后端 | 业务/框架设计
订单系统
- 百亿订单的调度方案:https://www.toutiao.com/article/7205946675146326540
- 主要针对订单流程中的超时场景做调度,买家支付超时、商家发货超时、买家收货超时等场景中,海量订单的调度方案。
- delayQueue:单机,占用内存大;RocketMQ:RocketMQ 5.x 版本已经从延迟消息变成了支持秒级定时消息,时间轮原理。
- 阿里的订单超时设计方案:https://mp.weixin.qq.com/s/OmbyxkufVm-XzwIv_A514w
- 订单超时主要可以采用 JDK 延迟队列、RabbitMQ / RocketMQ 的延迟消息、Redis 过期监听、定时任务分布式批处理等解决方案。
- 阿里采用的是基于定时任务分布式批处理的超时中心来做订单超时处理的方式,SLA 可以做到 30 秒以内。通常的解决方案是借助任务调度系统,通过 MapReduce 的支持分片处理。
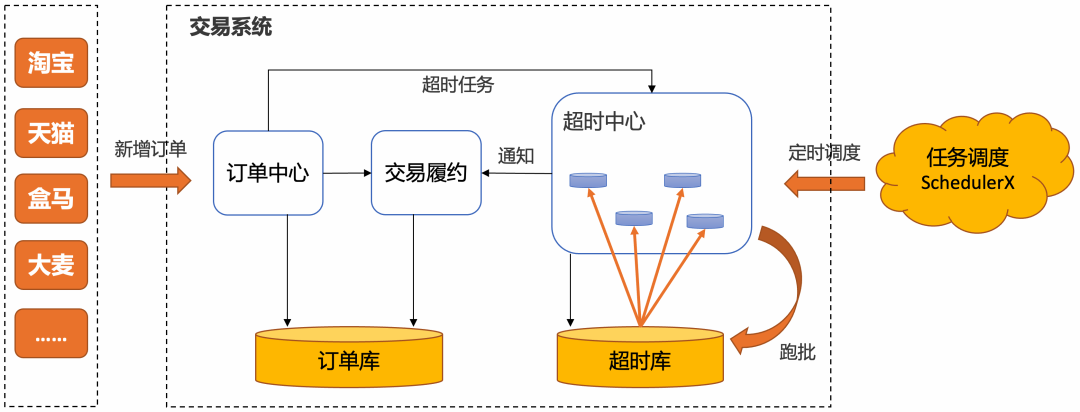
- 对于超时精度没有那么敏感,并且有海量订单需要批处理,推荐使用基于定时任务的跑批解决方案。每次从订单库将一批订单取出超时处理,效率高稳定性强,几秒的延迟对于若干小时的订单超时时间来说在可接受的范围之内。
- 订单超时关闭的设计方案:https://mp.weixin.qq.com/s/RF8bg6oL3xTWw7FSC5OJpQ
- 被动关闭:用户查询的时候再查询是否需要关闭,不适合任何生产环境;
- 定时任务:定时任务处理不精准,不适合大量数据的场景,对数据库也会造成很大压力;
- JDK 延迟队列 DelayQueue:单机场景下使用,数据量过大会造成 OOM;
- Netty 时间轮:比 JDK 延迟队列效率更高,但同样只适合在单机环境使用;
- Kafka 时间轮:实现方式复杂,依赖于 Kafka,稳定性和性能都更高,适合分布式场景;
- RocketMQ 延迟消息:RocketMQ 高版本可支持任意粒度的延迟时长,实现定时关单;
- RabbitMQ 死信队列:给消息设置固定的 TTL,过期后直接变成死信,转发到特定消费者处理;
- RabbitMQ 延迟消息插件:不存在消息阻塞,灵活可用,最高支持 (2^32) -1 毫秒,可用性和性能都有保障;
- Redis 过期监听:Redis 并不保证 Key 在过期的时候就能被立即删除,更不保证这个消息能被立即发出,所以会有消息不稳定的情况发生;
- Redis 的 ZSet:在高并发场景中,有可能有多个消费者同时获取到同一个订单号,一般采用加分布式锁解决,但是这样做也会降低吞吐量;
- Redisson 延迟队列:Redission 中定义了分布式延迟队列 RDelayedQueue,这是一种基于 Zset 结构实现的延时队列,它允许以指定的延迟时长将元素放到目标队列中。其实就是在 ZSet 的基础上增加了基于内存的延迟队列,要添加一个数据到延迟队列的时 Redission 会把数据+超时时间放到 ZSet 中,并且起一个延时任务,当任务到期的时候,再去 ZSet 中把数据取出来,返回给客户端使用。
- 订单系统的业务设计:https://blog.csdn.net/wanghengwhwh/article/details/119185358
- 订单系统中的关键设计:https://blog.csdn.net/sxj159753/article/details/104209288
- 订单系统的关键:低延迟、高可用、不丢单。设计出简单的订单系统,之后分析哪些环节有可能出现丢单,日万级如何优化,日千万级如何优化。
- 低延迟表现在写操作能立马被感知到。① 关键逻辑不要使用读写分离的查询方式,避免从库同步延迟造成订单查询异常。②
- 高可用是在系统数据准确性有保障的前提下,而整个处理流程基于订单引擎的调度,通过服务流程编排,确定一个订单的执行步骤,并保证每个环节正确的执行,避免订单丢单,卡单等异常情况的出现,进而保证订单流程的高可用。
- 交易日均千万订单的存储架构设计与实践:https://juejin.cn/post/7282245793688059964
取货码系统
- 电商平台取货码系统设计方案:https://mp.weixin.qq.com/s/uCzc_mDkt2cZZkbCLGLuUQ
- 订单号码远大于取货码号码,如何做订单级别的映射;文章介绍了库表的编号做取货码末尾的方法,单表内的重复,可以直接使用重试解决。
为什么不用开头做库表编号?用了开头之后,如果一个库内单据数太多,那么最后这部分的单据数量将会超过上限,届时扩容会需要增加取货码的长度,这会和业务诉求产生冲突。
- 门店唯一和全局唯一的思考值得学习,但不符合实际。按照位数以及易用性来算,全局唯一无法实现。现在都是用取货机扫描包裹,取货码只是为了方便检索,所以门店唯一即可。
- 保证未核销的取货码唯一,极大降低了难度,避免取货码膨胀。
- 查询未核销的取货码是否存在,根据查询结果执行插入操作,因为不是原子性存在并发安全,使用分布式锁保证安全。
购物车系统
- 淘宝购物车的技术升级与沉淀:https://mp.weixin.qq.com/s/XPrQvPmGxlWvFDoMa_BfGg
- 淘宝购物车经历多轮迭代,功能越来越强大,也沉淀出多种通用的能力支撑其他业务快速迭代。淘宝购物车的基础功能,可以总结为:加、改、算、凑;
- 加:迭代上线常购功能,利用算法计算用户高购买意愿的复购商品并通过离线手段自动加入到用户常购购物车,缩短复购路径且提高用户购买效率;
- 改:主要是为提高用户使用购物车的效率努力。商品 sku 是动态高频变化的,商品失效、涨价、购物车容量不足等情况,都需要为用户提供一键处理功能;
- 算:实时计算购物车商品总价格,购物车要不断追求价格计算的正确性以及清晰度。① 商品卡片可看到优惠后的价格;② 勾选多个商品能看到最终结算价格,且可以看到单个商品分摊的优惠价;③ 展示优惠明细,将整个优惠价格计算过程展示给用户。
- 凑:购物车的数据核心是用户购物车商品,核心功能就是凑单、合并结算。在购物车系统中添加凑单的计算,可以添加用户的合并计算。凑单主要体现在:① 用户勾选多个商品时,支持业务定制,分组结算;② 用户在购物车不断挑选、勾选商品的过程中,满减凑单的进度在不断更新,并提供筛选、推荐、引导凑单等功能提高用户凑单结算的效率。
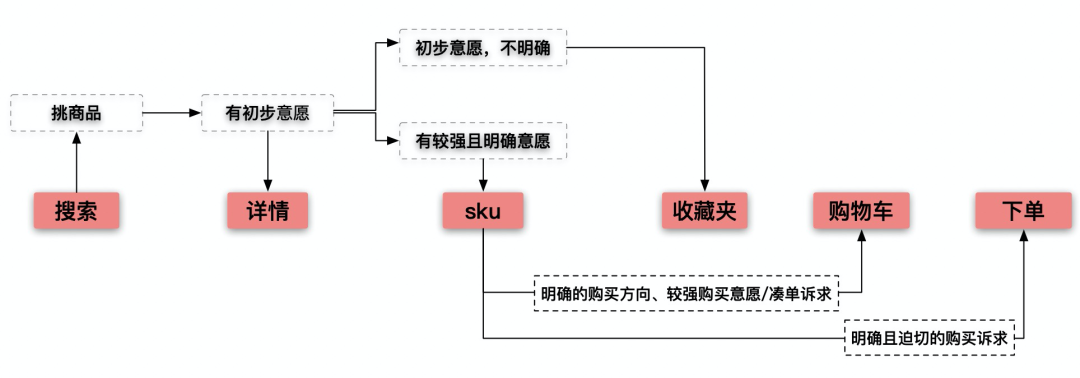
- 收藏夹和购物车的主要区别,可以从用户的使用路径看出。主要是用户购买意愿、凑单和下单诉求、容量区别。
优惠券系统
- 优惠券系统的产品设计:https://www.woshipm.com/pd/5441418.html
- 字节搭建优惠券系统的实战过程:https://blog.csdn.net/ByteDanceTech/article/details/124207051
库存系统
商品详情
秒杀系统
红包系统
- 微信红包的架构设计简介:https://www.zybuluo.com/yulin718/note/93148
- 微信/字节百亿级超大流量红包架构方案:https://www.toutiao.com/article/7211008331404657204
- 微信红包系统的设计:https://xie.infoq.cn/article/98712b10cadd310e077a2127d
- 抖音春节视频红包系统设计与实现:https://blog.csdn.net/ByteDanceTech/article/details/125342256
- 微信每秒数十万级红包收发的实现方案:http://tech.inpai.com.cn/yejie/20181130/9671.html
- 这里主要考虑高并发下的请求合并,采用了 SET 化、请求排队串行化、双维度分库表等设计。
履约系统
- 多平台订单履约系统:https://www.woshipm.com/pd/2361524.html
- 电商履约系统:https://www.infoq.cn/article/QLrUJiBm0sqZjq02rzwr
短链系统
- 短链接系统设计:https://blog.csdn.net/zhiyikeji/article/details/124112419
- 如何设计短链接系统:https://blog.csdn.net/gu_wen_jie/article/details/119250339
- 短链设计详细讲解:https://mp.weixin.qq.com/s/HaOhvgtgbCJyNXp-DtgedQ
- 转转短链平台设计与实现:https://mp.weixin.qq.com/s/pbven5YVUzzmyQGjU062mQ
- 网易高性能短链设计与实现:https://mp.weixin.qq.com/s/kM6M__TzsxCMYRNGo9vJMQ
- 京东短网址高可用提升最佳实践:https://juejin.cn/post/7232088054763880509
权限系统
- 权限系统设计详细介绍:https://blog.csdn.net/u010482601/article/details/104989532
- 字节融合模型权限管理设计方案:https://blog.csdn.net/ByteDanceTech/article/details/125437591
SSO 单点登录
- SSO 单点登录介绍以及实现:https://blog.csdn.net/ZqnBeata/article/details/123355904
用户 ID
- 用户 ID 的生成策略:https://segmentfault.com/a/1190000023588832
- 常用方案:随机生成-普通查重模式、经典表 ID 自增模式、号池模式、随机生成-查重模式-加位法、类 Snowflake 模式、UUID 模式
在线状态
- Redis 如何存储上亿级别的用户状态:https://blog.51cto.com/u_15499328/5157884
- 亿级用户的在线状态如何统计:https://blog.csdn.net/GV7lZB0y87u7C/article/details/121483860
LBS 系统
- LBS 系统中附近的人实现方案:https://blog.csdn.net/qq_41451303/article/details/122079395
排行榜
- Java 实现排行榜方案:https://blog.csdn.net/weixin_37598243/article/details/128876502
- Redis 实现排行榜方案实现:https://blog.csdn.net/bank8818bank/article/details/126649574
用户增长
- 四种轻量级用户增长策略:https://www.woshipm.com/operate/2648507.html
- 用户增长的模型、业务、产品设计:https://www.woshipm.com/operate/4548675.html
风控系统
- 风控系统的模型和设计:https://www.woshipm.com/pd/5782409.html
网站统计
用户体验
服务架构
- 腾讯后台服务架构高性能设计之道:https://www.toutiao.com/article/7094098101773828645
- 总结:无锁化、零拷贝、序列化、池子化、并发化、异步化、缓存、分片、存储、队列
列表查询
RPC 设计
- 快速设计一款 RPC 微服务框架:https://mp.weixin.qq.com/s/B4a0MWCLh1www_Mx66AgVw
IoC 容器
消息队列
定时任务
- 定时任务的实现方案与优缺点对比:https://blog.csdn.net/lisu061714112/article/details/115587513
- Quartz 以及 Spring 整合:https://blog.csdn.net/weixin_38192427/article/details/121111677
布隆过滤器
JWT
DDD
- DDD 项目落地之充血模型实践:https://juejin.cn/post/7264235181778190373
HotKey
- 京东 HotKey 热 Key 探测框架:https://mp.weixin.qq.com/s/xOzEj5HtCeh_ezHDPHw6Jw
- 总体流程:服务端引入 jar 包,jar 包会根据过滤规则监测指定的 key,通过 Netty 将监测结果发给指定 worker,交由指定 worker 完成热 key 的访问次数累加计算。worker 将符合条件的热 key 推送到各服务实例,实例收到热 key 信息,在本地内存完成缓存。
- 总体架构如下图所示。其中 worker 主要负责计算,使用 etcd 作为注册中心,实现不同 worker 之间的共识。
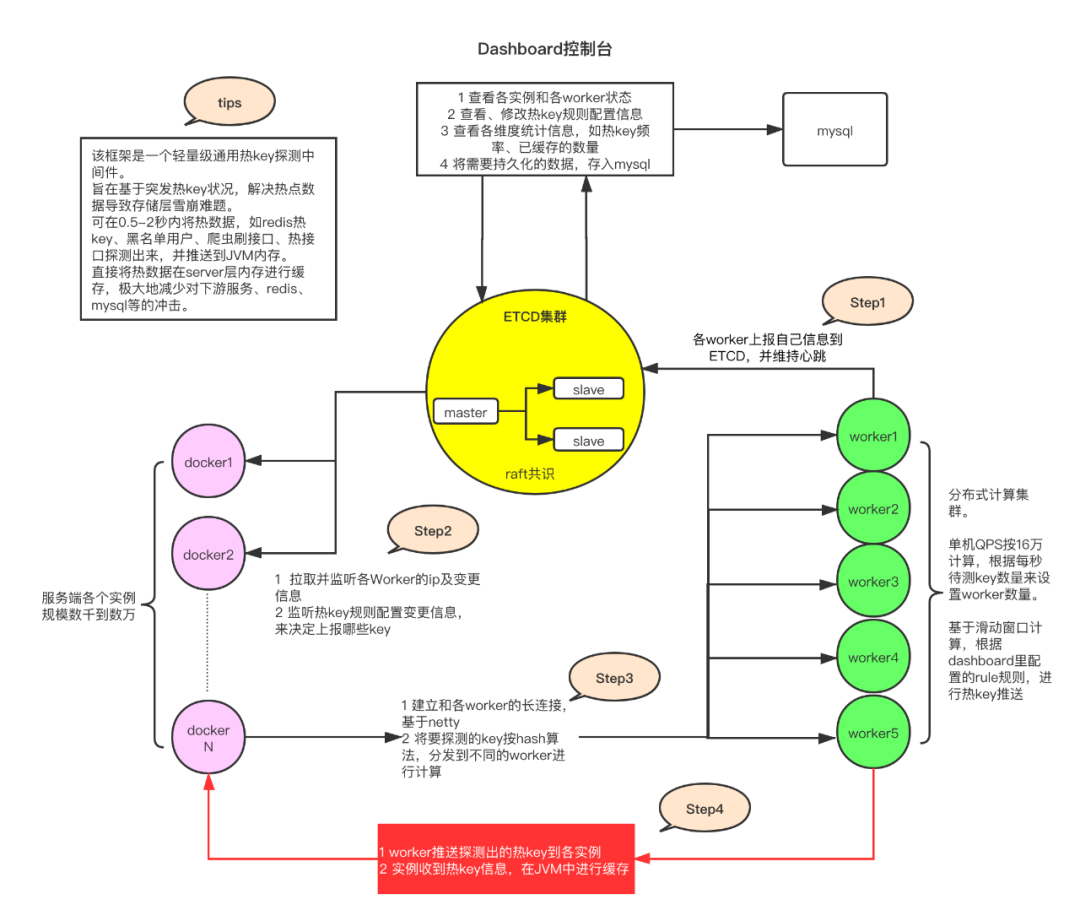
- 在引入 JdHotKey 框架之前,针对热 key 通常有几种处理方式。分析一下为什么不选择这些方式,以及它们的优缺点。引入热 key 探测框架效果显著,实际用于京东的 618 大促,也证实了它的优秀性能表现。
- ① 使用本地缓存框架。使用 guava、caffeine 等本地缓存框架,同时在 redis 和本地缓存一份,针对本地缓存做 LRU 的淘汰策略。这样的缺点是内存消耗大,命中率低。② 改写 Redis 源码加入热点探测功能,有热 key 时推送到 JVM。问题主要是不通用,且有一定难度。③ 改写 Redis 相关的 jar 包,通过本地计算来探测热点 key,符合热点 key 的条件就通知集群内其他机器。本地实时计算 key 的访问次数以及频次,会抢占服务实例内存和 CPU 资源,key 较多时情况更严重;如果引入其他组件,如 Redis 本身,那么需要频繁读写 Redis 实例,依旧存在 Redis 的性能瓶颈问题。针对这个问题,框架的解决方案是:拆分路由、本地计算、Netty 长连接,利用 worker 集群的内存以及计算性能,将探测的 key 通过 hash 路由到指定的 worker 中,交由 worker 计算。
- 问题:worker 集群机器越多,那么 Netty 建立的长连接就会越多,网络负担是否会越重?是否可以每个实例连接指定 worker?答:worker 集群机器越多,要建立的 Netty 长连接就会越多,网络负担就会越重。服务实例通常是多机器、水平扩容 scale-out 的,那么每个实例中对于 key 的访问,是不确定的。每个实例减少连接的 worker 数,目前没有很好的解决方法。
- 京东热 Key 探测框架的性能优化之路:https://my.oschina.net/1Gk2fdm43/blog/4533994
- 主要记录 JdHotKey 框架的性能优化历程。
- 提升框架性能,主要做了这些事:① 调整 JDK 版本,修复了 docker 环境获取到宿主机的核心数问题;② 更换并发框架 disruptor 为 JDK 自带的 LinkedBlockQueue,disruptor 在生产和消费速率相当的理想情况下性能不错,但是 LinkedBlockQueue 属于读写各自一把锁,做到了分离,实际上更合适;③ 更换 JSON 序列化方式;④ 根据具体需求场景、具体数据量大小,调整 I/O 线程数和消费者线程数,通过多次压测,达到两者之间的平衡。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号