
集成学习
集成学习
产生原因
已经开发了很多机器学习算法,单个模型的性能已经调到了最优,很难在改进。
基本框架
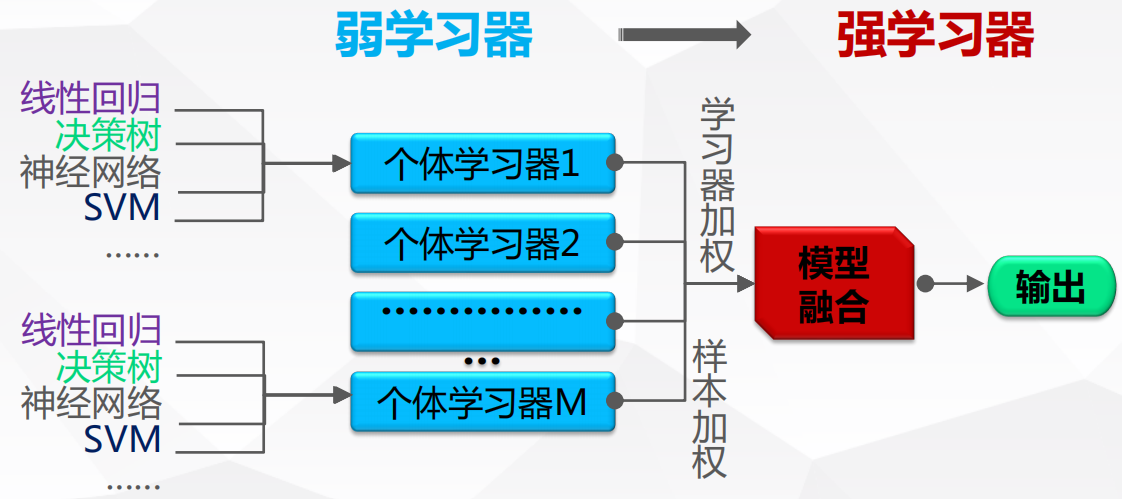
将多个弱学习器进行融合,通过样本加权,学习器加权,获得比单一学习器性能更加优越的强学习器。
Bagging(Bootstrap aggregating)
Bootstrap采样
给定包含N个样本的数据集D,随机取出一个样本放入采样集,再把该样本放回数据集D,经过N次采样,获得包含N个样本的采样集D1,称为bootstrap样本。
若原始样本为D={A,B,C,D,E}
则bootstrap样本可能为
D1={A,B,B,D,E}
D2={A,C,D,D,E}
原训练集中约有63.2%的样本出现在采样集中。
Aggregating
aggregating是指集成学习器的预测结果为多个训练好的基学习器预测结果的平均或投票。
对采样集D1进行训练得到基学习器f
将M个基学习器进行组合,得到集成模型
通常分类任务采取简单的投票法,取多个基学习器的预测类别的众数。(类别取众数)
通常回归任务采取简单平均法,取多个基学习器的预测值的平均。(预测值取平均)
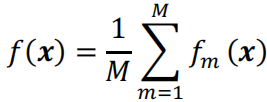
基学习器数目的选择
在实际应用中可以根据特征维数D简单的设置基学习器数目
对于分类问题,基学习器数目通常为D1/2。
对于回归问题,基学习器数目通常为D/3。
适用范围
Bagging适合对偏差低,方差高的模型进行融合。如决策树,神经网络。
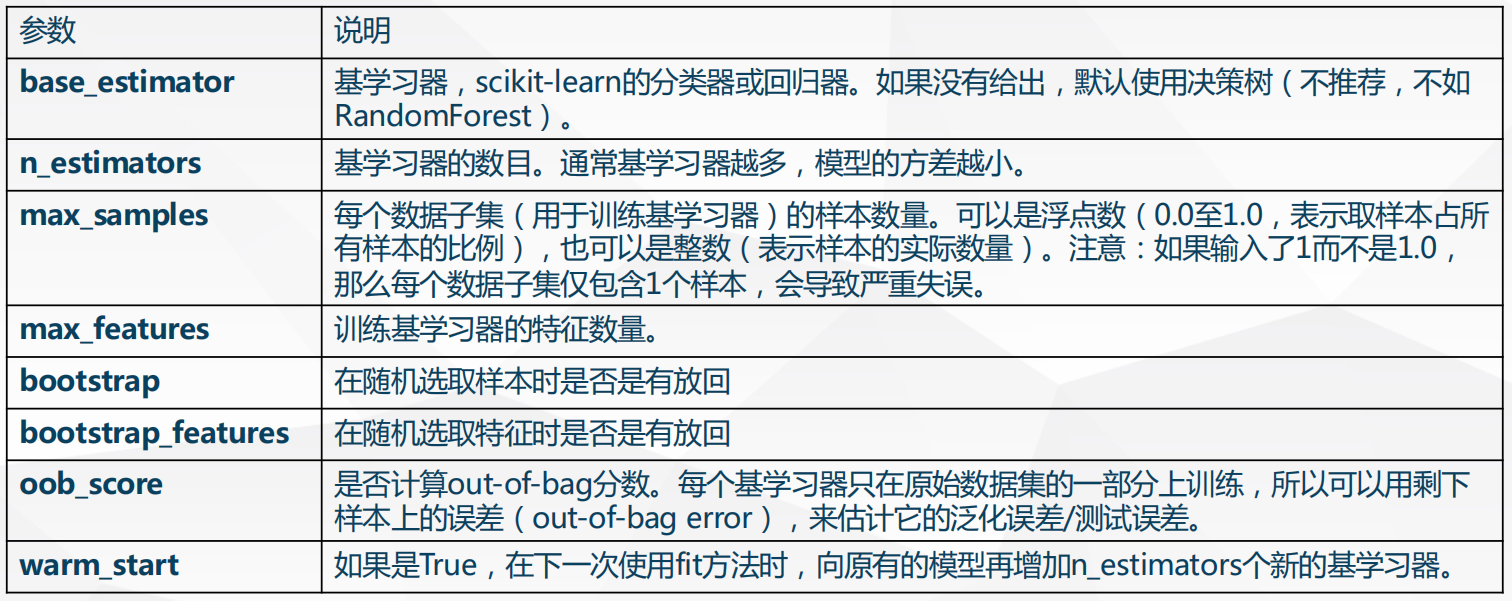
BaggingClassifier的参数

随机森林
是一种弱学习器为决策树的Bagging算法
优点
-
-
- 简单,容易实现。
- 训练效率高,单个决策树只需要考虑所选的属性和样本的子集。
- 多棵决策树可并行训练。
- 实际应用中效果好。
- 随着树的数量增加,随机森林可以有效缓解过拟合。
-
Scikit-Learn中的实现类
随机森林分类:RandomForestClassifier
随机森林回归:RandomForestRegression
极端随机森林分类:ExtraTreesClassifier
极端随机森林回归:ExtraTreesRegressor
随机森林和极端随机森林比较
在分裂时,RandomForest寻找特征最佳阈值;
ExtraTrees随机选取每个候选特征的一些阈值,进一步选取最佳阈值。
当特征可选划分阈值很多时,ExtraTrees训练更快,在大数据集上,二者的性能差异不大。
Boosting
将弱学习器组合成强分类器,因为构造一个强学习器是一件很困难的事情,但是构造一个弱学习器并不困难(性能比随机猜测略好)。
Boosting学习框架
学习第一个弱学习器Ф1
学习第二个弱学习器Ф2,Ф2要能帮助Ф1(Ф2和Ф1互补)
...
组合所有的弱学习器:![]()
获得互补的学习器方法
可以在不同的训练集上训练学习器。
可以对原始训练集重新采样,或者对原始训练集重新加权获得不同的训练集。实际操作中只需要改变目标函数即可。

AdaBoost的基本思想
在弱学习器Ф1失败的样本上,学习第二个弱学习器Ф2
分类对的样本,权重减小。
分类错的样本,权重增大。
梯度提升
提升的基本思想
找一个弱学习器来改进目标函数。
提升的算法流程
初始化f0(x);
for m=1:M do
找一个弱学习器Фm(x),使得Фm(x)能改进fm-1(x);
更新:fm(x)=fm-1(x)+Фm(x);
return fM(x)
L2提升(L2Boosting)
取损失函数为L2损失就得到了L2损失的梯度提升算法。
![]()
若目标函数只考虑训练误差,那么目标函数就是L2损失:
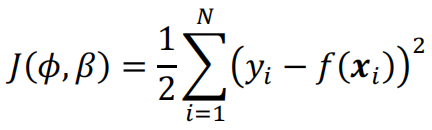
目标函数的梯度为:
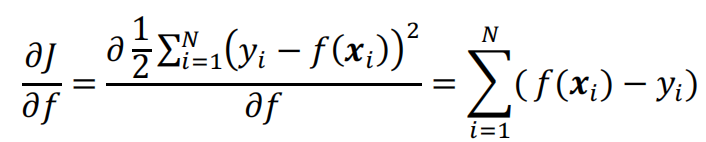
基本思想
对目标函数求梯度,找一个学习器,使得其与梯度差值最小,也就是不怎么改变梯度。
L2Boosting算法
初始化:![]() ,样本均值离所有样本的平均距离平方和最小。
,样本均值离所有样本的平均距离平方和最小。
for m=1:M do
计算目标函数负梯度(对目标函数求导,梯度取负):
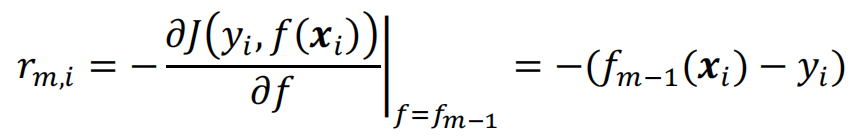
找一个弱学习器Фm(x),使得![]() 最小。(使得梯度变化最小)
最小。(使得梯度变化最小)
更新:fm(x)=fm-1(x)+βmФm(x),其中βm为学习率。
return fM(x)
XGBoost
基本原理
相较于传统的梯度提升,XGBoost在目标函数中引入了控制模型复杂度的正则项R(f)。
目标函数
![]()
其中R(f)是正则项
当若学习器为决策树时,正则项可以包含L1正则和L2正则,此时正则项R(f)为
![]()
T为叶子节点数目,wt为叶子节点的分数,γ和λ分别为L1正则和L2正则的权重。
XGBoost损失函数
传统的GBDT算法中,采用的是梯度下降,优化时只用到了一阶导数。
XGBoost采用二阶泰勒展开近似损失函数,所以XGBoost也被称为牛顿提升法。
![]()
在第m步时,对损失函数求一阶导数:
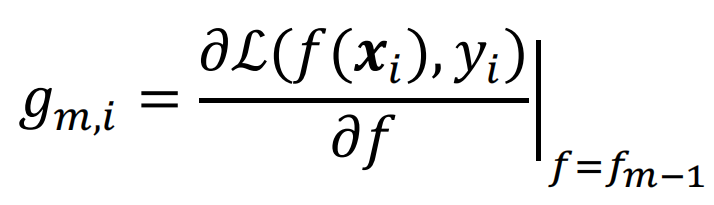
在第m步时,对损失函数求二阶导数:
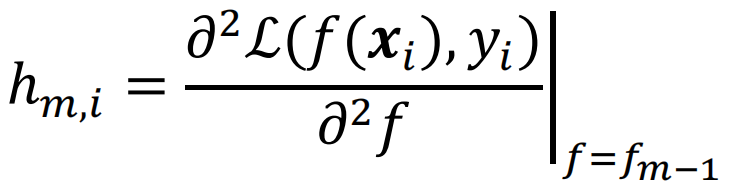
损失函数L在fm-1处展开得到
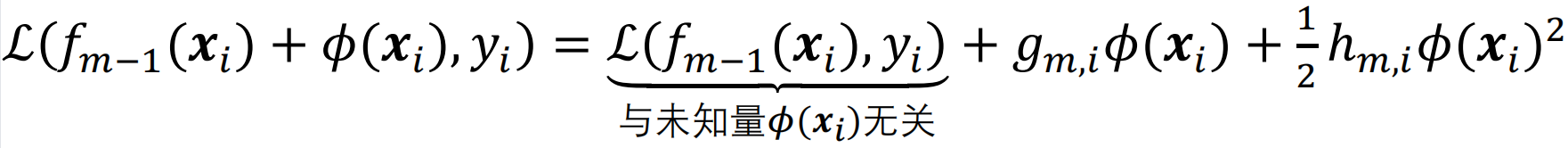
忽略Ф(xi)无关的量,得到损失函数:
![]()
L2损失的XGBoost
若损失函数采用L2损失
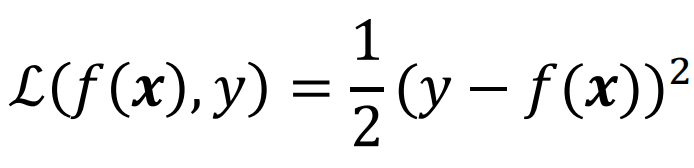
![]() ,
,![]()
![]() ,
,![]()
采用L2损失的损失函数
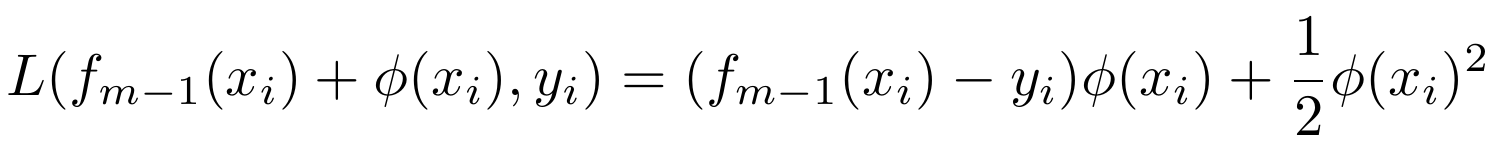
最佳叶子节点分数
XGBoost中,弱学习器采用二叉的回归决策树。对于输入x,弱学习器的预测为Ф(x),即x所在的叶子节点的分数为:
Ф(x)=wq(x),q:RD → {1,...,T},q为结构函数,将输入x映射到叶子的索引号,w为指定索引的叶子节点的分数,T为树中叶子节点的数目,D为输入特征的维数
所以对于弱学习器的预测值,可以直接通过Ф(x)=wq(x),映射到所得分数,从而在目标函数中直接使用分数
且令每个叶子节点t上的样本集合为:It={i|q(xi)=t}
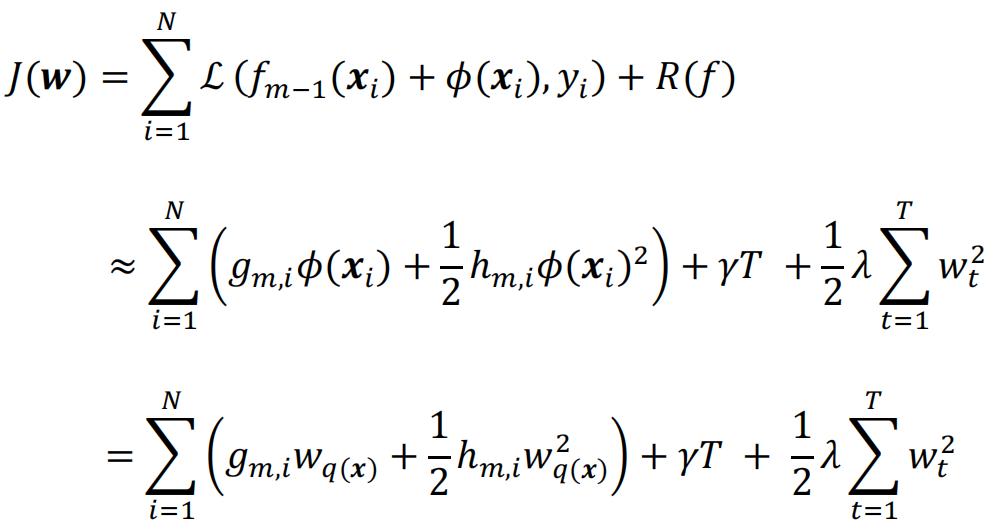
q是结构函数,能够将输入x映射到叶子节点上,而叶子节点又用t表示,所以t=q(x)
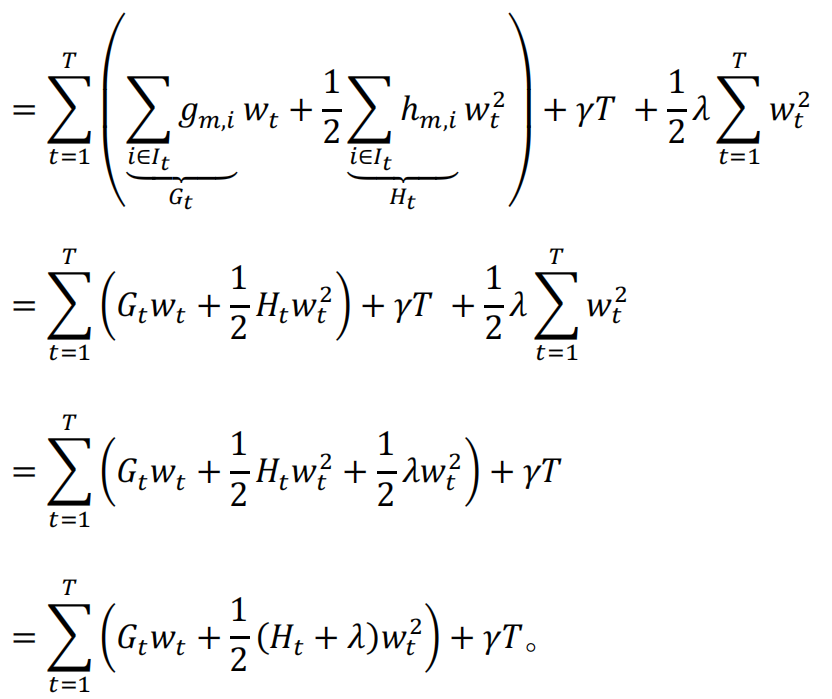
对wt求导得:
![]()
最佳wt对应的目标函数为
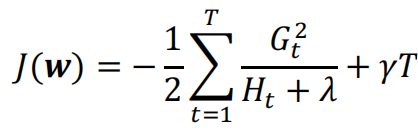
最佳树结构
最佳的树结构应当使得目标函数J最小,采用启发式规则的贪心建树。
对于树的每一个节点,尝试增加一个分裂。
对当前节点中样本集合D中的每个样本,若该样本的特征值小于等于阈值,划分到左叶子节点;否则划分到右叶子节点。
令DL和DR分别表示分裂后左右叶子节点的样本集合
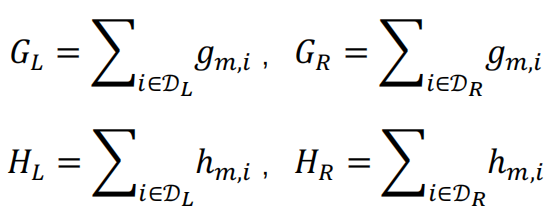
则增加这次分裂后所带来的收益为
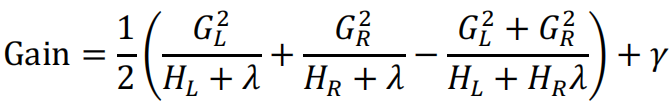
Gain是正数,值越大,则分裂后的目标函数值变小了,表示越值得分裂。
Gain是负数,则分裂后目标函数反而变大了,得不偿失。
穷举法
1. 初始化增益和梯度统计信息:
![]()
2. 对所有特征按照特征的数值排序
3. 对于每个特征 j=1 to D,执行如下操作:
3.1 初始化左子节点的梯度统计信息:GL=0,HL=0
3.2 对当前节点的所有样本按照特征值j的数值排序,取第i个样本的特征值xik作为阈值,计算左右叶子节点的梯度统计信息和分裂增益,并记录增益最大的分裂:
GL=GL+gi,HL=HL+hi。#分裂后左叶子节点
GR=G-GL,HR=H-HL。#分类后右叶子节点
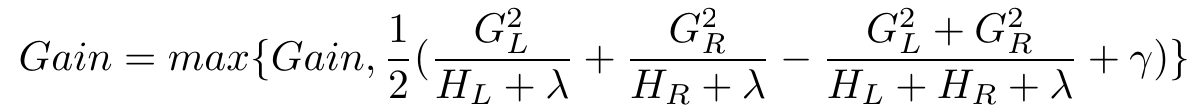
4. 按最大增益对应的分裂特征和阈值进行分裂
XGBoost所做的优化
对缺失值的处理。
在特征粒度上并行。
根据特征直方图近似寻找最佳分裂点。
LightGBM
特点
基于直方图分裂
直方图加速构造
带深度限制的Leaf-wise的叶子生长策略
直接支持类别型特征
Cache命中率优化
多线程优化
基于直方图分裂
-
-
- 把特征值离散化成K个整数
- 构造一个箱子(bin)数为K的直方图
- 遍历数据时,根据特征值离散化后得值作为索引在直方图中累积统计量。
- 根据直方图的离散值,遍历寻找最优的分割点。
-
直方图算法优势
大幅度减少计算分割点增益的次数
直方图算法缺点
训练误差没有预排序算法好
直方图做差加速
一个叶子的直方图等于父节点的直方图与其兄弟节点的直方图的差值。
带有深度限制的按叶子生长算法
Level-wise过一次数据可以同时分裂同一层的叶子,容易进行多线程优化,不容易过拟合。
但是Level-wise不加区分的对待同一层的叶子,带来了很多没必要的开销。
Leaf-wise每次从当前所有叶子中,找到分裂增益最大的一个叶子进行分裂。
Leaf-wise的缺点是可能会生长出比较深的决策树,产生过拟合。因此LightGBM在Level-wise之上增加了一个最大深度的限制,防止过拟合。
直接支持类别型特征
大多数机器学习工具无法直接支持类别型特征,需要进行转化,降低了空间和时间效率。
LightGBM优化了对类别型特征的支持,直接输入类别特征,不需要额外转换,并在决策树算法上增加了类别型特征的决策规则。
Stacking
Stacking是一种分层结构
二层Stacking:
将训练好的基模型对训练集进行预测
在新的训练集上训练模型,在新的测试集上进行预测
Bagging,Boosting,Stacking区别
同质的个体学习器,低偏差高方差,用并行的方法结合成的Bagging
同质的个体学习器,高偏差低方差,用序列的方法结合成的Boosting
异质的个体学习器,低偏差高方差,用分堆的方法结合成的Stacking
本文来自博客园,作者:Laplace蒜子,转载请注明原文链接:https://www.cnblogs.com/RedNoseBo/p/17096869.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号