【Scrapy笔记】使用方法
安装:
1、pip install wheel 安装wheel
2、安装Twisted
a.访问 http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted 下载Twisted-17.9.0-cp36-cp36m-win_amd64.whl
b.进入文件所在目录 pip install Twisted-17.1.0-cp35-cp35m-win_amd64.whl
3、pip3 install scrapy 安装scrapy
使用:
1、scrapy startprojec 项目名称 创建项目
2、 cd 项目名称 进入项目目录
3、scrapy genspider xxx xxx.com 创建爬虫文件 例如,要创建oppo爬虫文件,则scrapy genspider oppo www.oppo.cn
4、scrapy crawl xxx 运行爬虫文件 在当前目录下,运行oppo爬虫 scrapy crawl oppo
5、scrapy crawl xxx -o file.json 运行爬虫,并把文件存放到指定文件中,多用来调试!
注意事项:去settings .py 中注释掉 ROBOTSTXT_OBEY = True (如项目无其他侵权功能,则可以注释“鉴别是否允许爬取”)
域名有www 则需要加上www, 如果当前页面添加ssl加密传输,则需要去oppo.py中修改http为https
重点:yield下 ,callback如果不指定回调函数,则默认结束时,会回调一次parse
调试方法:
scrapy shell 域名
scrapy shell -s USER_AGENT="Mozilla/5.0 (X11; Linux i686; U;) Gecko/20070322 Kazehakase/0.4.5" 域名 注意: 调试中增加请求头,USER_AGENT=后面必须是英文状态下的双引号,单引号会报错
scrapy shell https://www.oppo.cn
scrapy shell https://www.oppo.cn/topic/index/thread.json?page=1&limit=20&type=3&id=856
域名后面&换行后无法连接成整个域名,则可: scrapy shell "www.oppo.cn/topic/index/thread.json?page=1&limit=20&type=3&id=856" 去掉"https://"
CSS选择器使用
response.css("#ID dt::text") 提取文本信息
response.css('.class p::attr(href)').extract() 提取属性信息 显示所有
response.css('.class p::attr(href)').extract_first() 提取属性信息 显示第一条
html对象转换:
import parsel
data=parsel.Selector(html_str)
Spider 注意事项:
allowed_domains = ['qiushibaike.com'] 这是正确匹配规则,
错误示范:
1 、allowed_domains = ['www.qiushibaike.com'] 主域名前面添加 www
2 、allowed_domains = ['qiushibaike.com/text'] 主域名后面添加多余页码
创建crawl_spider
1、scrapy startproject 项目名称
2、cd 项目名称
3、scrapy genspider xxx -t crawl xxx '域名'
Spider
关于Spider的使用方法:
name='xx'
name必须是唯一的
allowed_domains=['xxxx.com']
设置爬虫的规则,url不在规则范围之内的,不予爬取
start_urls=['xxxxx.com']
初始url链接
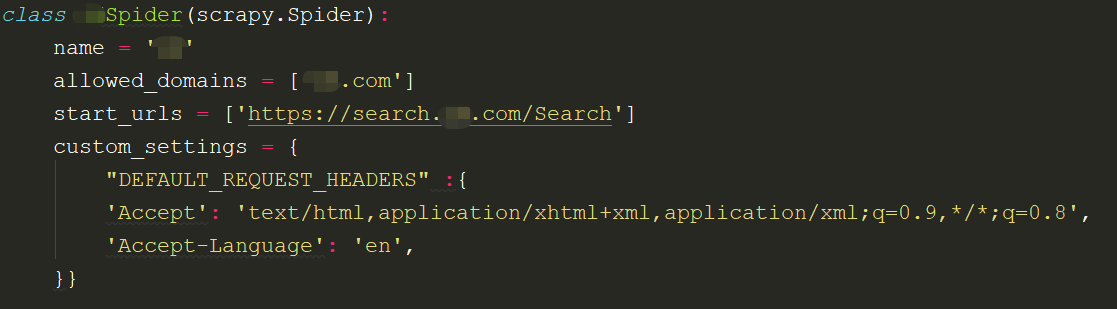
custom_srttings
它是一个字典,是专属于spider的配置,此方法会覆盖全局的配置,此设置必须在初始化前更新,必须定义类变量
GET

POST

crawl_Spider
创建crawl_spider 的方法:
scrapy startproject xxx
cd xxx
scrapy genspider -t crawl xxx xxx.xom
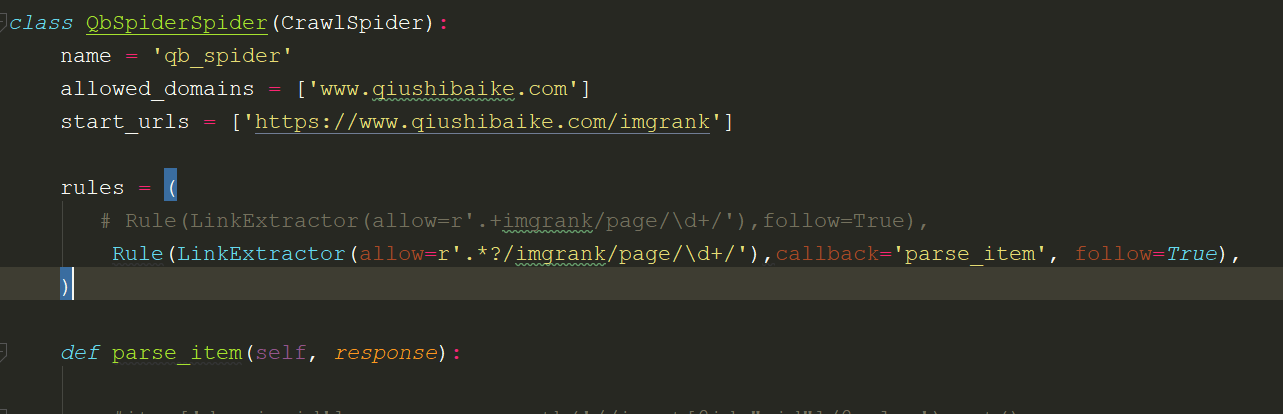
LinkExtractors链接提取器:


Settings
关于settings调用到方法:
1.在spider.py文件中,可以直接使用 self.settings.get('XXX') 获取
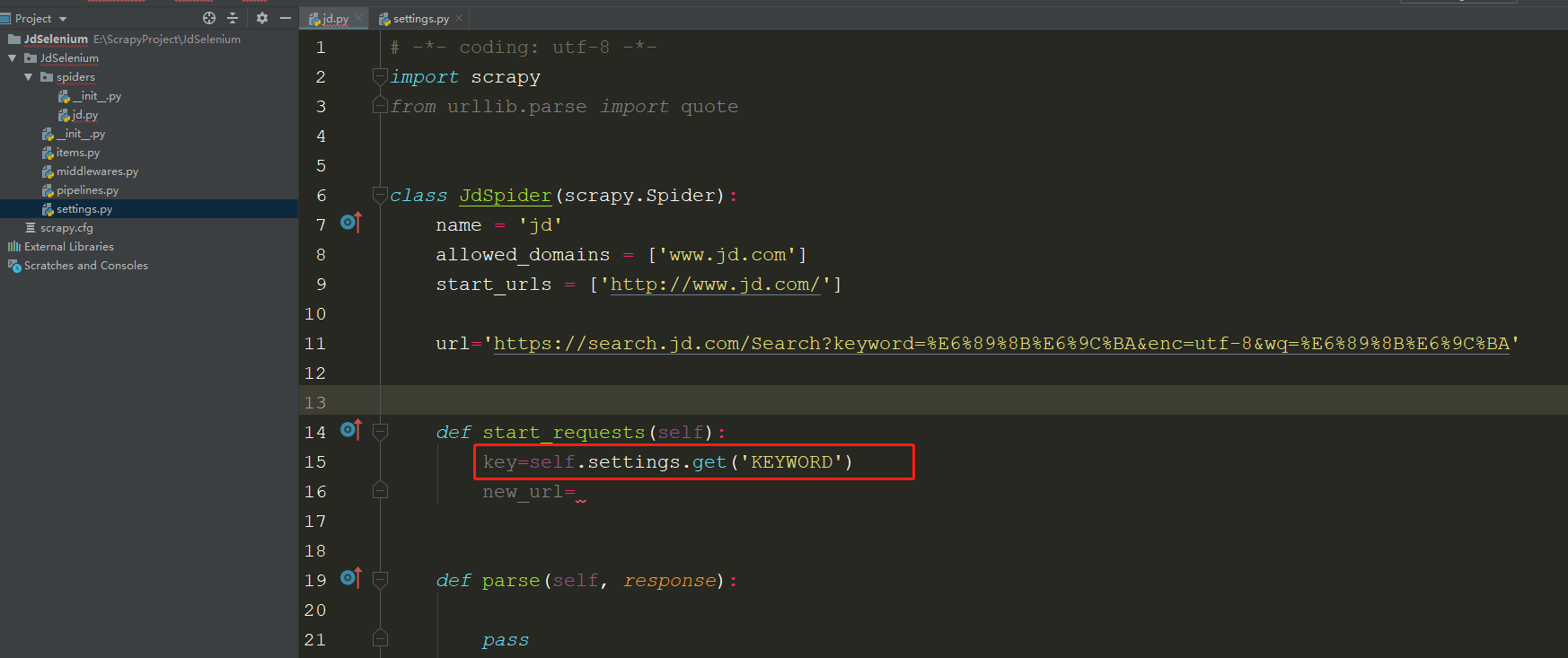
2.在Middleware中使用settings的方法:

MiddleWares
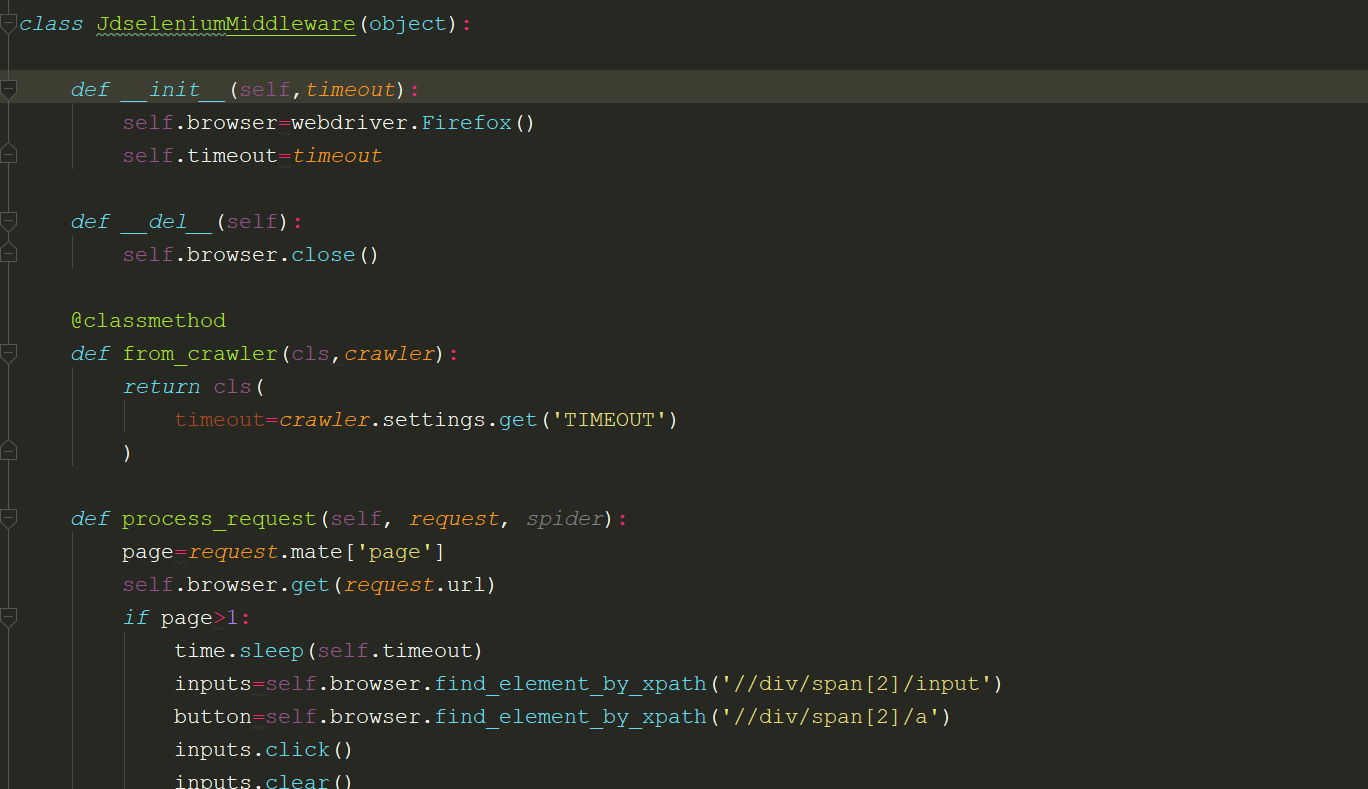
在middlewares中修改response下载器为selenium的方法:
注意事项:需要在settings中将downloader_middlewares反注释,并将红色文字部分修改成你的middlewares类名:
DOWNLOADER_MIDDLEWARES = {
'JdSelenium.middlewares.JdseleniumMiddleware': 543,
}
如果要修改下载中间件,则需要使用start_requests方法

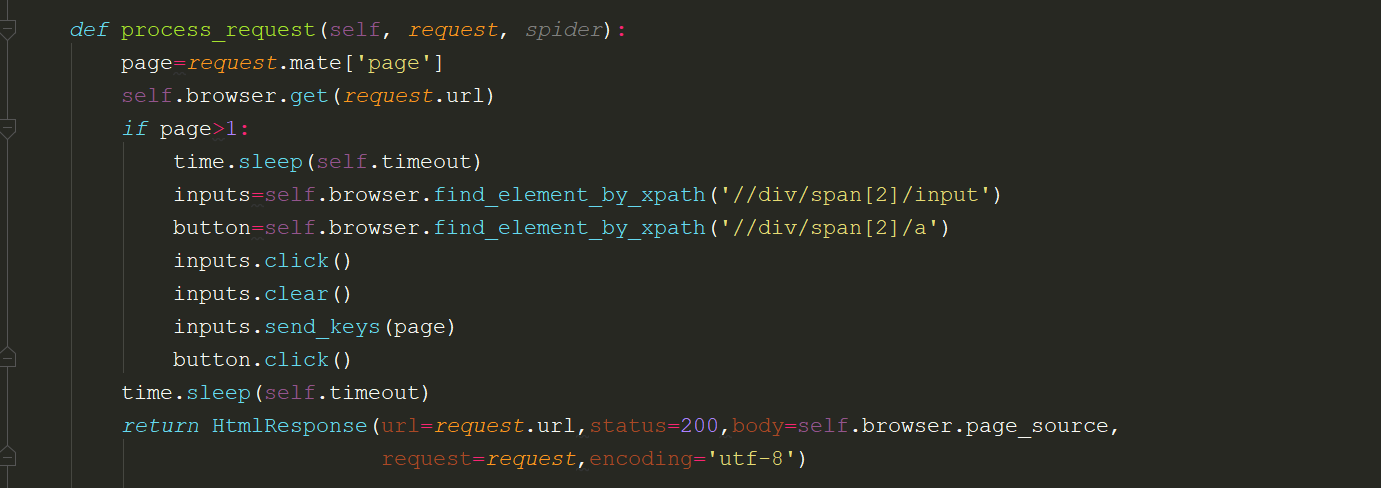
添加IP代理池
Httpbin.org相关测试接口
https://blog.csdn.net/chang995196962/article/details/91362364
ip代理:https://www.xicidaili.com/wt/
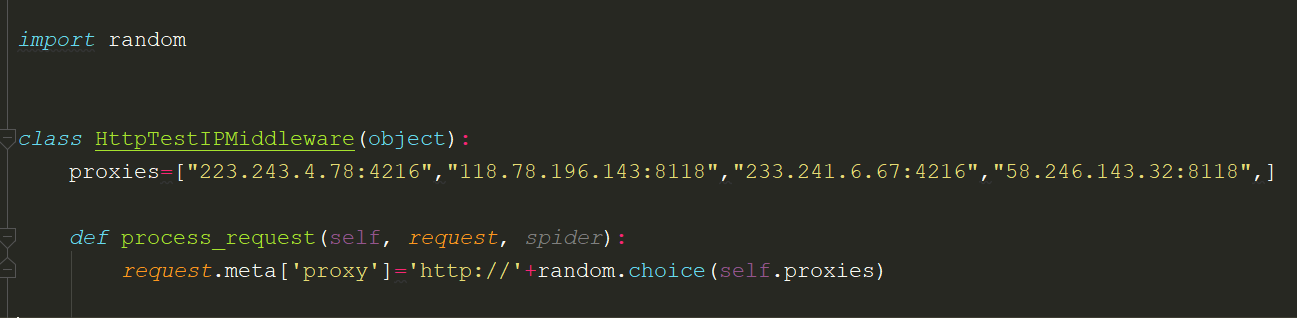
校验IP不可用后,更换IP代理
requests中添加ip代理,一定要使用字典格式,否则就会报错
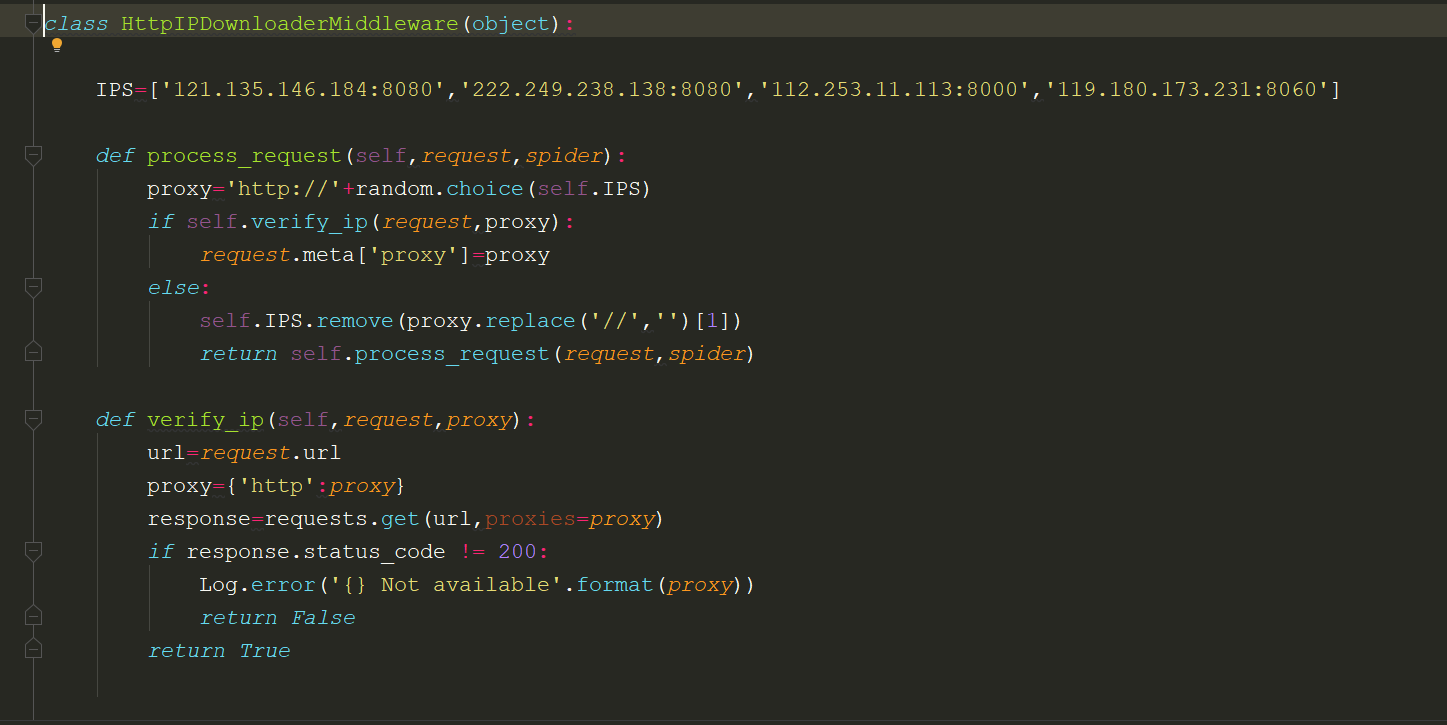
添加随机请求头
User_Agent 集合:http://useragentstring.com/pages/useragentstring.php
Pipeline
Scrapy.imagesPipeline:
不论是FILES_STORE 还是IMAGE_STORE,路径一定要懂'\' 来表示: IMAGES_STORE='D:\IM'
下载文件的 Files Pipeline :
当时用 Files Pipeline 下载文件的时候,按照以下步骤完成:
1.定义好一个Item,然后在这个item中定义两个属性,分别为 file_urls以及files。file_urls 用来存储需要下载的文件的url链接,需要给一个列表
file_urls=scrapy.Field()
files=scrapy.Field()
2.当文件下载完成后,会把文件下载的相关信息存储到item 的files属性中,比如下载路径,下载的url和文件的校验码等。
3.在配置文件 settings.py 中配置 FILES_STORE,这个配置是用来设置下载下来的路径
4.启动pipeline: 在settings.py中的ITEM_PIPELINES中设置 scrapy.pipelines.files.FilesPipeline:1
下载图片的 Images Pipelins:
当时用 Files Pipeline 下载文件的时候,按照以下步骤完成:
1.定义好一个Item,然后在这个item中定义两个属性,分别为 file_urls以及files。file_urls 用来存储需要下载的文件的url链接,需要给一个列表
image_urls=scrapy.Field()
images=scrapy.Field()
2.当文件下载完成后,会把文件下载的相关信息存储到item 的images属性中,比如下载路径,下载的url和文件的校验码等。
3.在配置文件 settings.py 中配置 IMAGES_STORE,这个配置是用来设置下载下来的路径
4.启动pipeline: 在settings.py中的ITEM_PIPELINES中设置 scrapy.pipelines.images.ImagesPipeline:1
在settings中设置plpelines,

![]()
当要修改下载路径或者文件加名称从被爬取的网页中获取时,当重写父类方法:
from scrapy.pipelines.images import ImagesPipeline
from QB import settings
import os
class QbImagesPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
# 这个方法是在发送下载请求之前调用
# 其实这个方法本身就是去发送下载请求的
request_objs = super(QbImagesPipeline, self).get_media_requests(item, info)
for request_obj in request_objs:
request_obj.item = item
return request_objs
def file_path(self, request, response=None, info=None):
path = super(QbImagesPipeline, self).file_path(request, response, info)
# 文件路径分类,从item中拿到的文件夹名称,一般是从网上获取的名称
category = request.item.get('category')
images_store = settings.IMAGES_STORE
# 将settings中设置的路径与item中的路径拼接
category_path = os.path.join(images_store, category)
if not os.path.exists(category_path):
os.mkdir(category_path)
# 将父类中的路径分割,得到图片名称
image_name = path.replace('full/', '')
image_path = os.path.join(category_path, image_name)
return image_path
Plpeline Mysql数据存储
同步IO存储
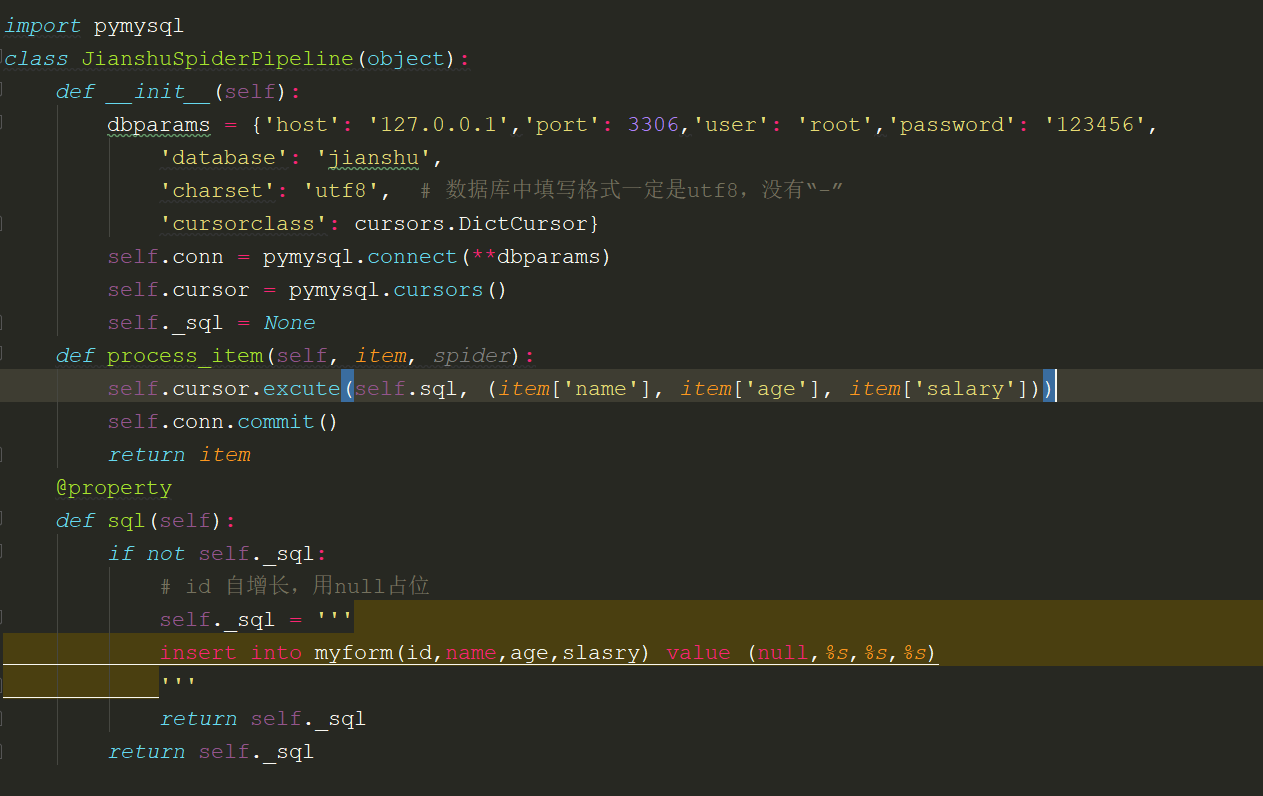
异步IO存储


 浙公网安备 33010602011771号
浙公网安备 33010602011771号