TASK 3 Datawhale AI 夏令营
\(transformer\) 解决任务
1.特点
摒弃了循环结构,通过自注意力机制衡量上下文单词的重要程度
说人话就是联系前后单词对于该单词的影响来完成本单词的翻译
2.运行逻辑
在运行前,由于摒弃了循环结构,我们需要在词语中嵌入位置编码来构建单词的向量表示,模型利用每个词语的位置与维度构建单独位置的位置编码(由于与位置相关可以利用位置编码反推距离信息)
计算位置编码代码:
position = torch.arange(0, max_len, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
#其中0与1表示两个维度 position计算位置
\(transformer\)主要组件分为编码器,解码器和注意力层,主要构架如图所示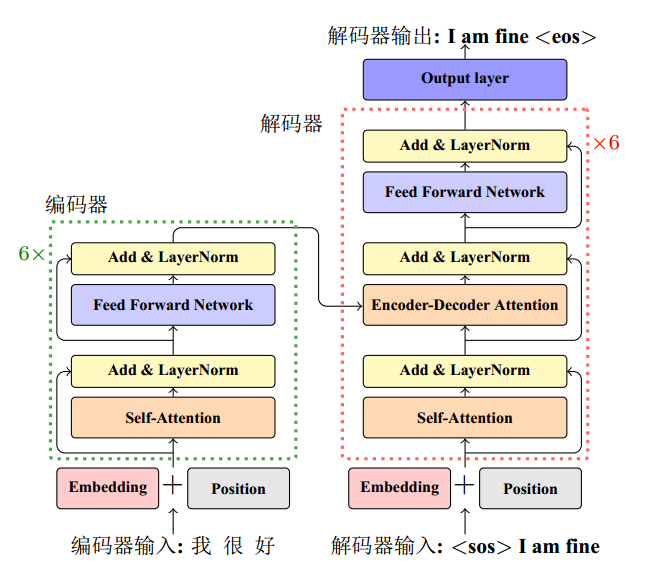
可以看出,在编码器中,\(transformer\)通过两个子层的叠加达到了对中文部分的编码
在第一层注意力层中,代码依赖三个元素\(Key,Query,Value\)计算权重,通过权重来反应上下文单词的重要程度
\[Z=Attention(Q,K,V)=Softmax(\frac{QK^{T}}{\sqrt{d}})V
\]
做\(\sqrt{d}\)的处理是基于防止放大的匹配分数导致梯度爆炸的问题
在前馈层中,通过接收自注意力层的输入,通过\(Relu\)函数做非线性变换,实验表明,该线性变换非常重要
在对模型的训练中,通过残差链接与层归一化来稳定输出,解决庞大的数据量导致的训练困难的问题,残差链接通过映射函数控制两个输出之间的关系:
\[x^{l+1}=f(x^l)+x^l
\]
由图可以看出,解码器流程与编码器类似,但更为复杂,主要由于解码器的序列未知,所以,在解码器中,在自注意力子层增加了注意力掩码,来掩盖后续的文本,以防后续文本干扰训练
