机器学习实战总结
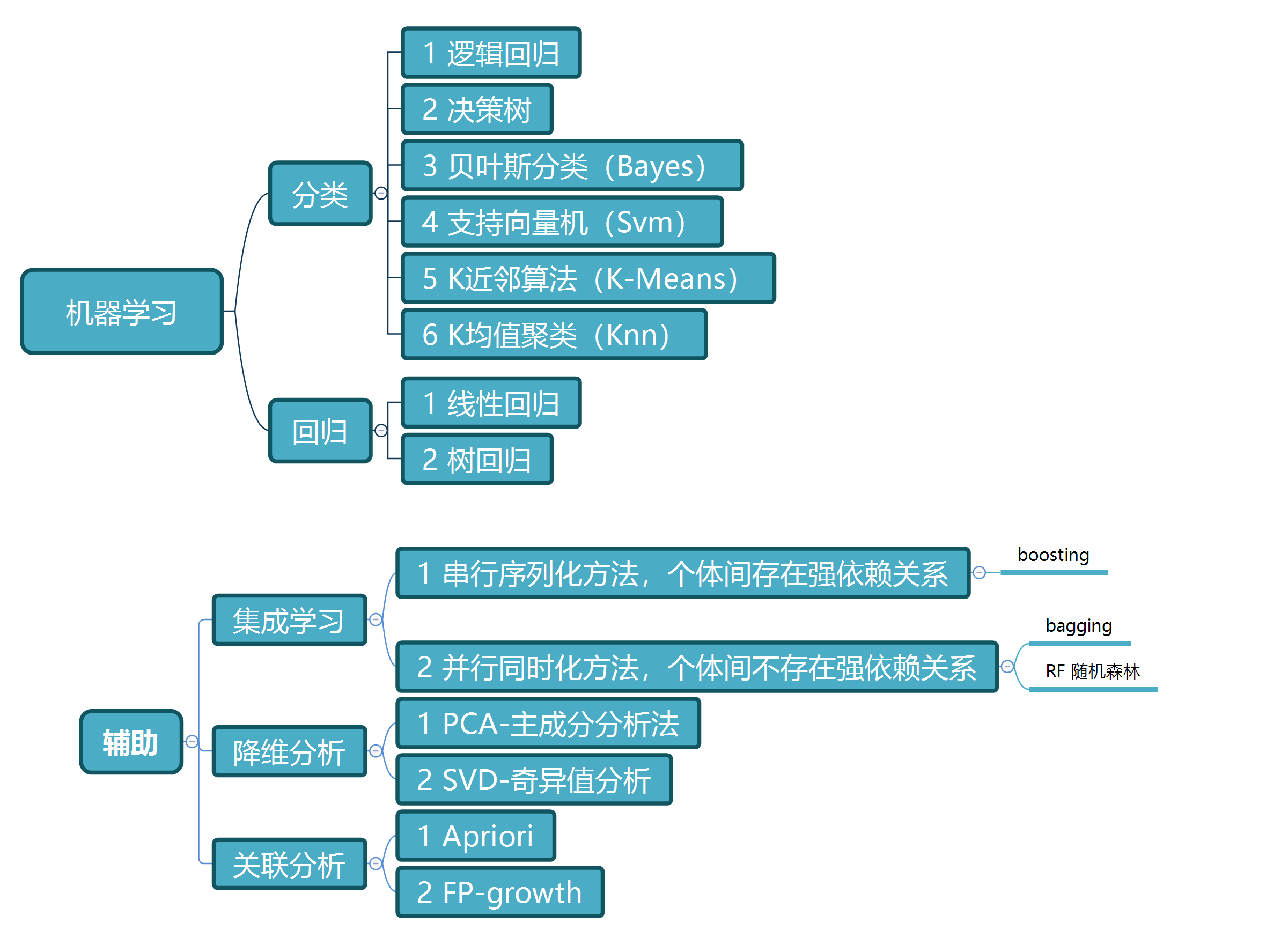
1. 分类
-
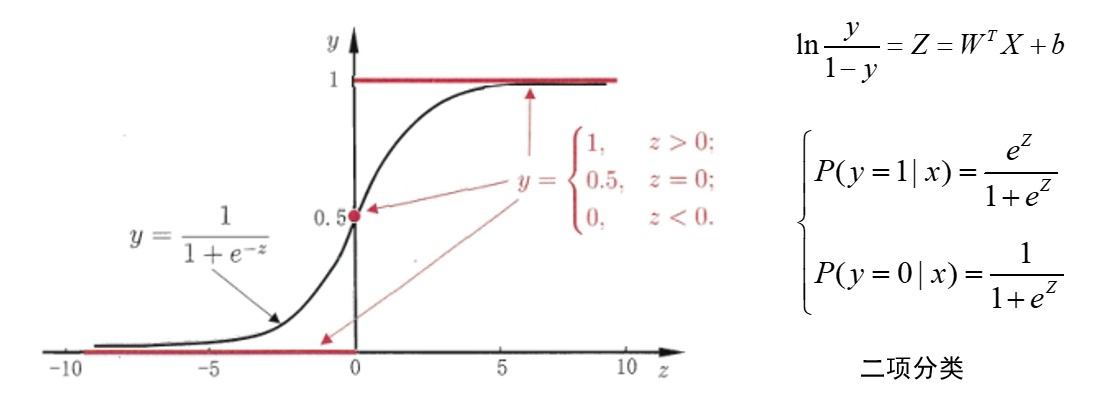
逻辑回归
使用线性回归来预测z的值,放入逻辑回归分类器,判断分类。(注意虽然名字叫回归,其实是一个分类器)
-
决策树
决策树分类,从根节点开始,对实例的某一特征进行测试,根据测试结果,将实例分配到子节点,,这时,每一个子节点代表该特征取值,如此递归分配,直至叶节点,最后将实例分配到叶节点的类中。
https://www.cnblogs.com/Ray-0808/p/10758164.html

-
贝叶斯分类(Bayes)
基于贝叶斯定理与特征条件独立假设的分类。首先基于特征独立条件独立假设学习输入/输出的联合概率分布,然后基于该模型,对于给定的输入x,利用贝叶斯定理求出后验概率最大的输出y。
https://www.cnblogs.com/Ray-0808/p/10773111.html

-
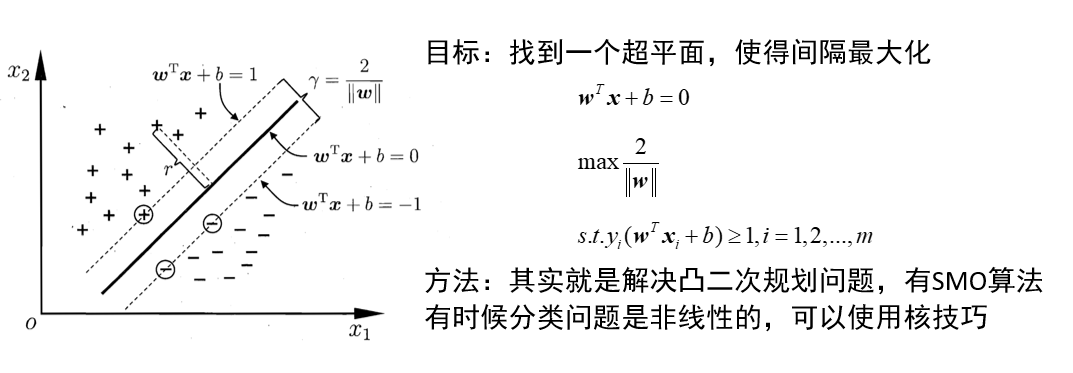
支持向量机(SVM)
支持向量机是一种二分类模型,它的基本想法是基于训练集D在样本空间中找到一个划分超平面,将不同的样本分开。学习策略即为间隔最大化。
https://www.cnblogs.com/Ray-0808/p/10798320.html
-
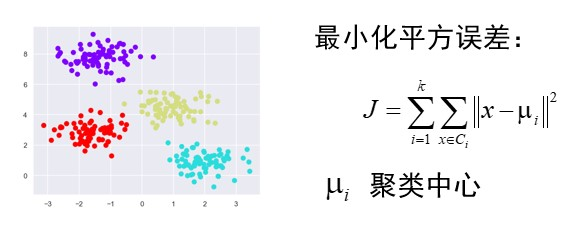
k均值聚类(KNN)
是一种无监督聚类算法,找出 k 个聚类中心,使得各类的聚类平方和最小。
https://www.cnblogs.com/Ray-0808/p/10641504.html
2. 回归
-
线性回归

-
树回归
CART 分类与回归树,决策树的生成就是递归地构建二叉决策树的过程,对回归树用平方误差最小准则,对分类树用基尼指数最小化准则,进行特征选择,生成二叉树。
https://www.cnblogs.com/Ray-0808/p/10939465.html

3. 集成学习
-
boosting
代表有adaboost,利用一系列弱分类器,按权值线性组合成一个强分类器。
-
bagging
并行式集成学习方法最著名的代表。给定包含 m 个样本的数据集,我们先随机取出一个样本放入采样集中,再把该样本放回初始数据集(自主采样法),使得下次采样时该样本仍有可能被选中,这样经过 m 次随机采样操作,我们得到含 m 个样本的采样集,初始训练集中约有 63.2%的样本出现在采样集中。照这样,我们可以采样出 T 个含 m 个训练样本的采样集,然后基于每个采样集训练出一个基学习器,再将这些基学习器结合。
-
RF 随机森林
随机森林是 bagging 的一个变体,其以决策树为基学习器构建 bagging 集成的基础上,进一步在决策树的训练过程中引入了随机属性选择。具体来说,传统决策树在选择划分时是在当前节点的属性集合中选择一个最优属性,而在 RF 中,对基决策树的每个结点,先从该结点的属性集合中随机选择一个包含 k 的属性子集,然后在再从这个子集中选择一个最优属性划分。
4. 降维分析
-
PCA-主成分分析法
本质上是将原始数据集影射到低维坐标系中,各坐标轴直接相关性小,即协方差小,使用前面几个含有大量信息的维度,去除噪声,更易快速分析。
-
SVD-奇异值分析
奇异值分解能够将原始数据集在样本数量和样本特征两个方向上都能影射,既可以做到 PCA 一样的特征降维,又可以做到样本数量降维,即去除大量重复或无用样本。
5. 关联分析
-
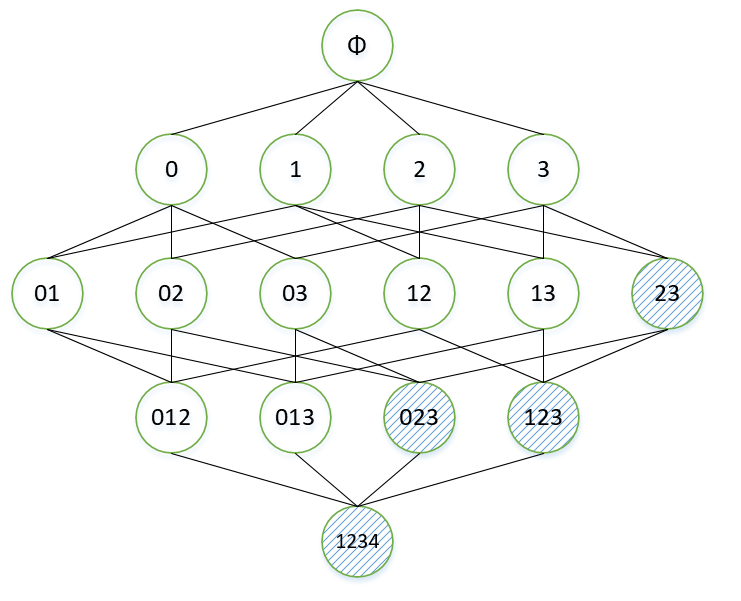
Apriori
主要思想为:如果某一个项集是非频繁项集,那么它的所有超集也是非频繁的。
-
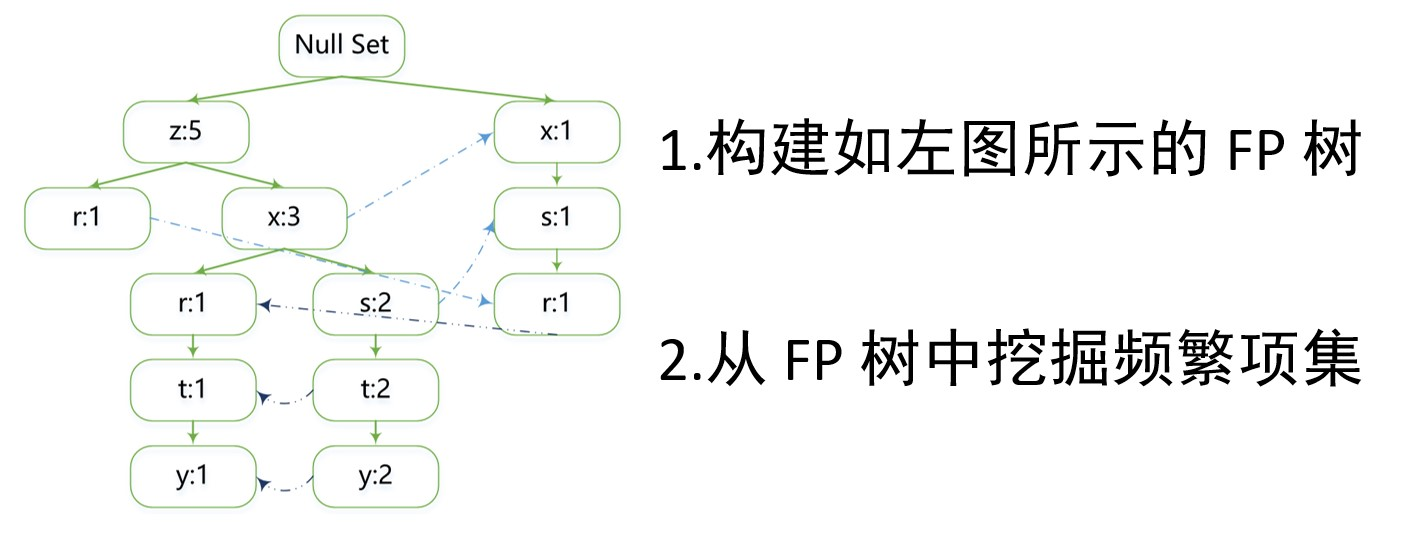
FP-growth
一个非常好的频繁项集发现算法,关键在于构建 FP 树,比 Apriori 要快,只用对数据集进行两次扫描。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号