大型数据库应用技术课堂测试05
题目:
Result文件数据说明:
Ip:106.39.41.166,(城市)
Date:10/Nov/2016:00:01:02 +0800,(日期)
Day:10,(天数)
Traffic: 54 ,(流量)
Type: video,(类型:视频video或文章article)
Id: 8701(视频或者文章的id)
1、 数据清洗:按照进行数据清洗,并将清洗后的数据导入hive数据库中。
两阶段数据清洗:
(1)第一阶段:把需要的信息从原始日志中提取出来
ip: 199.30.25.88
time: 10/Nov/2016:00:01:03 +0800
traffic: 62
文章: article/11325
视频: video/3235
(2)第二阶段:根据提取出来的信息做精细化操作
ip--->城市 city(IP)
date--> time:2016-11-10 00:01:03
day: 10
traffic:62
type:article/video
id:11325
(3)hive数据库表结构:
create table data( ip string, time string , day string, traffic bigint,
type string, id string )
2、数据分析:在HIVE统计下列数据。
(1)统计最受欢迎的视频/文章的Top10访问次数 (video/article)
(2)按照地市统计最受欢迎的Top10课程 (ip)
(3)按照流量统计最受欢迎的Top10课程 (traffic)
步骤1:
由于不会使用MySQL格式化数据格式所以使用Java程序将数据提出清洗存入Arraylist再导入新表。
import java.sql.*; import java.util.ArrayList; public class test002 { public static void main(String[] args) { try { Class.forName("com.mysql.jdbc.Driver"); } catch (ClassNotFoundException e) { throw new RuntimeException(e); } Connection conn=null; try { conn= DriverManager.getConnection("jdbc:mysql://localhost:3306/test03","root","zber1574"); } catch (SQLException e) { throw new RuntimeException(e); } String sql="select * from data"; try { ArrayList<beanlist> temp=new ArrayList<beanlist>(); PreparedStatement pt=conn.prepareStatement(sql); ResultSet rs=pt.executeQuery(); while(rs.next()){ String c=rs.getString("ip"); String time=rs.getString("time"); String day=rs.getString("day"); String traffic=rs.getString("traffic"); String type=rs.getString("type"); String id=rs.getString("id"); String[]a=c.split("\\."); String ip=""+a[0]+"."+a[1]; beanlist temp1; temp1 = new beanlist(ip,time,day,traffic,type,id); temp.add(temp1); } add a=new add(); for(int i=0;i<temp.size();i++){ String sql1="INSERT INTO data2 (ip,time,day,traffic,type,id) VALUES('"+temp.get(i).getIp()+"','"+temp.get(i).getTime()+"','"+temp.get(i).getDay()+"',"+temp.get(i).getTraffic()+",'"+temp.get(i).getType()+"','"+temp.get(i).getId()+"')"; a.insert(sql1); System.out.println(i); } } catch (SQLException e) { throw new RuntimeException(e); } } }
import java.sql.Connection; import java.sql.DriverManager; import java.sql.PreparedStatement; import java.sql.SQLException; public class add { public void insert(String sql) throws SQLException { try { Class.forName("com.mysql.jdbc.Driver"); } catch (ClassNotFoundException e) { throw new RuntimeException(e); } Connection conn=null; try { conn= DriverManager.getConnection("jdbc:mysql://localhost:3306/test03","root","zber1574"); } catch (SQLException e) { throw new RuntimeException(e); } PreparedStatement pt= null; try { pt = conn.prepareStatement(sql); } catch (SQLException e) { throw new RuntimeException(e); } pt=conn.prepareStatement(sql); int a=pt.executeUpdate(); pt.close(); conn.close(); } }
以上就是数据库的提取解析重构再导入
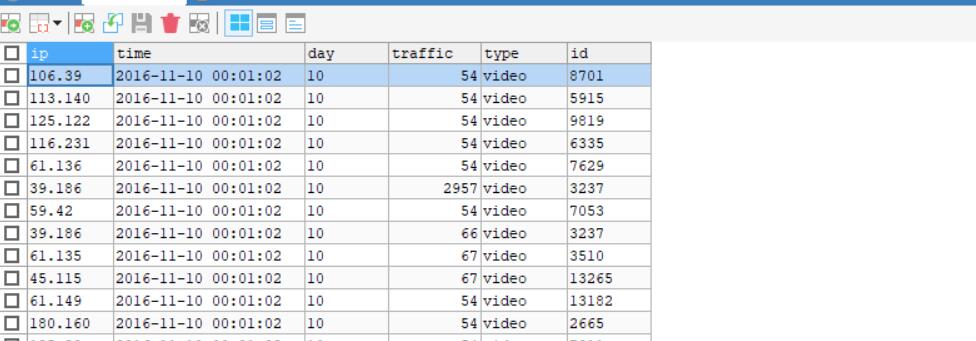
ps:此时从数据库导出的.csv文件可能会是带有""的

会影响hive的正常读取
之后将csv文件通过xftp传入虚拟机
打开到hive
创建表
create table city( ip string comment "城市" , c_date string comment "日期" , c_day string comment "天数" , traffic string comment "流量" , type string comment "类型" ,Id string comment "id" ) row format delimited fields terminated by ',';
将文件导入表
hadoop fs -put /opt/software/city.csv /user/hive/warehouse/city
题目一表
create table type10( id String, total String )ROW format delimited fields terminated by ',' STORED AS TEXTFILE; insert into type10 select id, count(*) as total from result1 group by id order by total desc limit 10;
create table if not exists tb_ip comment "ip" as select ip, type, id, count(*) as paixu from city1 group by ip,type,id order by paixu desc limit 10;
create table if not exists tb_traffic comment "traffic" as select type, id, sum(traffic) as liuliang from city1 group by type,id order by liuliang desc limit 10;
最后用fineUI可视化就完成了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号