【Java基础】day11
day11
一、BIO、NIO、AIO 三种 IO 模型分别是什么?
BIO (Blocking I/O)同步阻塞的 I/O 、NIO(New/Non-blocking I/O) 同步非阻塞的 I/O 、AIO(Asynchronous I/O) 异步非阻塞的 I/O 。这三种 IO 模型是 Java 中提供的 API ,与系统 IO 是不相同的。在Linux(UNIX)操作系统中,共有五种 IO 模型,分别是:阻塞IO模型、非阻塞IO模型、IO复用模型、信号驱动IO模型以及异步IO模型。
- 阻塞:发起一个请求之后,请求方如果没有等待到请求的结果,会一直处于等待,线程会被挂起,无法从事其他任务,条件就绪才能继续执行
- 非阻塞:发起一个请求之后,请求方不必等待到请求的结果,可以去执行其他任务
- 同步:发起一个调用之后,被调用者未处理完成之前,调用不返回
- 异步:发起一个调用之后,立刻得到被调用者的确认表示接收到调用,此时被调用者还没有返回结果,此时我们可以继续处理其他请求,被调用者处理完成之后通过事件、回调等机制来通知调用者
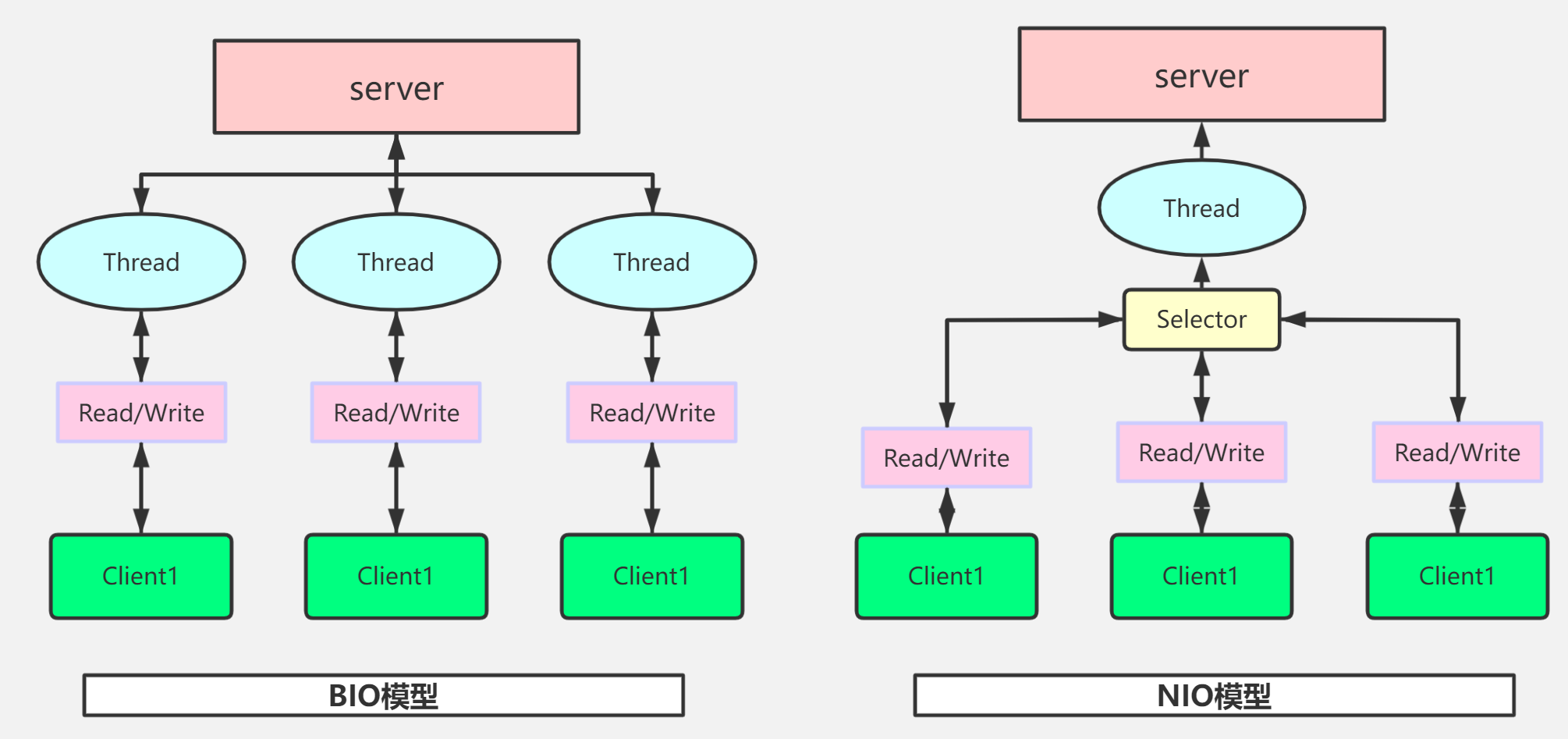
采用 BIO 的服务端,通常由一个独立的 Acceptor 线程来监听客户端的连接。通常是使用 while(true) 循环与 accept() 方法来让线程监听请求。一个线程在处理请求的时候是不能接收到来自其他用户的连接请求的,但是可以通过多线程的方式来让服务端能够同时服务多个用户。这个模型是典型的一请求一应答的通信模型。
采用 NIO 的服务端,引入了新的 Selector 、 Buffer 以及 Channel 概念。相比于 BIO 模型,NIO 不使用传统的 Socket 和 ServerSocket 类,而是使用对应的 SocketChannel 和 ServerSocketChannel 两种不同的套接字通道实现,两种通道都支持阻塞和非阻塞模式。
- NIO 是非阻塞的,IO 是阻塞的。因为 NIO 使用的是 Buffer 对象,读写的时候只需要开始即可,等待读取的过程中可以继续处理其他任务;IO 则要一直等待读/写完成才能继续其他任务。
- NIO 使用 Channel 进行通信,IO 使用 Stream 流进行通信。 NIO 是使用 Channel 通信,在 Channel 中对 Buffer 对象进行读写操作,可以支持双向读写和异步操作;而 Stream 只支持单向读写操作。
- Selector 选择器,NIO 模型中引入了 Selector 以及 Channel 概念。通过 Selector ,可以让单线程处理多个 Channel ,这样的处理可以提高线程的利用率。
JDK 中对于 NIO 的实现比较复杂,且还有空轮询的弊端,自行实现的 NIO 比较容易出现问题。通常使用的 Netty 框架的 NIO 模型来进行开发。
采用 AIO 的服务端,是异步非阻塞的。表示在发出请求之后,调用者可以继续执行其他任务,被调用者完成请求任务之后,相应的线程可以立即感知到(通常是操作系统发出通知)并且可以当即处理。目前 AIO 的应用比较少,适用于连接数目多且连接比较长的架构。
参考文档:
Java面试常考的 BIO,NIO,AIO 总结_小树的博客-CSDN博客
Java NIO浅析 - 知乎 (zhihu.com)
漫话:如何给女朋友解释什么是Linux的五种IO模型? (qq.com)
二、Java 中的内存分配策略有哪些?
Java 中的内存分配策略主要有两种,分别是指针碰撞和空闲列表。
指针碰撞:假设 Java 堆中的内存都是规整的,所有被使用过的放在一边,未使用过的放在一边,中间有一个指针作为分界,分配内存仅仅需要把这个指针向空闲空间方向移动一段即可。
空闲列表:如果 Java 堆中的内存不是规整的,已使用过的和空闲的交错,虚拟机就需要维护一个列表,记录哪些内存是可用的,在分配的时候找到一块足够大的内存进行分配。
三、ThreadLocal 线程变量是什么?
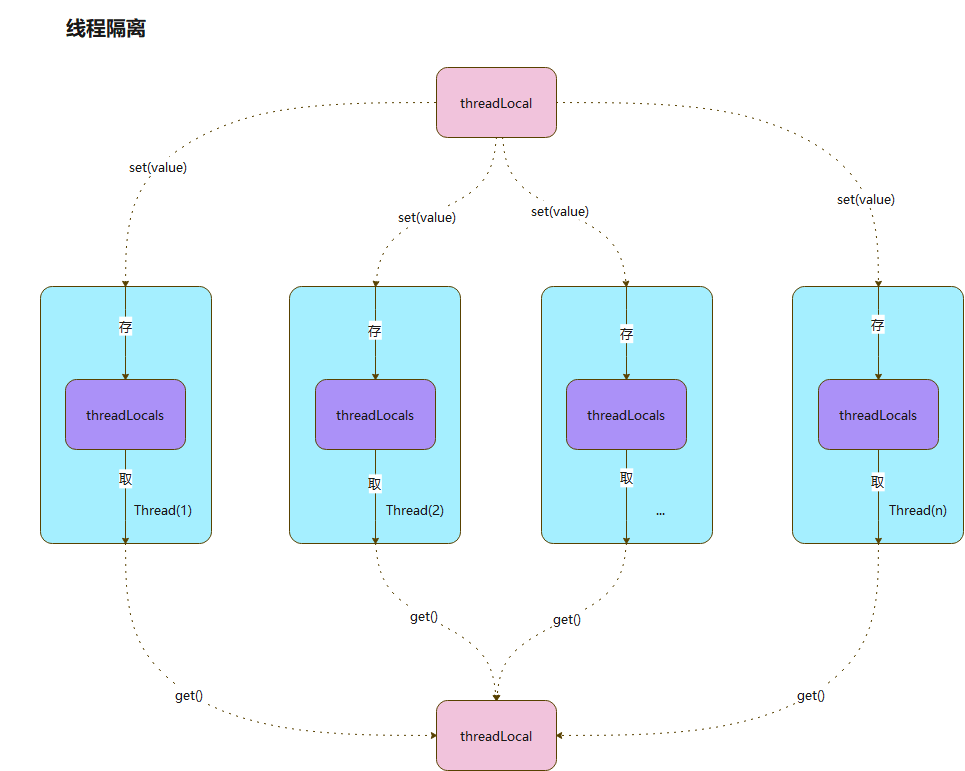
ThreadLocal 又被叫做本地线程变量,意味着 ThreadLocal 中填充的变量只属于当前线程,对于其他线程来说是隔离的。 ThreadLocal 为每个线程都创建了一个副本用来保存各自的变量,这样的设计下,线程各自对应的变量是其他线程不可访问的,这样就形成了隔离的环境。
- 每个副本中的变量只能由当前 Thread 访问,别的线程是访问不到的。所以在开发的时候要注意变量是否需要被移除,否则容易造成内存占用且不易回收。
- ThreadLocal 为每个线程都创建了各自的副本,且线程之间彼此隔离,这样就不存在多线程下的线程安全问题了。
- ThreadLocal 由于采用的线程之间隔离的方式,可以用于传递参数。实例需要在多个方法中共享,但不希望被多线程共享。比如在 Spring 中的 request 和 session 就使用了 ThreadLocal 变量来实现。
使用 ThreadLocal 的时候,通常需要实现其中的三个方法:get 、set 、 remove 。
@Component
public class HostHolder {
private final ThreadLocal<User> users = new ThreadLocal<>();
public void setUser(User user) {
users.set(user);
}
public User getUser() {
return users.get();
}
public void removeUser() {
users.remove();
}
}
以上的代码实现了将用户保存至各自对应的 ThreadLocal 中,可以比较容易地实现保存用户状态。
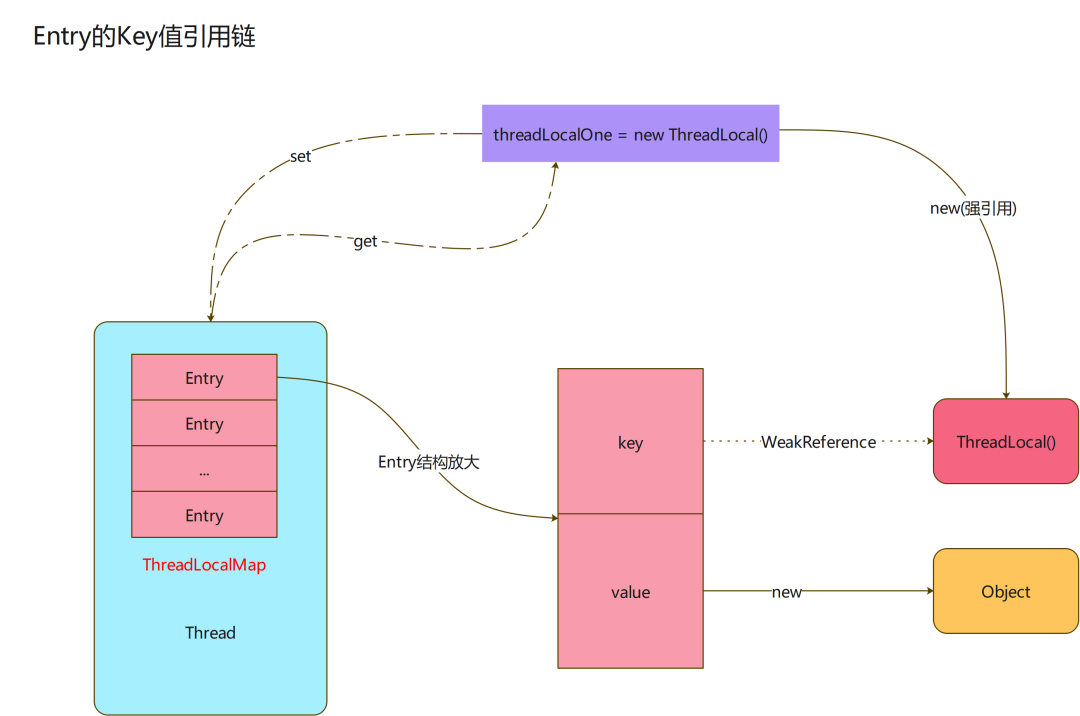
在 ThreadLocal 中一共存在四个方法,分为是 initialValue() 、set() 、get() 、 remove()。ThreadLocal 底层为了实现线程之间的隔离,使用 Map 来存储每个线程对应的副本,key 对应的是每个线程的线程 ID ,value 值为对应的副本空间中存放的变量。
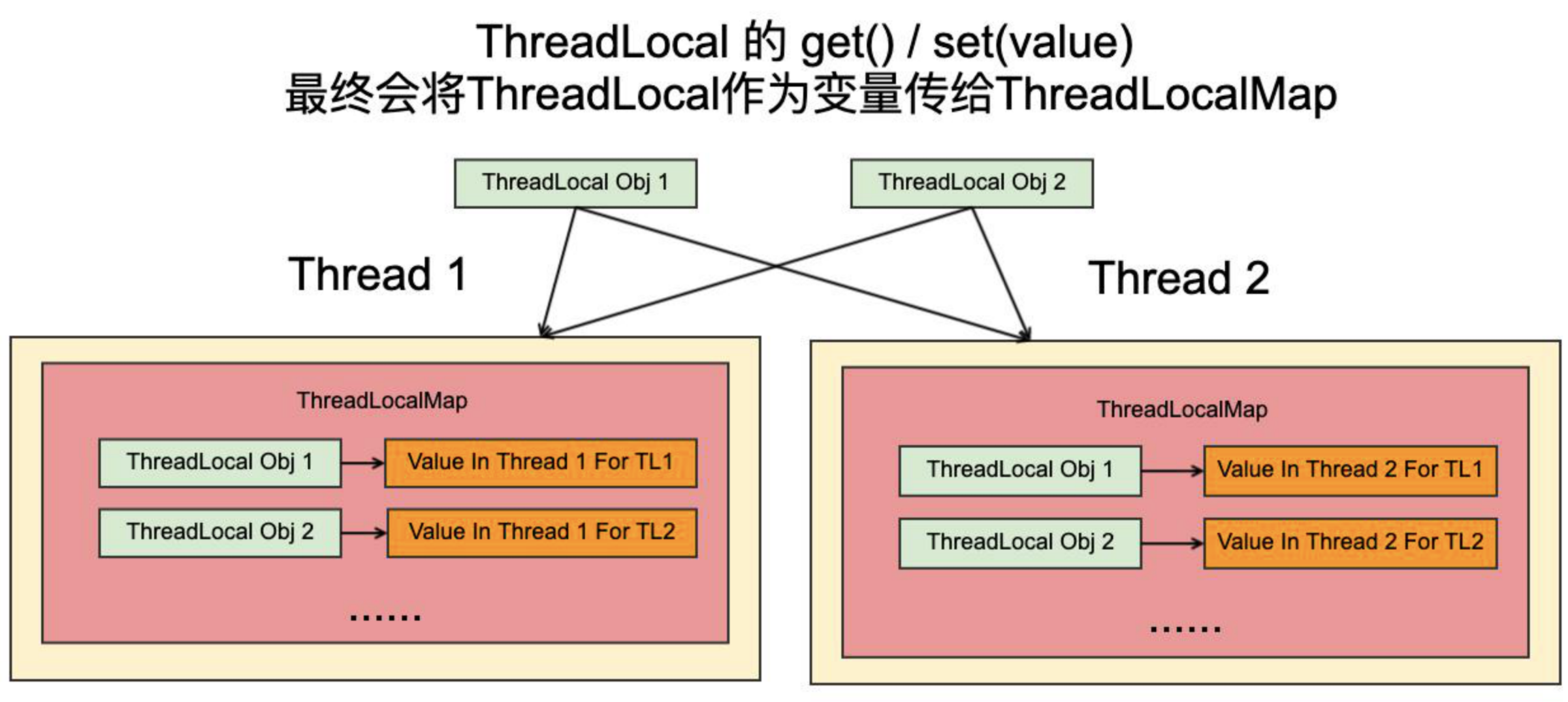
ThreadLocal 的组成结构:
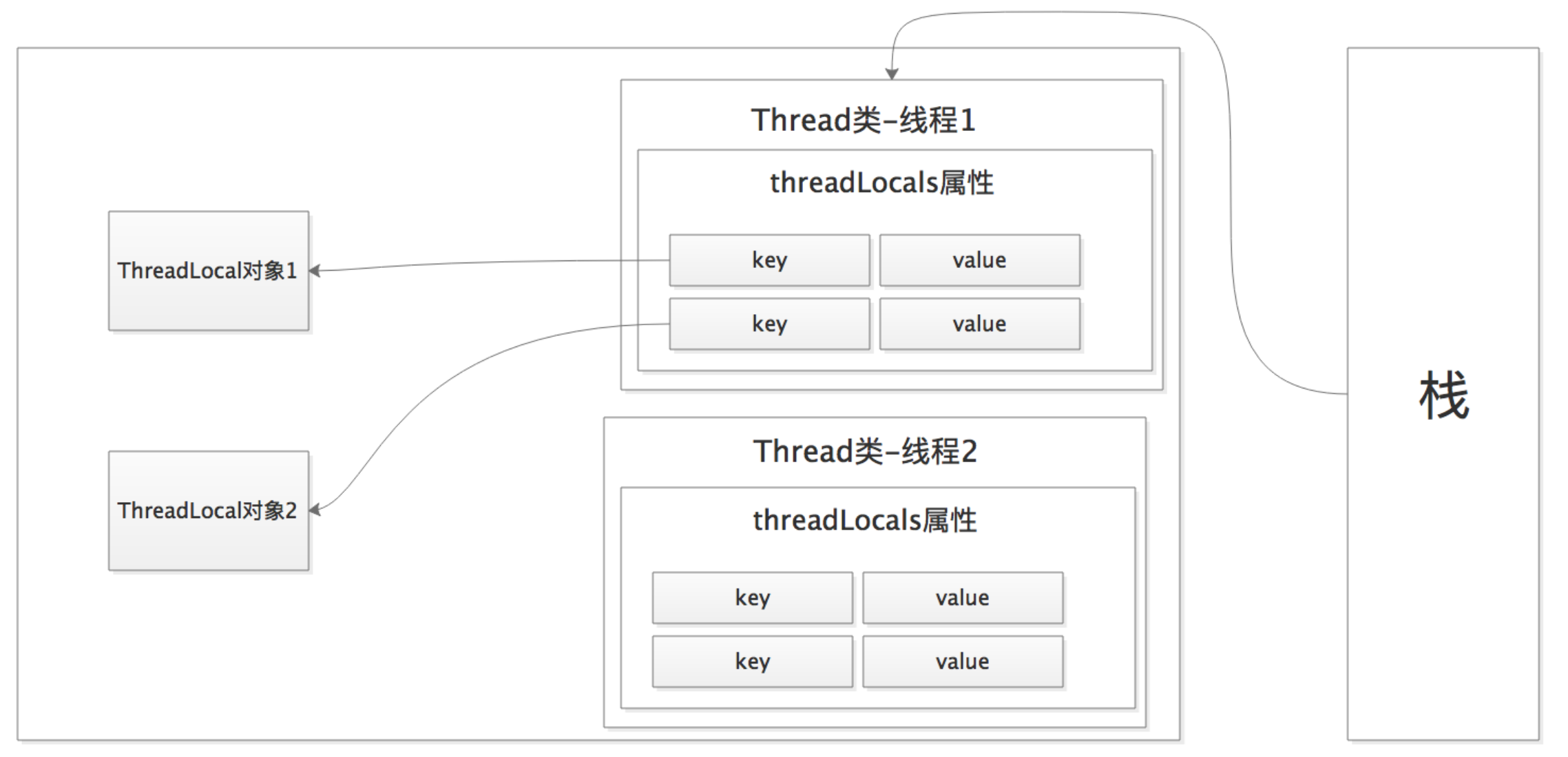
Thread 类中存在一个属性名为 threadLocals ,归属于 ThreadLocalMap 类,内部存在 Entry 数组,类似于 Map 。 Entry 数组中,key 存放的是 ThreadLocal 类,value 存放的是我们需要存放的对象。主要结构为:
static class ThreadLocalMap {
/**
* The entries in this hash map extend WeakReference, using
* its main ref field as the key (which is always a
* ThreadLocal object). Note that null keys (i.e. entry.get()
* == null) mean that the key is no longer referenced, so the
* entry can be expunged from table. Such entries are referred to
* as "stale entries" in the code that follows.
*/
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
}
由于 Entry 继承自 WeakReference 弱引用类,弱引用的特点是只能存在于下一次 GC 之前,发生 minorGC 或 majorGC 就会被回收,造成 key 变为空,value 还会被栈使用,也就造成了内存泄露问题。
如果没有对 ThreadLocal 中的变量进行删除或者替换,它的生命周期将会与线程同步;如果线程又交给线程池进行管理实现线程复用,核心线程的生命周期将会变得不可预测,不可避免地导致 ThreadLocal 中变量的生命周期也持续延长那个,导致内存泄漏的问题越来越严重。
- 可以自己调用 remove 方法将不要的数据移除避免内存泄漏的问题
- 每次在做set方法的时候会清除之前 key 为 null
- 使用反射机制获取当前线程对应的 ThreadLocalMap ,手动移除
参考文档:
史上最全ThreadLocal 详解_fu_bobo-CSDN博客_threadlocal
并发编程-Threadlocal - 简书 (jianshu.com)
源码篇:ThreadLocal的奇思妙想
四、 Redis 的缓存过期策略有哪些?
Redis 会把设置了过期时间的 key 放入一个独立的字典里,在 key 过期时并不会立刻删除它。 Redis 会通过如下两种策略,来删除过期的 Key 。
定时过期:每个设置过期时间的 key 都需要创建一个定时器,到过期时间就会立即清除。该策略可以立即清除过期的数据,对内存很友好。但是会占用大量的 CPU 资源去处理过期的数据,影响缓存的响应时间和吞吐量。
惰性过期:只有当访问一个 key 时,才会判断该 key 是否已过期,过期则清除。该策略可以最大化节省 CPU 资源,但是很消耗内存,许多的过期数据都还存在内存中。极端情况可能出现大量的过期 key 没有再次被访问,但是不会被清除,占用大量内存。
定期过期:每隔一定的时间,会扫描一定数量的数据库的 expires 字典中一定数量的 key(是随机的),并且清除其中已过期的 key。该策略是定时过期和惰性过期的折中方案。通过设置定时扫描的时间间隔和每次扫描的限定耗时,可以在不同情况下使得 CPU 和内存资源达到最优的平衡效果。
Redis 默认每秒执行 10 次过期扫描(配置 hz 选项),扫描策略如下:从过期字典中随机选择 20 个 key ,删除这 20 个 key 中 已过期的 key ;如果过期的 key 的比例超过 25% ,则再从过期字典中随机选择 20 个 key 。
分桶策略:定时过期的优化,将过期时间点相近的 key 放在⼀起,按时间扫描分桶。
五、 Redis 的缓存淘汰策略有哪些?
当 Redis 占用内存超出最大限制 maxmemory 时,可采用最大内存策略 maxmemory-policy,让 Redis 淘汰一些数据,以腾出空间继续提供服务。
- noeviction:对可能导致增大内存的命令返回错误(大多数写命令, DEL 除外)
- volatile-ttl:在设置了过期时间的 key 中,选择剩余寿命 TTL 最短的 key ,将其淘汰
- volatile-lru:在设置了过期时间的 key 中,选择最少使用的 key (LRU) ,将其淘汰
- volatile- random:在设置了过期时间的 key 中,随机选择一些key,将其淘汰
- allkeys-lru:在所有的 key 中,选择最少使用的 key (LRU) ,将其淘汰
- allkeys-random:在所有的 key 中,随机选择一些 key ,将其淘汰
Redis 中的 LRU 算法逻辑和普通的 LRU 略有区别。
- 普通的 LRU 需要维护一个链表,按照访问顺序存储数据。新的被访问的数据存储到表头,最近访问的 Key 在表头,最少访问的数据放在链表尾部。
- Redis 使用的 LRU 是一种近似 LRU 算法。给每个 Key 维护一个时间戳,淘汰时随机取样五个值,从中淘汰掉最旧的 Key 。这个时间戳的更新就是根据数据被访问的时间来进行记录的,这种方式相比于传统的 LRU 更加节省内存,也提高了计算的效率,且可以取得和 LRU 近似的淘汰效果。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号