【Java基础】day16
day16
一、switch-case 和 if-else 谁更快?
switch-case
在 switch-case 中,case 的值是连续的话,会生成一个 TableSwitch 来进行优化,这样的情况下,只需要在表中进行判断即可。
这里使用 0-4 的连续值来进行测试
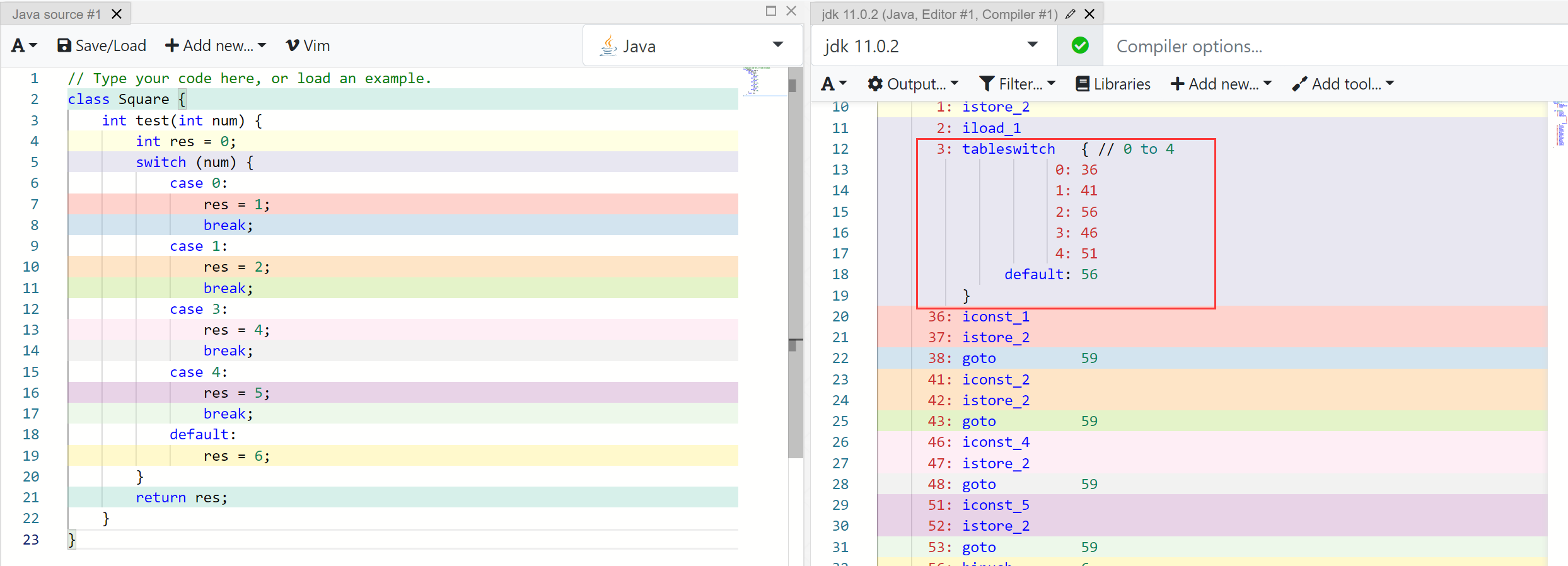
如果说多加几个 Case 的值,但是范围控制在比较小的范围时:
这里使用 0-9 之间的不连续的值来进行测试
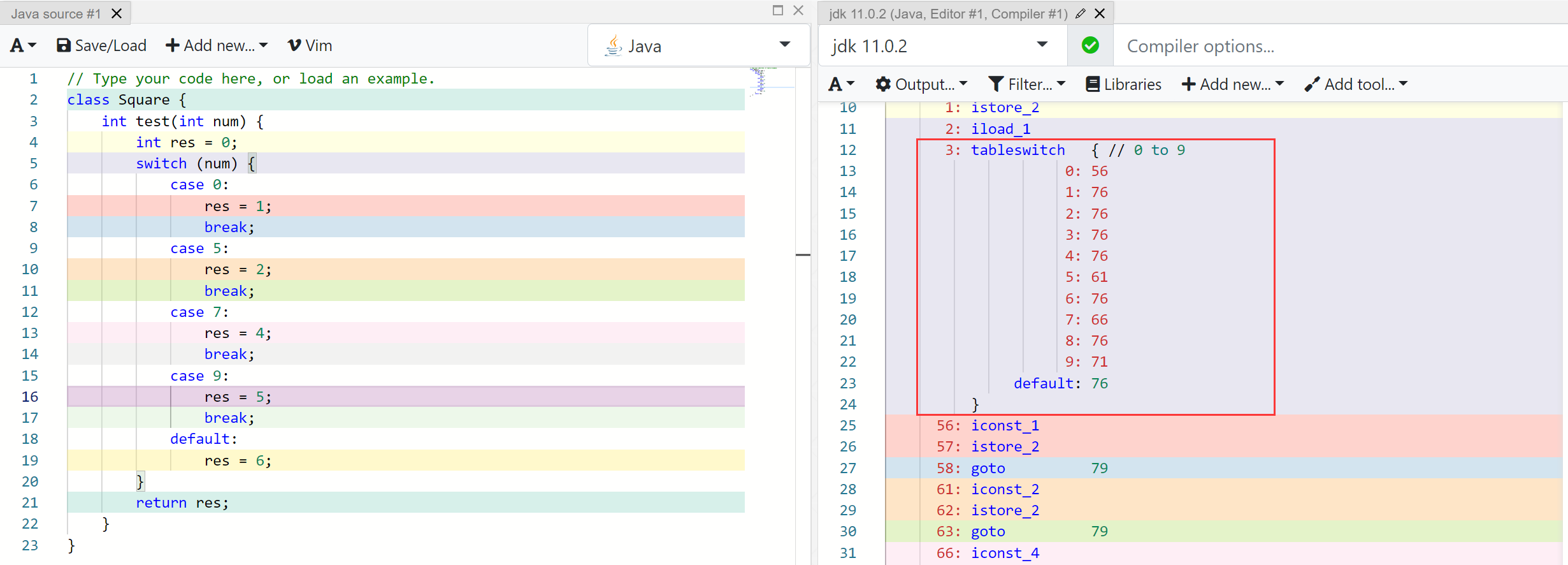
可以发现仍然使用了一个 TableSwitch 来进行优化。继续加大范围,但是只有少数能使用到,可以看到:
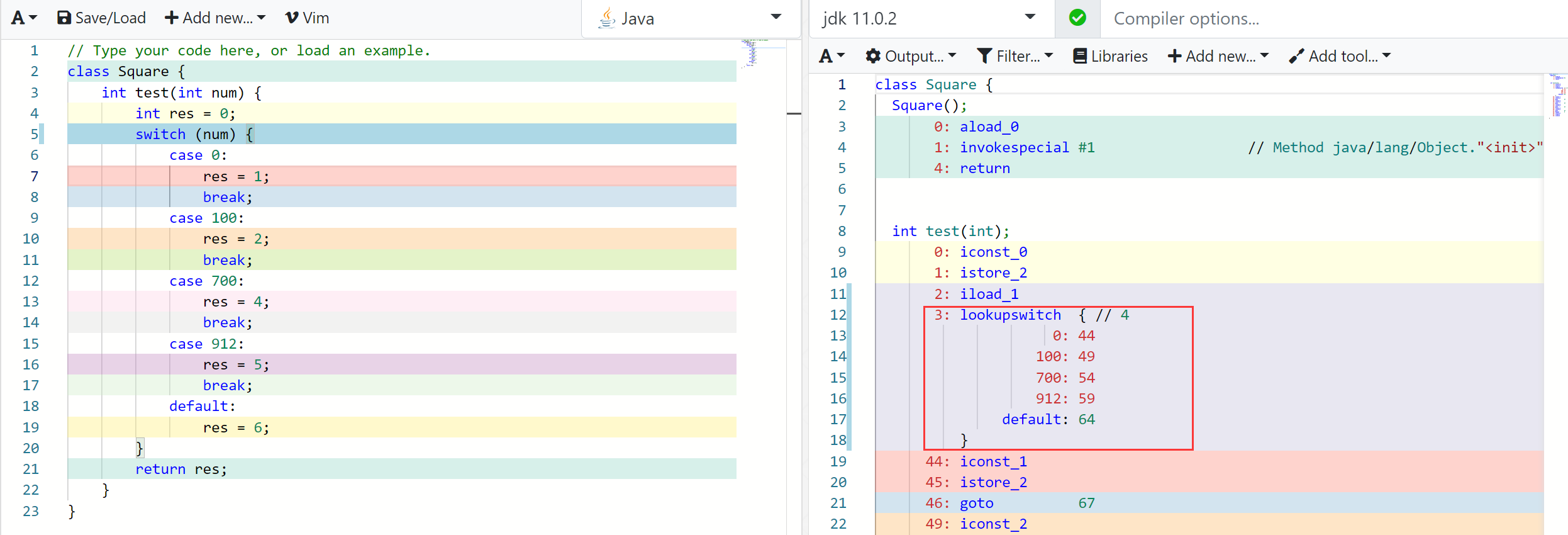
这一部分使用了 LookupSwitch 来进行判断,可以很明显看出就是执行搜索指令来得到目标执行的代码块。那么在这种情况下,switch-case 的效率是比较低的。JVM 虚拟机规范中提到:
Compilation of switch statements uses the tableswitch and lookupswitch instructions. The tableswitch instruction is used when the cases of the switch can be efficiently represented as indices into a table of target offsets. The default target of the switch is used if the value of the expression of the switch falls outside the range of valid indices.Where the cases of the switch are sparse, the table representation of the tableswitch instruction becomes inefficient in terms of space. The lookupswitch instruction may be used instead.
The Java virtual machine specifies that the table of the lookupswitch instruction must be sorted by key so that implementations may use searches more efficient than a linear scan. Even so, the lookupswitch instruction must search its keys for a match rather than simply perform a bounds check and index into a table like tableswitch. Thus, a tableswitch instruction is probably more efficient than a lookupswitch where space considerations permit a choice.
这一部分的大意就是:
switch 语句的编译使用 tableswitch 和 lookupswitch 指令。当 switch 的情况可以有效地表示为目标偏移表中的索引时,使用 tableswitch 指令。如果 switch 表达式的值超出有效索引范围,则使用 switch 的默认目标。在 switch 的情况稀疏的情况下,tableswitch 的 table 表示在空间方面变得低效,也可以使用 lookupswitch 指令。
Java 虚拟机指定 lookupswitch 指令的表必须按键排序,以便实现可以使用比线性扫描更高效的搜索。即使如此,lookupswitch 指令也必须搜索其键以查找匹配项,而不是简单地执行边界检查并索引到类似 tableswitch 的表中。因此,在空间考虑允许选择的情况下,tableswitch 指令可能比 lookupswitch 更有效。
这个 tableswitch 相比 lookupswitch 的转换,什么时候才算是稀疏,这就取决于编译器的决策问题了。这一决策涉及到数理统计,找到效率的执行上的差异来决定。
如果使用的是其他的数据类型进行 switch 的判断时,可以看到这一优化仍然存在。
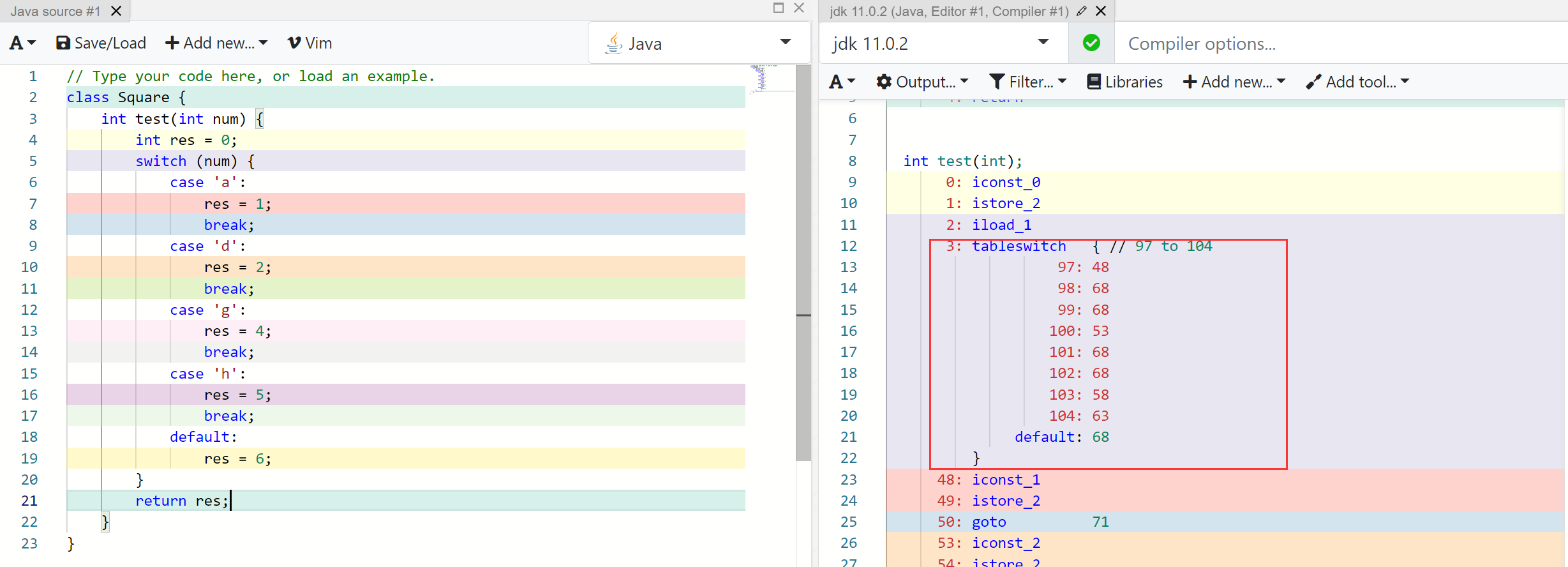
那么如果 case 之间使用的是不同数据类型呢?
使用 char 类型和 int 类型同时进行判断测试
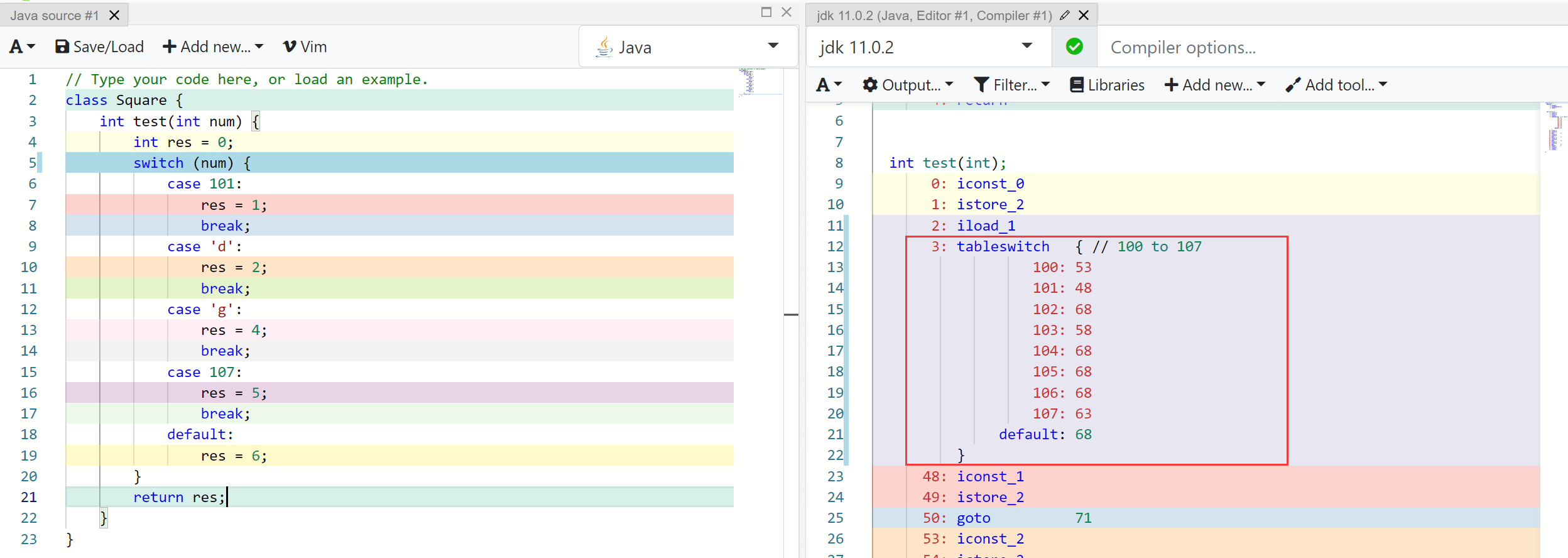
结果仍然没有改变,最终的底层还是会使用的 ASCII 码进行相关计算。同理来说,如果是 String 类型,则同样换算数字来进行计算,只不过使用的是 String 的 hashcode 方法来获取 String 的对应数值。
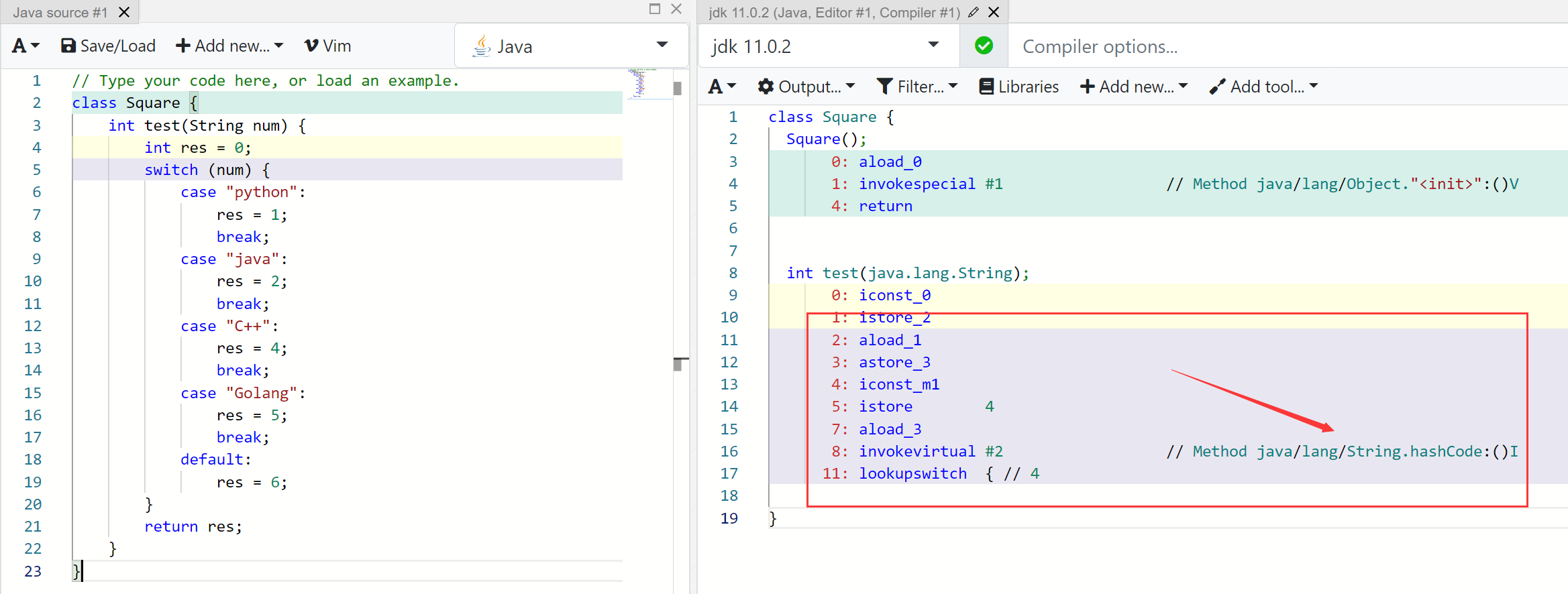
if-else
仍然使用之前的测试方法,这里使用连续的小范围的值进行测试:

这里可以看到使用的是逐个进行判断的方式。再使用不连续的方式进行判断:
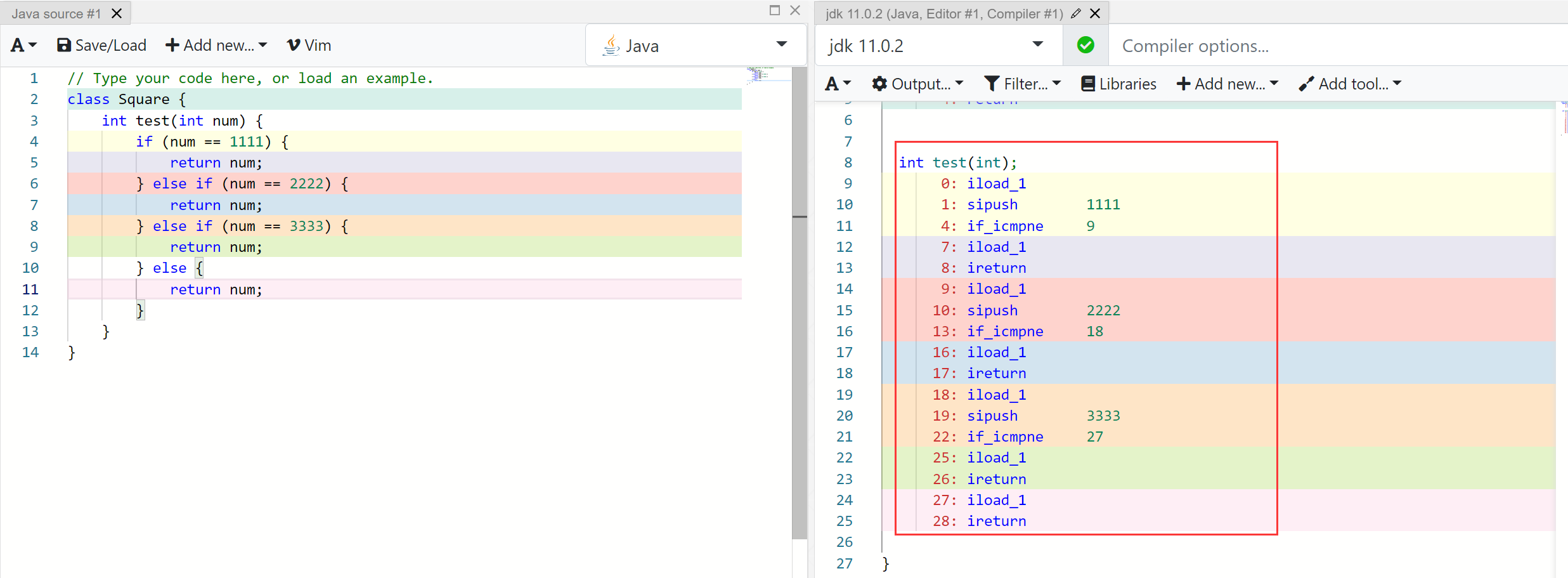
这里结论没有改变,仍然是使用的逐个判断。
结论
- 只有在 case 中的条件是连续的或范围相隔不大时,编译器会使用表结构做优化,性能优于 if-else。
- 其他情况下,switch-case 是逐个分支判断,性能与 if-else 无异。
- switch-case 中的 case 只能是常量,而 if-else 用途更广一些。
在选择分支较多且连续或者范围相隔不大时,选用 switch-case 结构会提高程序的效率,但 switch 不足的地方在于只能处理字符或者数字类型的变量。if-else 结构更加灵活一些,if-else 结构可以用于判断表达式是否成立,应用范围更广,switch-case 结构在某些情况下可以替代 if-else 结构。
Website
https://godbolt.org/
二、枚举为什么是实现单例模式的最好方式?
这种方式是 Effective Java 作者 Josh Bloch 提倡的方式。它不仅能避免多线程同步问题,而且还自动支持序列化机制,防止反序列化重新创建新的对象,绝对防止多次实例化。由于 JDK 1.5 之后才加入 enum 特性,这种方式在实际开发中用的比较少。
不能通过反射攻击 reflection attack 来调用私有构造方法,所以能绝对防止多次实例化。
枚举类型会在类加载阶段就进行初始化,类加载阶段是数据安全的,所以是线程安全的。
这种实现方式还没有被广泛采用,但这是实现单例模式的最佳方法。它更简洁,自动支持序列化机制,绝对防止多次实例化。如果涉及到反序列化创建对象时,可以尝试使用枚举方式。
public enum Singleton {
INSTANCE;
public void whateverMethod() {
}
}
三、为什么已经有了 synchronized 还需要 volatile?
从两个角度考虑:
- 因为
synchronized是一种锁机制,存在阻塞问题和性能问题;而 volatile 并不是锁,不存在阻塞和性能问题。 - 因为 volatile 借助了内存屏障来帮助其解决可见性和有序性问题,在有些场景中是可以避免发生指令重排现象。
针对单线程,因为 as-if-serial 语义以及线程执行的时候需要遵守线程内语义 intra-thread semantics(保证重排序不会改变单线程内的程序执行结果),所以 synchronized 修饰的部分不会出现指令重排。那么 volatile 避免的指令重排是不是都可以通过 synchronized 解决呢?
并不是,参考 DCL 双重检查锁的实现。不使用 volatile 可能让其他线程访问到还未初始化完毕的对象,导致获取的对象为空,引发 NPE。
Java 对象在进行创建的时候,通常会有三个步骤:
- 分配对象内存
- 调用构造器方法,执行初始化
- 将对象引用赋值给变量
如果在不使用 volatile 关键字的时候,可能会发生指令重排,导致对象的初始化在多线程环境下的执行顺序发生变化。
指令重排:是机器指令级别的重排,并不是代码行级别的重排。
问题:
① 既然是加锁状态,那么同时刻只会有一个线程执行加锁代码块,且在执行同步块的时候,会刷新主内存,是否也能保证可见性?
是保证了可见性,但是因为指令重排序的问题,会有获取到空对象的风险。
② 在执行初始化的时候,是在同步代码块中的。初始化指令集执行时,是会保证原子性的,也就是只有一个线程能执行这一块代码。这个时候如果未初始化完毕,那么 singleton 对象仍为空。
此刻其余线程如果执行 DCL,会突破第一道检查,在代码块处等待锁的释放。在第一个执行完初始化的线程释放锁之后,其余线程执行代码块,会进行主内存的刷新,所以判断第二次,会得到完整的 singleton 对象。
这个过程中,如果不使用 volatile 修饰 singleton 对象,那么在初始化过程中,会因为指令重排序导致初始化过程出现问题。
指令重排可能导致对象在创建过程中先指向了引用,再执行初始化操作。这样违背了原本的初始化顺序,单线程环境下确实最终的结果不会发生改变。但是多线程下,其余线程在执行第一重检查的时候,可能获取到了只指向了引用还未初始化的空对象,这样就会存在 NPE 风险。
Reference
https://blog.csdn.net/bochuangli/article/details/122862651
四、Java 中的自旋锁怎么实现的?
自旋锁并不是真正的锁,而是让等待的线程先原地等待一下,通常实现方式很简单:
int SPIN_LOCK_NUM = 64;
int i = 0;
boolean wait = true;
do {
// 尝试获取资源锁
wait = xxx
} while (wait && (++i) < SPIN_LOCK_NUM);
在 Java 的 Unsafe 中的 CAS,就使用到了自旋锁。
public final class Unsafe {
public final int getAndSetInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var4));
return var5;
}
}
根据自旋的一些概念,可以得知自旋锁是不能递归的,否则会自己获取自己已经拥有的锁,导致死锁的出现。
一个线程获取了一个自旋锁,在执行时被中断处理程序打断,因此该线程只是暂停执行,并未退出,仍持有自旋锁;而中断处理程序尝试获取自旋锁而获取不到,只能自旋;这就造成一个事实:中断处理子程序 ISR 拿不到自旋锁,导致自旋而无法退出,该线程被中断无法恢复执行至退出释放自旋锁,此时就造成了死锁,导致系统崩溃。
存在这样的问题时候,针对自旋锁,就需要有几个特性:
- 在临界区持有自旋锁的线程不能休眠,休眠会引起进程切换,CPU 就会被另一个进程占用等无法使用;
- 持有自旋锁的线程不允许被中断,哪怕是 ISR 也不行,否则就存在 ISR 自旋;
- 持有自旋锁的线程,其内核不能被抢占,否则等同于 CPU 被抢占。
所以为了避免自旋发生死锁,我们需要针对自旋锁,添加限制条件:
- 持有自旋锁的线程,不能因为任何原因而放弃 CPU;
- 基于上述问题,自旋需要添加一个上限时间以防死锁。
五、是否所有的 GC 都会触发 STW ?
所有的 GC 都会 STW ,只是存在时间长短区别。原因是可达性分析算法中枚举根节点 GC Roots 会导致所有 Java 执行线程停顿。STW 事件和采用哪款 GC 无关,所有的 GC 都有这个事件。只是现在的 GC 算法越来越精进,减少了 STW 的时间。
并不是只有 Full GC 才会触发 STW,还包括 SafePoint 安全点检查状态。Safepoint 可以理解成是在代码执行过程中的一些特殊位置,当线程执行到这些位置的时候,线程可以暂停。在 SafePoint 保存了其他位置没有的一些当前线程的运行信息,供其他线程读取。可以理解为线程只有运行到了 SafePoint 的位置,它一切的状态信息才是确定的,也只有这个时候,才知道这个线程用了哪些内存。
Reference
https://zhuanlan.zhihu.com/p/437620682
https://www.zhihu.com/question/371699670
https://blog.csdn.net/m0_67401417/article/details/124277023

 浙公网安备 33010602011771号
浙公网安备 33010602011771号