机器学习实战 9-FP-growth算法
1 FP树
1.1 FP介绍
将数据结构存储在一种称为FP树的紧凑数据结构中,如图:
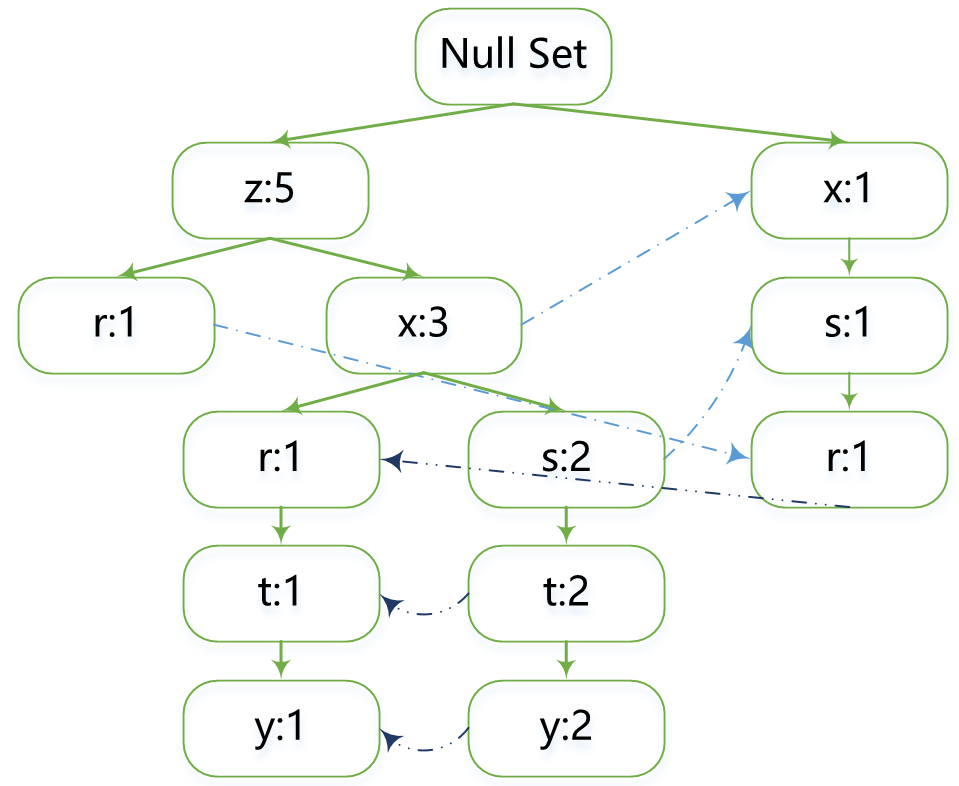
一般流程:

-
输入数据,构建出一个如上图所示的数据结构(可以理解为按每条数据集合一步一步建立出来的树),即FP树
-
从FP树中挖掘频繁项集
-
从FP树中获得条件模式基(以某查找元素为结尾的路径集合,如y元素的条件模式基为{[t,s,x,z],[t,r,x,z]})
-
利用条件模式基再构建条件FP树(这里是有频次阈值要求的)
-
迭代 a,b ,直到树中只包含一个元素为止。此时已经找到满足阈值条件所有频繁项集。
(阈值要求:即频繁次数的最低要求,如要求某元素或者集合至少出现100次)
1.2 与Apriori对比
之前学的关联算法是Apriori,它对每个潜在的频繁项集都会扫描数据集判定给定模式是否频繁,而此处介绍的FP-growth只需对数据库进行两次扫描,因此较快。当输入数据量比较大时,FP树优势较明显
2 python实现及图解
2.1 创建FP树的数据结构
包含存放节点的名字及计数值,nodeLink用于存放链接元素。
1 # 建立FP树的类定义 2 class treeNode: 3 def __init__(self,nameValue,numOccur,parrentNode): 4 self.name=nameValue # 存放节点名字 5 self.count=numOccur # 存放计数值 6 self.nodeLink=None # 链接相似的元素项 7 self.parent=parrentNode # 指向父节点 8 self.children={} # 存放子节点 9 def inc(self,numOccur): 10 self.count +=numOccur 11 def disp(self,ind=1): 12 print(' '*ind,self.name,' ',self.count) 13 for child in self.children.values(): 14 child.disp(ind+1)
2.2 构建FP树
算法过程:
-
统计所有元素出现的频次,并删去不满足阈值的元素
-
创建一个头指针表headerTable,用来存放各元素总数,并存放指针(即位置)
-
遍历每一个集合
-
选取集合中满足要求的元素,并将它们顺序按照总频数从多到少的排列(orderedItem),从上往下建立树,并往headerTable中填充指针
-
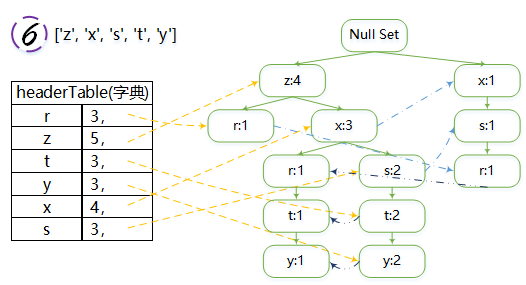
当headerTable中某一元素已经含有指针时,如遍历到第四次时的x,此时利用updateHeader函数,用nodeLink链接(图4中x到x的蓝色虚线)
-
-
程序如下:


1 # 建立FP树的类定义 2 class treeNode: 3 def __init__(self,nameValue,numOccur,parrentNode): 4 self.name=nameValue # 存放节点名字 5 self.count=numOccur # 存放计数值 6 self.nodeLink=None # 链接相似的元素项 7 self.parent=parrentNode # 指向父节点 8 self.children={} # 存放子节点 9 10 def inc(self,numOccur): 11 self.count +=numOccur 12 13 def disp(self,ind=1): 14 print(' '*ind,self.name,' ',self.count) 15 for child in self.children.values(): 16 child.disp(ind+1) 17 18 # FP树构建函数 19 def createTree(dataSet, minSup=1): 20 # 使用字典作为数据结构,保存头指针 21 headerTable={} 22 # 遍历数据集,获得每个元素的出现频率 23 for trans in dataSet: 24 # print(trans) 25 for item in trans: 26 headerTable[item]=headerTable.get(item,0)+dataSet[trans] 27 # 删去出现频率少的小伙伴 28 for k in list(headerTable.keys()): 29 if headerTable[k]<minSup: 30 del(headerTable[k]) 31 freqItemSet=set(headerTable.keys()) 32 if len(freqItemSet)==0: 33 return None,None 34 for k in headerTable: 35 headerTable[k]=[headerTable[k],None] 36 reTree=treeNode('Null Set',1,None) 37 for tranSet,count in dataSet.items(): 38 localD={} 39 for item in tranSet: 40 if item in freqItemSet: 41 localD[item]=headerTable[item][0] 42 if len(localD)>0: 43 # 根据出现的频次对localD进行排序 44 orderdItems=[v[0] for v in sorted(localD.items(),key=lambda p:p[1],reverse=True)] 45 print(orderdItems) 46 updateTree(orderdItems,reTree,headerTable,count) 47 return reTree,headerTable 48 49 def updateTree(items,inTree,headerTable,count): 50 # 判断是否子节点,如果是,更新计数,如果不是创建子节点 51 if items[0] in inTree.children: 52 inTree.children[items[0]].inc(count) 53 else: 54 inTree.children[items[0]]=treeNode(items[0],count,inTree) 55 if headerTable[items[0]][1]==None: 56 headerTable[items[0]][1]=inTree.children[items[0]] 57 else: 58 updateHeader(headerTable[items[0]][1],inTree.children[items[0]]) 59 # 循环创建 60 if len(items)>1: 61 updateTree(items[1::],inTree.children[items[0]],headerTable,count) 62 # 更新指针链接 63 def updateHeader(nodeToTest,targetNode): 64 while (nodeToTest.nodeLink != None): 65 nodeToTest=nodeToTest.nodeLink 66 nodeToTest.nodeLink=targetNode 67 68 def loadSimpDat(): 69 simpDat = [['r', 'z', 'h', 'j', 'p'], 70 ['z', 'y', 'x', 'w', 'v', 'u', 't', 's'], 71 ['z'], 72 ['r', 'x', 'n', 'o', 's'], 73 ['y', 'r', 'x', 'z', 'q', 't', 'p'], 74 ['y', 'z', 'x', 'e', 'q', 's', 't', 'm']] 75 return simpDat 76 77 # 将输入数据列表转换为字典 78 def createInitSet(dataSet): 79 retDict = {} 80 for trans in dataSet: 81 retDict[frozenset(trans)] = 1 82 return retDict 83 84 simpDat=loadSimpDat() 85 # print(simpDat) 86 initSet=createInitSet(simpDat) 87 # print(initSet) 88 myFPtree,myHeaderTab=createTree(initSet,3) 89 a=myFPtree.disp() 90 print(myHeaderTab)
图解:

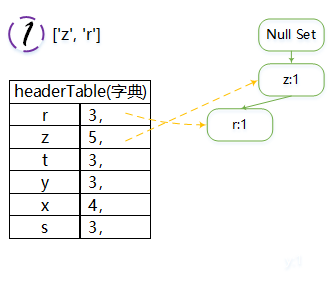

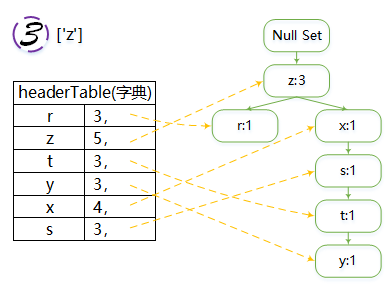
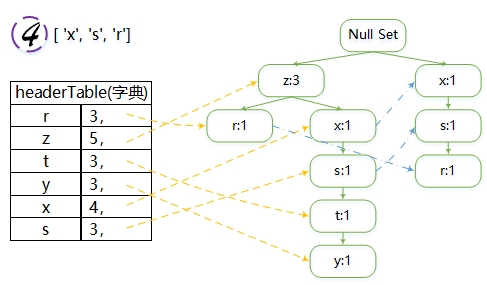

注意:
-
每一次都是从根本节点“Null Set”开始,往下建立
-
注意nodeLink保存位置,主要由updateHeader函数起作用
-
由于频次相同的元素较多(如r,t,y,s),每次生成树可能不太一样
-
2.3 抽取条件模式基
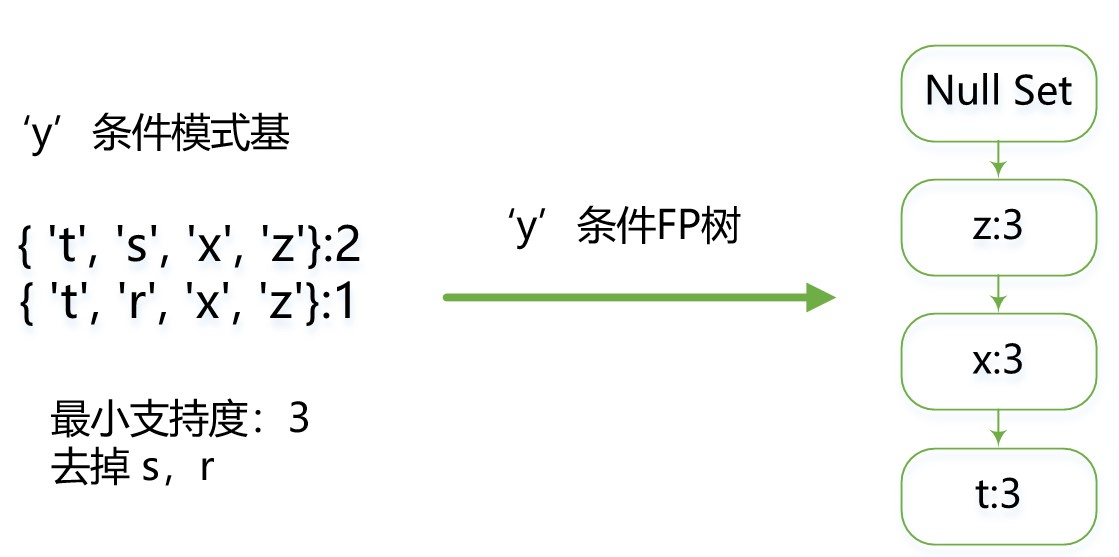
前面说过,条件模式基就是以所查找元素为结尾的路径集合。即以某元素为起点,往上追溯的路径集合。如上面 t 的条件模式基为 {{s,x,z}:2,{r,x,z}:1} 。
程序:
1 # 递归回溯树,从本节点一直往上 2 def ascendTree(leafNode,prefixPath): 3 if leafNode.parent != None: 4 prefixPath.append(leafNode.name) 5 ascendTree(leafNode.parent,prefixPath) 6 7 # 找到需查找元素的所有前缀路径 8 def findPrefixPath(basePat,treeNode): 9 condPats={} 10 while treeNode != None: 11 prefixPath=[] 12 ascendTree(treeNode,prefixPath) 13 if len(prefixPath)>1: 14 condPats[frozenset(prefixPath[1:])]=treeNode.count 15 treeNode=treeNode.nodeLink 16 return condPats 17 18 simpDat=loadSimpDat() 19 # print(simpDat) 20 initSet=createInitSet(simpDat) 21 # print(initSet) 22 myFPtree,myHeaderTab=createTree(initSet,3) 23 a=myFPtree.disp() 24 print(myHeaderTab) 25 print(myFPtree) 26 for item in list(myHeaderTab.keys()): 27 print(findPrefixPath(item,myHeaderTab[item][1]))

2.4 创建条件FP树
利用条件模式基,创建FP树,........循环,直到树中只包含一个元素,这就是一个找频繁项集的过程(一元的、二元的、.....等等多元的,各种类型的,所有满足条件的组合)
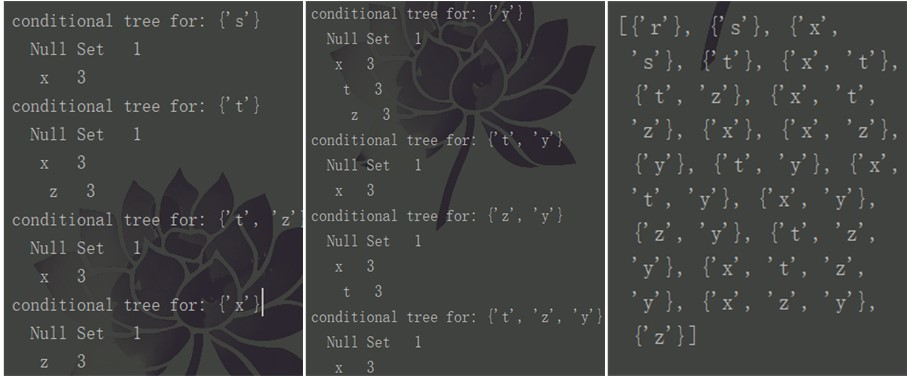
1 # 创建条件FP树 2 def mineTree(inTree,headerTable,minSup,preFix,freqItemList): 3 # 此处原文有错误 4 # 从头指针的底端开始 5 bigL=[v[0] for v in sorted(headerTable.items(),key=lambda p:p[0])] 6 for basePat in bigL: 7 newFreqSet=preFix.copy() 8 newFreqSet.add(basePat) 9 freqItemList.append(newFreqSet) 10 # 创建条件基 11 condPattBases=findPrefixPath(basePat,headerTable[basePat][1]) 12 # 创造条件fp树 13 myCondTree,myHead=createTree(condPattBases,minSup) 14 # 递归找到满足阈值的项 15 # myHead==None 时,说明树只有一层叶节点,即频繁次项为一元 16 if myHead!=None: 17 print('conditional tree for:',newFreqSet) 18 myCondTree.disp(1) 19 mineTree(myCondTree,myHead,minSup,newFreqSet,freqItemList) 20 21 freqItems=[] 22 c=mineTree(myFPtree,myHeaderTab,3,set([]),freqItems) 23 print(freqItems)
3 实例:从新闻网站点击流中挖掘
1 # 1. 建立FP树的类定义 2 class treeNode: 3 def __init__(self,nameValue,numOccur,parrentNode): 4 self.name=nameValue # 存放节点名字 5 self.count=numOccur # 存放计数值 6 self.nodeLink=None # 链接相似的元素项 7 self.parent=parrentNode # 指向父节点 8 self.children={} # 存放子节点 9 10 def inc(self,numOccur): 11 self.count +=numOccur 12 13 def disp(self,ind=1): 14 print(' '*ind,self.name,' ',self.count) 15 for child in self.children.values(): 16 child.disp(ind+1) 17 18 # 2. 将输入数据列表转换为字典 19 def createInitSet(dataSet): 20 retDict = {} 21 for trans in dataSet: 22 retDict[frozenset(trans)] = 1 23 return retDict 24 25 # 3. 构建FP树 26 def createTree(dataSet, minSup=1): 27 # 使用字典作为数据结构,保存头指针 28 headerTable={} 29 # 遍历数据集,获得每个元素的出现频率 30 for trans in dataSet: 31 # print(trans) 32 for item in trans: 33 headerTable[item]=headerTable.get(item,0)+dataSet[trans] 34 # 删去出现频率少的小伙伴 35 for k in list(headerTable.keys()): 36 if headerTable[k]<minSup: 37 del(headerTable[k]) 38 freqItemSet=set(headerTable.keys()) 39 if len(freqItemSet)==0: 40 return None,None 41 for k in headerTable: 42 headerTable[k]=[headerTable[k],None] 43 reTree=treeNode('Null Set',1,None) 44 for tranSet,count in dataSet.items(): 45 localD={} 46 for item in tranSet: 47 if item in freqItemSet: 48 localD[item]=headerTable[item][0] 49 if len(localD)>0: 50 # 根据出现的频次对localD进行排序 51 orderdItems=[v[0] for v in sorted(localD.items(),key=lambda p:p[1],reverse=True)] 52 # print(orderdItems) 53 updateTree(orderdItems,reTree,headerTable,count) 54 return reTree,headerTable 55 def updateTree(items,inTree,headerTable,count): 56 # 判断是否子节点,如果是,更新计数,如果不是创建子节点 57 if items[0] in inTree.children: 58 inTree.children[items[0]].inc(count) 59 else: 60 inTree.children[items[0]]=treeNode(items[0],count,inTree) 61 if headerTable[items[0]][1]==None: 62 headerTable[items[0]][1]=inTree.children[items[0]] 63 else: 64 updateHeader(headerTable[items[0]][1],inTree.children[items[0]]) 65 # 循环创建 66 if len(items)>1: 67 updateTree(items[1::],inTree.children[items[0]],headerTable,count) 68 # 更新指针链接 69 def updateHeader(nodeToTest,targetNode): 70 while (nodeToTest.nodeLink != None): 71 nodeToTest=nodeToTest.nodeLink 72 nodeToTest.nodeLink=targetNode 73 74 # 4. 构建条件模式基 75 # 递归回溯树,从本节点一直往上 76 def ascendTree(leafNode,prefixPath): 77 if leafNode.parent != None: 78 prefixPath.append(leafNode.name) 79 ascendTree(leafNode.parent,prefixPath) 80 # 找到需查找元素的所有前缀路径 81 def findPrefixPath(basePat,treeNode): 82 condPats={} 83 while treeNode != None: 84 prefixPath=[] 85 ascendTree(treeNode,prefixPath) 86 if len(prefixPath)>1: 87 condPats[frozenset(prefixPath[1:])]=treeNode.count 88 treeNode=treeNode.nodeLink 89 return condPats 90 91 # 5.创建条件FP树,找到频繁项 92 def mineTree(inTree,headerTable,minSup,preFix,freqItemList): 93 # 此处原文有错误 94 # 从头指针的底端开始 95 bigL=[v[0] for v in sorted(headerTable.items(),key=lambda p:p[0])] 96 for basePat in bigL: 97 newFreqSet=preFix.copy() 98 newFreqSet.add(basePat) 99 freqItemList.append(newFreqSet) 100 # 创建条件基 101 condPattBases=findPrefixPath(basePat,headerTable[basePat][1]) 102 # 创造条件fp树 103 myCondTree,myHead=createTree(condPattBases,minSup) 104 # 递归找到满足阈值的项 105 # myHead==None 时,说明树只有一层叶节点,即频繁次项为一元 106 if myHead!=None: 107 print('conditional tree for:',newFreqSet) 108 myCondTree.disp(1) 109 mineTree(myCondTree,myHead,minSup,newFreqSet,freqItemList) 110 111 parseDat=[line.split() for line in open('kosarak.dat').readlines()] 112 initSet=createInitSet(parseDat) 113 myFPtree,myHeaderTab=createTree(initSet,100000) 114 myFreqlist=[] 115 mineTree(myFPtree,myHeaderTab,100000,set([]),myFreqlist) 116 print(myFreqlist)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号