

CUDA C++ / 并发CUDA流
计算与传输重叠
工作模式
CPU与GPU之间交互有两个引擎:
-
-
- 内存复制引擎:负责CPU和GPU之间的数据传输。
- 核函数执行引擎:负责CPU向GPU部署核函数任务。
-
这两个引擎是相互独立的,可以并发执行。
查看是否支持
cudaGetDeviceProperties()函数,通过deviceOverlap属性查看计算机是否支持计算与传输重叠功能。
注意PCle是双通的,也就是一个流在执行核函数的时候,一个流可以从主机向设备传输数据,另一个流也可以同时从设备向主机传输数据。
流
在一个流中,所有指令必须在下一个流开始之前完成,所有流中核函数均按顺序执行。
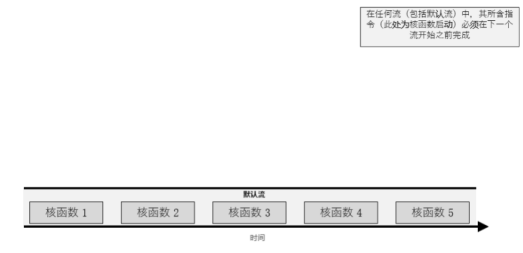
默认流
在启动核函数的时候不指定流,则核函数在默认流中执行。默认流会阻止其他流中的所有核函数。
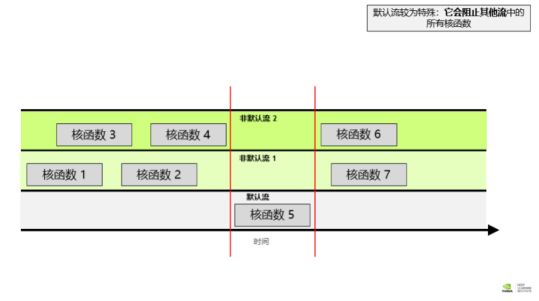
非默认流
启动核函数之前创建流,并启动核函数的时候指定在该流中执行。
控制CUDA流行为的规则
-
-
- 给定流中的所有操作会按序执行。
- 不同的非默认流无法保证它们之间按照顺序实行。
- 默认流具有阻断能力,即,它会等待其它已在运行的所有流完成当前操作之后才运行,但在其自身运行完毕之前亦会阻碍其它流的运行。
- 不同的非默认流中的核函数可以同时交互。
-
使用案例
使用cudaStreamCreate()函数创建3个流
在3个流上使用cudaMemcpyAsync()函数将主机数据异步传输到设备中;
在3个流上执行核函数
在3个流上利用cudaMemcpyAsync()函数将设备数据异步传输到主机中。
利用cudaStreamSynchronize()和cudaDeviceSynchronize()函数对3个流进行同步。
利用cudaStreamDestroy()函数销毁3个流。
注意:使用cudaMemcpyAsync()函数传输数据时,必须使用cudaMallocHost()或cudaHostAlloc()分配主机内存(内存必须固定)
同一个流内不能实现计算和传输重叠,因为一般一个流上核函数的执行依赖于传输的数据。
可以创建多个非默认流,然年在不同的流中并发执行多个核函数。
流操作
创建非默认流
函数:cudaStreamCreate(cudaStream_t &stream);
使用案例:
cudaStream_t stream
cudaStreamCreate(&stream)在非默认流中启动核函数
函数:核函数第三个参数为0,第四个参数为需要启动的流。
使用案例:
cudaStream_t stream
cudaStreamCreate(&stream)
KernelFunction<<<blocks,threads,0,stream>>>();销毁非默认流
函数:cudaStreamDestroy(cudaStream_t stream);
使用案例:
cudaStream_t stream
cudaStreamCreate(&stream)
KernelFunction<<<blocks,threads,0,stream>>>();
cudaStreamDestroy(stream);主机数据复制到指定流
cudaMemcpyAsnc(target,source,size,cudaMemcpyHostToDevice,streamId);
从指定流复制数据到主机
cudaMemcpyAsnc(target,source,size,cudaMemcpyDeviceToHost,streamId);
本文来自博客园,作者:Laplace蒜子,转载请注明原文链接:https://www.cnblogs.com/RedNoseBo/p/17083298.html


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 震惊!C++程序真的从main开始吗?99%的程序员都答错了
· 【硬核科普】Trae如何「偷看」你的代码?零基础破解AI编程运行原理
· 单元测试从入门到精通
· 上周热点回顾(3.3-3.9)
· winform 绘制太阳,地球,月球 运作规律