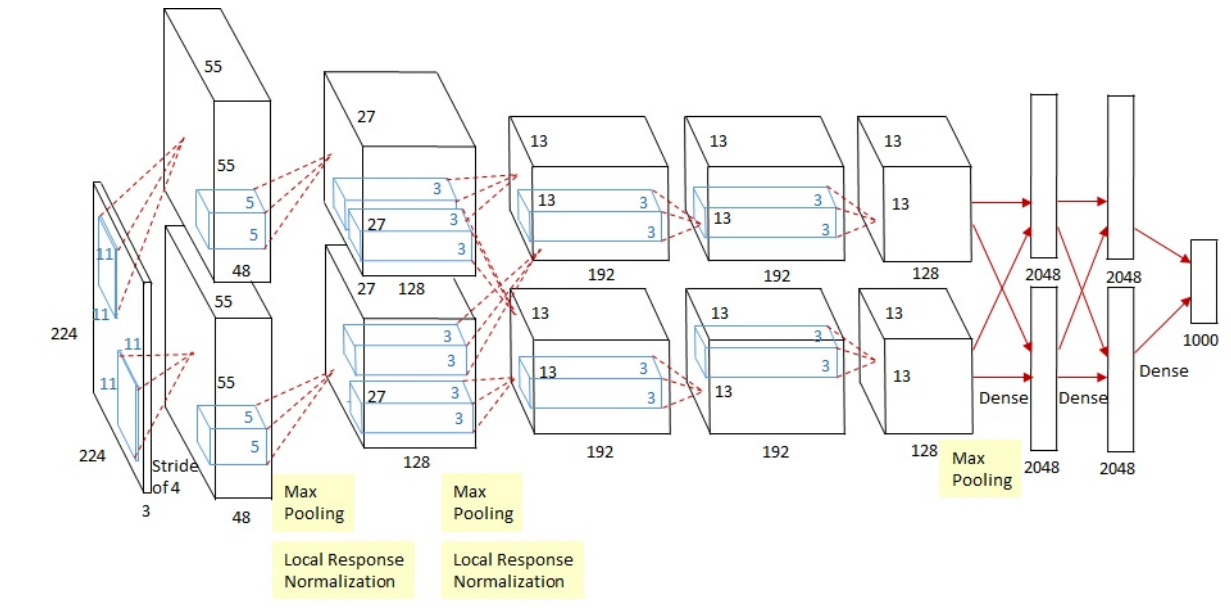
网络结构分为上下两部分,一个GPU运行图上方的层,另一个运行图下方的层,两个GPU只在特定层通信(第2个,第5个卷积层,全连接层)。
第2层,第4层,第5层卷积层的核只和同一个GPU上前一层的核特征图相连,第3层则是和第2层所有的核特征图相连接。
第一个卷积层处理方式
卷积
输入原始图像大小为227 x 227 x 3。本层使用96个 11 x 11 x 3的卷积核进行卷积运算。因为使用了两个GPU,所以每个GPU分别承担了48个卷积核运算。卷积核步幅为4。
根据公式卷积后输出特征大小为:w2=(227-11+2x0)/4+1=55。
激活层
采用的激活函数是ReLU
池化
AlexNet采用的是重叠池化,避免了信号维度缩减过快。重叠池化类似于卷积,但是求得是最大值或平均值,AlexNet使用的是最大池化。步幅为2池化后图像的尺寸为(55-3+2x0)/2+1=27。
归一化
因为前一个步骤使用了ReLU,ReLU的响应结果可能非常大,所以需要归一化处理,AlexNet采用的是局部归一化LRN,利用邻域数据做归一化。
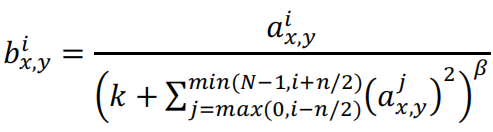
a,b分别表示输出,是一个三维数组[高,宽,通道]。x,y表示输入的空间位置索引,i为通道索引,N表示通道总数,n/2表示求和的通道半径,k表示求和的通道偏置。AlexNet中,k=2,n=5,β=0.75,α=10-4。
后面层次处理方式
第二个卷积层:卷积->ReLU->池化->归一化。
第三个和第四个卷积层:卷积->ReLU。
第五个卷积层:卷积->ReLU->池化。
第六层全连接层:fc(全连接)->ReLU->Dropout(随机丢弃x%结点,使被丢弃的结点其输出为0)。
第七层全连接层:fc->ReLU->Dropout。
第八层为全连接层:fc->Softmax。Softmax完成图像分类。
循环神经网络(RNN,Recurrent Netural Network)
用于多个输入之间或多个输出之间有依赖关系的场景。
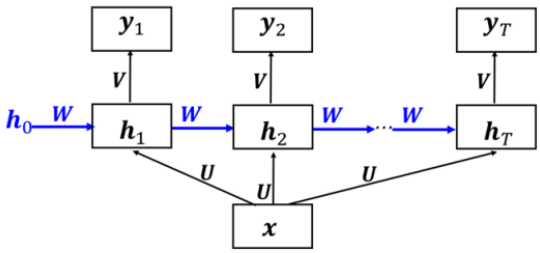
简单循环神经网络
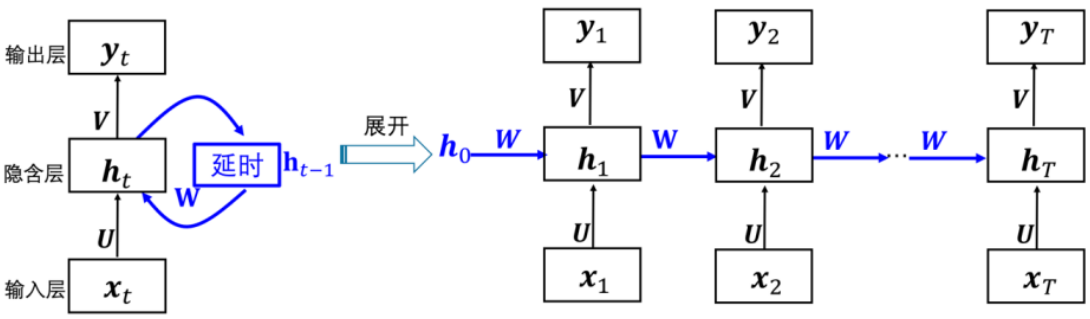
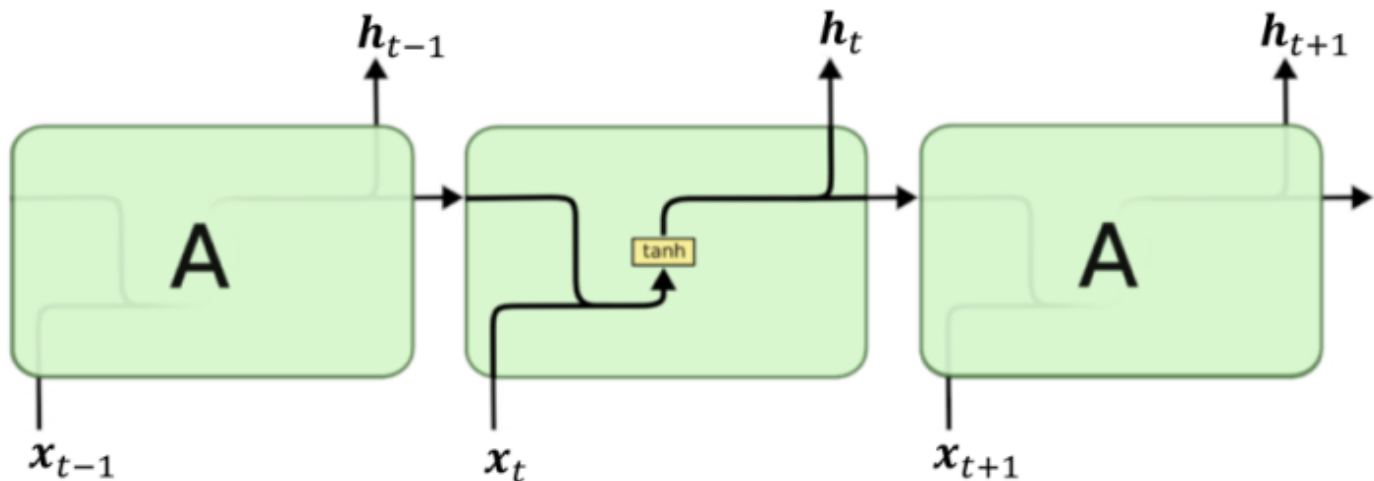
RNN存储先前时刻输入对应的隐含状态ht-1,并且与当前输入(xt)结合,保持当前输入与先前输入的关系。
计算方法
![]()
![]()
f通常为tanh激活函数,g通常为Sigmoid函数或Softmax函数。向量ht表示第t个隐藏层所有神经元。U是输入层到隐藏层的权重矩阵,W是相邻隐藏层之间的权重矩阵,V是隐藏层到输出层的权重矩阵。
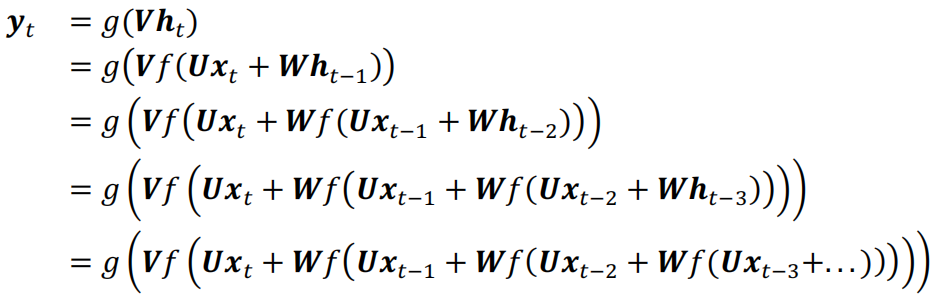
“循环”在于一个序列的当前输出与前面的输出有关。展开可以看到当前输出值yt受到前面xt,xt-1,...的影响。
RNN变种
序列输入,单值输出:
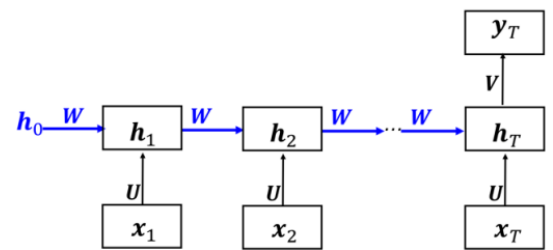
单值输入,序列输出:
长短时记忆网络(LSTM,Long Short-Term Memory)
优点
RNN在反向传播更新参数时,会产生梯度消失或梯度爆炸问题。长短时记忆网络可以解决此问题。
与RNN结构对比
RNN结构:
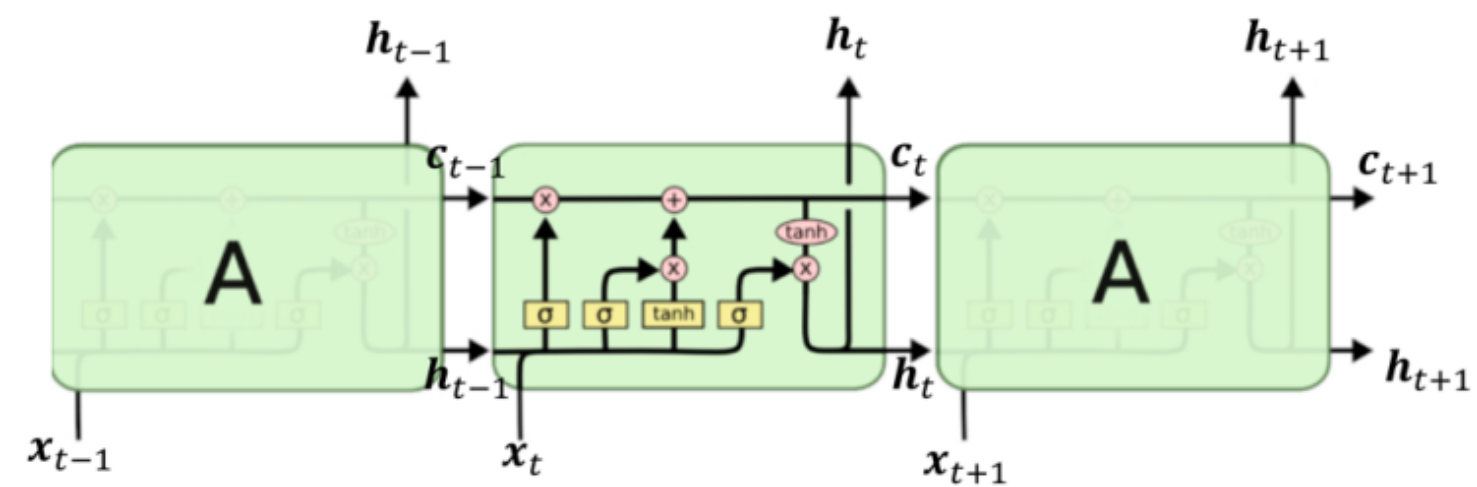
LSTM结构:
![]()
遗忘门(Forget Gate Layer)
LSTM第一步就是决定要丢弃那些信息,遗忘门用于丢弃信息。
遗忘门计算公式:
![]()
两个输入,ht-1是前一个单元的隐藏状态,xt为当前时间的输入。σ是Sigmoid函数,Sigmoid函数会将计算结果映射为0到1区间的数。0表示完全遗忘,1表示完全保持。
输入门层(Input Gate Layer)
LSTM第二步要决定存储的新信息(更新单元状态)。
输入门层计算公式:
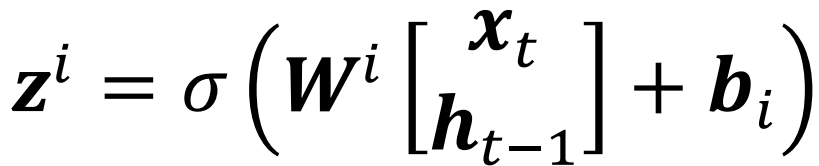
可以使用一个tanh创建一个 可以被添加到新状态中的新候选值,用向量z表示:
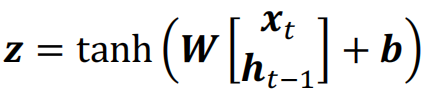
ht-1是前一个单元的隐藏状态,xt为当前时间的输入。σ为Sigmoid函数。
结合两个门对单元状态进行更新
![]()
ct-1是旧的单元状态,zf是遗忘门,zi是输入门,z是候选值。将旧的状态乘以遗忘门,决定要忘记那些东西,然后向新的状态中添加zi⊙z
输出门层(Out Gate Layer)
LSTM最后要决定输出的信息(输出更新后的信息,更新隐藏状态)。
通过Sigmoid函数决定要输出单元状态的哪些部分:
![]()
ht-1是前一个单元的隐藏状态,xt为当前时间的输入。σ为Sigmoid函数。
让过滤后的单元状态通过tanh,乘以Sigmoid门的输出:
![]()
这样一来,当前状态的隐藏状态和单元状态都已经更新。
总的计算过程为:
遗忘门筛选不必要的信息;输入层用 候选值 更新单元状态。输出层输出,用输出和单元状态更新隐藏状态。
门控循环单元(GRU)
是LSTM的变形。GRU将将遗忘门和输入门组合成了一个单一的更新门,合并了单元状态和隐藏状态。
计算过程:
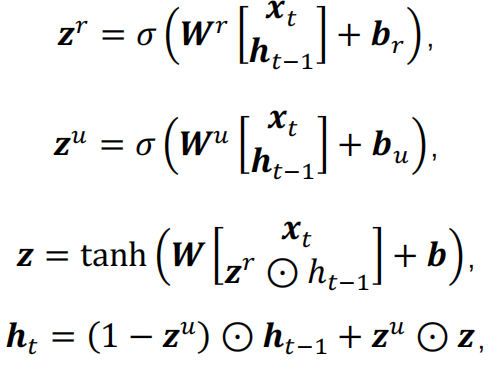
zr是重置门,决定是否将之前的状态遗忘(相当于遗忘门和输入门),zr趋于0,前一时刻隐藏状态被遗忘,被重置为当前输入的信息z;
zu是更新门,决定是否要将隐藏状态更新为新的状态z(相当于LSTM输出门);
本文来自博客园,作者:Laplace蒜子,转载请注明原文链接:https://www.cnblogs.com/RedNoseBo/p/17149183.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号