第一次个人编程作业
目录
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | ||
| · Estimate | · 估计这个任务需要多少时间 | ||
| Development | 开发 | ||
| · Analysis | · 需求分析 (包括学习新技术) | ||
| · Design Spec | · 生成设计文档 | ||
| · Design Review | · 设计复审 | ||
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | ||
| · Design | · 具体设计 | ||
| · Coding | · 具体编码 | ||
| · Code Review | · 代码复审 | ||
| · Test | · 测试(自我测试,修改代码,提交修改) | ||
| Reporting | 报告 | ||
| · Test Repor | · 测试报告 | ||
| · Size Measurement | · 计算工作量 | ||
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | ||
| · 合计 | |||
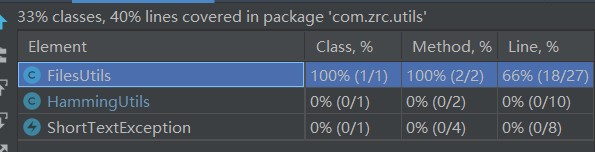
二、计算模块接口的设计与实现
流程图

类
- MainCheck:主程序
- SimHash:主要算法,计算SimHash值
- FilesUtils:工具类,读写txt文件
- HammingUtils:工具类,根据SimHash值,计算海明距离
- ShortStringException:异常类,处理文本内容过短
SimHash类的关键算法的实现步骤及原理
- 分词,把需要判断文本分词形成这个文章的特征单词。这里使用 结巴 的外部依赖进行分词。
//1.结巴分词(外部依赖)
JiebaSegmenter jiebaSegmenter = new JiebaSegmenter();
List<String> keywordList = jiebaSegmenter.sentenceProcess(str);
int size = keywordList.size();
2. hash,通过hash算法把每个词变成hash值。
//用数组表示特征向量,取128位,从0 1 2 位开始表示从高位到低位
int[] arr = new int[128];
int i = 0; //用i做外层循环
for(String keword:keywordList){
//2.获取hash值
String keywordHash = getHash(keword);
if(keywordHash.length() < 128){
//若hash值可能少于128位,用0补齐低位
int dif = 128 - keywordHash.length();
for(int j = 0;j < dif;j++ ){
keywordHash += "0";
}
}
3. 加权,通过第2步的hash生成结果,按照单词的权重形成加权数字串。
4. 合并,把上面各个单词算出来的序列值累加,变成只有一个序列串。
//3&4. 加权并合并
for (int j = 0;j < arr.length; j++ ){
//对keywordHash的每一位与'1'进行比较
if (keywordHash.charAt(j) == '1'){
//权重共分10级,由词频从高到低,取0~10
arr[j] += (10 - (i / (size /10)));
} else {
arr[j] -= (10 - (i / (size /10)));
}
}
i++;
}
5. 降维。
//5.降维
String simHash = ""; //储存返回的simHash值
for(int j =0; j < arr.length; j++){
//从高位遍历至低位
if (arr[j] <= 0){
simHash += "0";
} else {
simHash += "1";
}
}
return simHash;
}
HammingUtils工具类的主要算法
- 计算Hamming距离
通过海明距离(Hamming distance)就可以计算出两个simhash到底相似不相似。两个simhash对应二进制(01串)取值不同的数量称为这两个simhash的海明距离。例: 10101 和 00110 从第一位开始依次有第一位、第四、第五位不同,则海明距离为3。对于二进制字符串的a和b,海明距离为等于在a XOR b运算结果中1的个数(普遍算法)。
/**
* 计算Hamming距离
* @param simHashYuan 原文simHash值
* @param simHashFang 仿文simHash值
* @return distance 海明距离
*/
public static int getHammingDistence(String simHashYuan,String simHashFang){
int distance = 0;
if(simHashYuan.length()!=simHashFang.length()){
distance = -1; //simHash的长度需要相同
} else {
for (int i = 0; i < simHashYuan.length(); i++){
if (simHashYuan.charAt(i) != simHashFang.charAt(i)){
distance++;
}
}
}
return distance;
}
- 相似度计算
/**
* 相似度计算
* @param simHashYuan
* @param simHashFang
* @return 相似度
*/
public static double getSimilarity(String simHashYuan,String simHashFang){
int distance = getHammingDistence(simHashYuan,simHashFang);
double result = 0.01 * (100 -distance * 100/128);
return result;
}
}
三、接口部分的性能改进
遥测截图
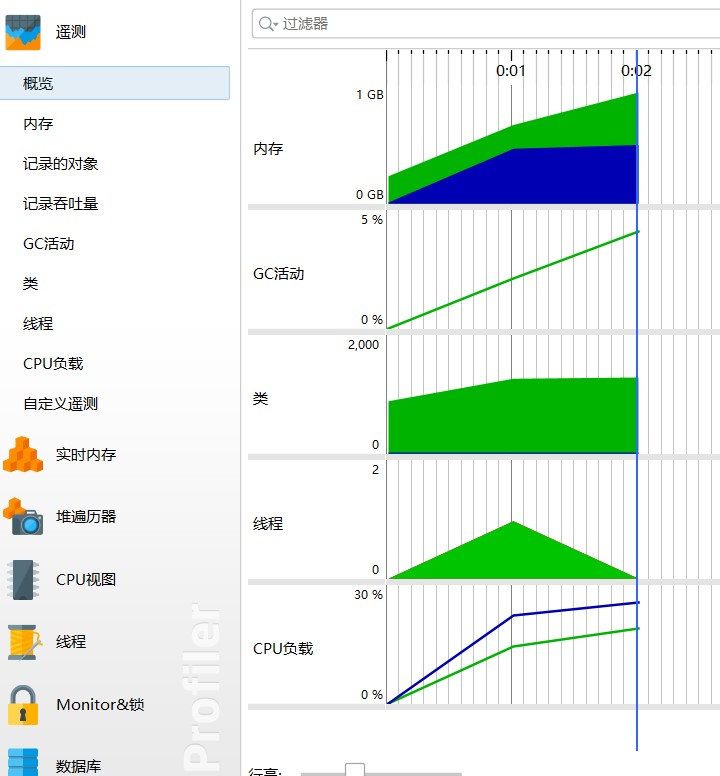
内存的调用情况
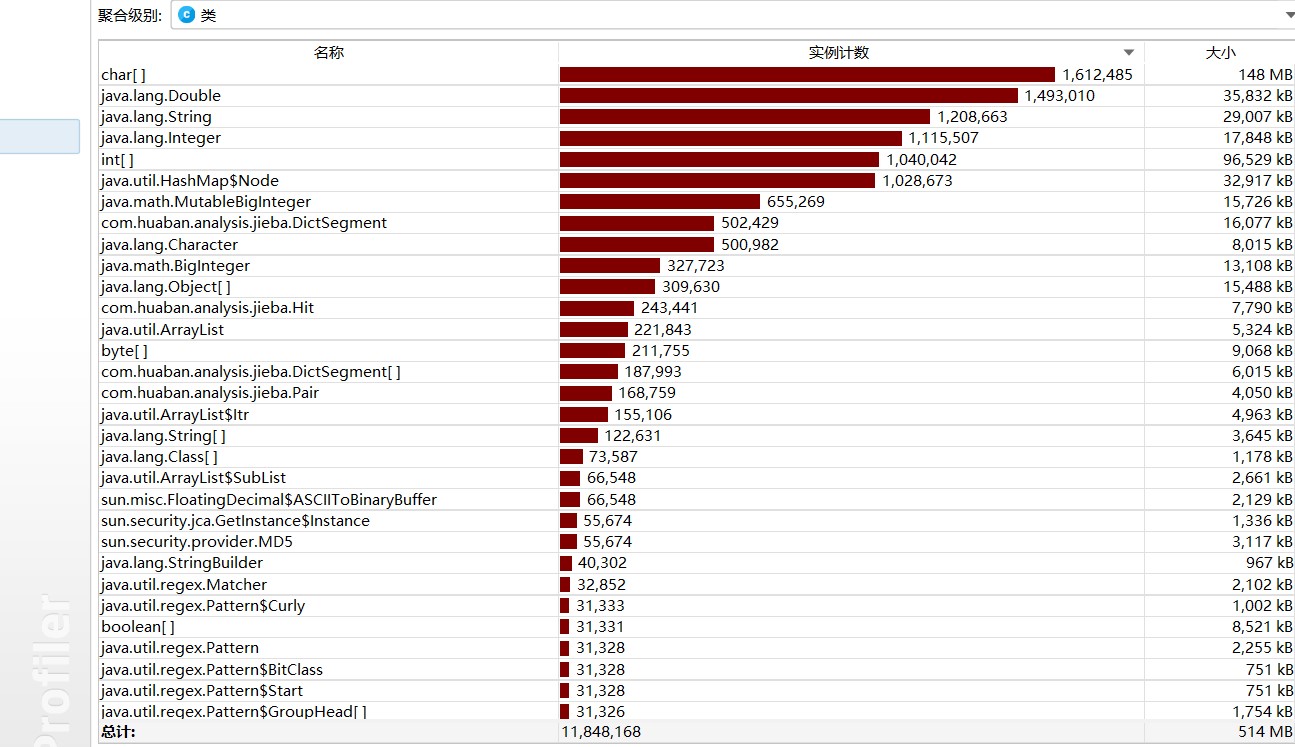

四、部分单元测试展示
主程序测试单元
- 思路
查重所有的测试用例 - 代码
@Test
public void origAndAllTest(){
String[] str = new String[6];
str[0] = FilesUtils.readFile("D:/workSpace/testFiles/orig.txt");
str[1] = FilesUtils.readFile("D:/workSpace/testFiles/orig_0.8_add.txt");
str[2] = FilesUtils.readFile("D:/workSpace/testFiles/orig_0.8_del.txt");
str[3] = FilesUtils.readFile("D:/workSpace/testFiles/orig_0.8_dis_1.txt");
str[4] = FilesUtils.readFile("D:/workSpace/testFiles/orig_0.8_dis_10.txt");
str[5] = FilesUtils.readFile("D:/workSpace/testFiles/orig_0.8_dis_15.txt");
String ansFileName = "D:/workSpace/testFiles/ansAll.txt";
for(int i = 0; i <= 5; i++){
double ans = HammingUtils.getSimilarity(SimHash.getSimHash(str[0]), SimHash.getSimHash(str[i]));
FilesUtils.writeFile(ans, ansFileName);
}
}
- 测试结果
![]()
![]()
![]()

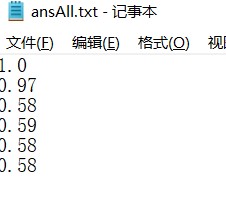
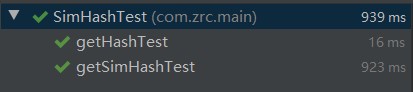
SimHash测试单元
- 思路
测试计算SimHash和计算Hash值 - 代码
@Test
public void getHashTest(){
String[] strings = {"广东", "是", "中国", "的", "一个", "省"};
for (String string : strings) {
String stringHash = SimHash.getHash(string);
System.out.println(stringHash.length());
System.out.println(stringHash);
}
}
@Test
public void getSimHashTest(){
String str0 = FilesUtils.readFile("D:/workSpace/testFiles/orig.txt");
String str1 = FilesUtils.readFile("D:/workSpace/testFiles/orig_0.8_add.txt");
System.out.println(SimHash.getSimHash(str0));
System.out.println(SimHash.getSimHash(str1));
}
- 测试结果
![]()
![]()

Hamming工具类单元
- 思路
测试Hamming距离计算和相似度计算 - 代码
@Test
public void getHammingDistanceTest() {
String str0 = FilesUtils.readFile("D:/workspace/testFiles/orig.txt");
String str1 = FilesUtils.readFile("D:/workspace/testFiles/orig_0.8_add.txt");
int distance = HammingUtils.getHammingDistance(SimHash.getSimHash(str0), SimHash.getSimHash(str1));
System.out.println("海明距离:" + distance);
System.out.println("相似度: " + (100 - distance * 100 / 128) + "%");
}
@Test
public void getHammingDistanceFailTest() {
// 测试str0.length()!=str1.length()的情况
String str0 = "10101010";
String str1 = "1010101";
System.out.println(HammingUtils.getHammingDistance(str0, str1));
}
@Test
public void getSimilarityTest() {
String str0 = FilesUtils.readFile("D:/workspace/testFiles/orig.txt");
String str1 = FilesUtils.readFile("D:/workspace/testFiles/orig_0.8_add.txt");
int distance = HammingUtils.getHammingDistance(SimHash.getSimHash(str0), SimHash.getSimHash(str1));
double similarity = HammingUtils.getSimilarity(SimHash.getSimHash(str0), SimHash.getSimHash(str1));
System.out.println("str0和str1的汉明距离: " + distance);
System.out.println("str0和str1的相似度:" + similarity);
}
- 测试结果
![]()
![]()


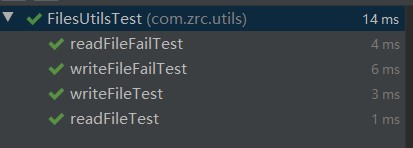
读写工具类单元
- 思路
测试四种情况:路径存在,正常读取;路径存在,正常写入;路径不存在,读取失败;路径不存在,写入失败。 - 代码
@Test
public void readFileTest() {
// 路径存在,正常读取
String str = FilesUtils.readFile("D:/workspace/testFilesorig.txt");
String[] strings = str.split(" ");
for (String string : strings) {
System.out.println(string);
}
}
@Test
public void writeFileTest() {
// 路径存在,正常写入
double[] elem = {0.15, 0.3, 0.45, 0.6, 0.75};
for (int i = 0; i < elem.length; i++) {
FilesUtils.writeFile(elem[i], "D:/workspace/testFilesans.txt");
}
}
@Test
public void readFileFailTest() {
// 路径不存在,读取失败
String str = FilesUtils.readFile("D:/workspace/testFilesnone.txt");
}
@Test
public void writeFileFailTest() {
// 路径错误,写入失败
double[] elem = {0.15, 0.3, 0.45, 0.6, 0.75};
for (int i = 0; i < elem.length; i++) {
FilesUtils.writeFile(elem[i], "User:/workspace/testFile/ans.txt");
}
}
- 测试结果
![]()
![]()
五、异常处理
- 思路
因为simhash用于比较大文本效果更好,例如500字以上,距离小的基本都是相似,影响误判率,且文本太短不易分词。
当文本太短时,应抛出异常,将此类异常继承Exception,提示文本过短。
设计一个短文本用例测试。 - 代码
//simhash用于比较大文本效果更好,例如500字以上,距离小的基本都是相似,影响误判率
//且文本太短不易分词
try {
if(str.length()<500) throw new ShortTextException("文本太短,请输入大于500字的文本!");
} catch (ShortTextException e) {
e.printStackTrace();
return str;
}
@Test
public void shortStringExceptionTest(){
//测试str.length()<500的情况
System.out.println(SimHash.getSimHash("广东省是中国的一个省"));
}
- 结果
![]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号