机器学习实战2-决策树
1 算法基本流程
关于算法过程,周志华老师的《机器学习》写的十分详细易懂,截图如下。

三种递归返回的情况:
-
判断当前数据集是否属于同一类别,无需划分
-
判断当前数据集的特征属性是否为空,或者,当前数据集在所有属性上的的取值相同,无法划分
-
当前结点包含的样本集合为空,不能划分
2 各部分函数
2.1 计算香农熵

1 from math import log 2 3 # 计算给定数集的香农熵/Calculating Shannon Entropy of a Given Number Set 4 def calcShannonEnt(dataSet): 5 numEntries=len(dataSet) 6 labelCounts={}#创建字典/Create a dictionary 7 for featVec in dataSet: 8 currentLabel=featVec[-1]#键值是最后一列的数值/The key value is the value of the last column 9 if currentLabel not in labelCounts.keys(): 10 labelCounts[currentLabel]=0 11 labelCounts[currentLabel]+=1 12 shannonEnt=0.0 13 for key in labelCounts: 14 prob=float(labelCounts[key])/numEntries 15 shannonEnt-=prob*log(prob,2) 16 return shannonEnt
2.2 划分数据集
1 # 划分数据集/Dividing data sets 2 def splitDataSet(dataSet,axis,value):# axis表示划分依据特征,value表示特征的值 3 retDataSet=[] 4 for featVec in dataSet: 5 if featVec[axis]==value: 6 reducedFeatVec=featVec[:axis] 7 reducedFeatVec.extend(featVec[axis+1:]) 8 retDataSet.append(reducedFeatVec) 9 return retDataSet#返回的是所有包含本特征的数据集(除去本特征列向量)
2.3 选择最好数据集划分方式
信息增益:

1 # 选择最好的数据集划分方式/Choose the best way to divide your data set 2 def chooseBestFeatureToSplit(dataSet): 3 numFeatures=len(dataSet[0])-1 4 baseEntropy=calcShannonEnt(dataSet) 5 bestFeature = -1 6 bestInfoGain=0.0 7 for i in range(numFeatures): 8 featList=[example[i] for example in dataSet] 9 uniqueVals=set(featList) 10 newEntropy=0.0 11 for value in uniqueVals: 12 subDataSet=splitDataSet(dataSet,i,value) 13 prob=len(subDataSet)/float(len(dataSet))# 开始计算信息增益(ID3决策树) 14 newEntropy+=prob*calcShannonEnt(subDataSet) 15 infoGain=baseEntropy-newEntropy 16 if(infoGain>bestInfoGain): 17 bestInfoGain=infoGain 18 bestFeature=i 19 return bestFeature
3 创建决策树
1 import operator 2 # 创建一个树/creat a tree 3 def creatTree(dataSet,labels): 4 classList=[example[-1] for example in dataSet]#取列表最后一列值,即类标签 5 if classList.count(classList[0])==len(classList):#1判断是否所有类同标签 6 return classList[0] 7 if len(dataSet[0])==1:#2属性为空或使用完所有特征仍然无法将数据集划分仅包含唯一类别的分组,返回出现次数最多的组 8 return majorityCnt(classList) 9 bestFeat=chooseBestFeatureToSplit(dataSet)#选择最好的分组特征 10 bestFeatLabel=labels[bestFeat]#最好的分组特征对应的标签 11 myTree={bestFeatLabel:{}}#将标签存入myTree(一个嵌套字典) 12 del(labels[bestFeat])#删除已存入tree中的原有标签 13 featValues=[example[bestFeat] for example in dataSet] 14 uniqueVals=set(featValues)#得到最好属性列中所有的值 15 #递归执行 16 for value in uniqueVals: 17 subLabels=labels[:] 18 myTree[bestFeatLabel][value]=creatTree(splitDataSet(dataSet,bestFeat,value),subLabels) 19 return myTree
4 绘制树图
关于annotate():http://www.cnblogs.com/DaleSong/p/5348489.html
4.1 获取叶节点数目和树深度


1 # 获取叶节点数目/Get the number of leaf nodes 2 def getNumLeafs(myTree): 3 numLeafs=0 4 firstStr=list(myTree.keys())[0]#此处与《机器学习实战》不同,python3 5 secondDict=myTree[firstStr] 6 for key in secondDict.keys(): 7 #利用type函数判断子节点是否为字典型 8 if type(secondDict[key]).__name__=='dict': 9 numLeafs+=getNumLeafs(secondDict[key]) 10 else: 11 numLeafs+=1 12 return numLeafs 13 14 # 获取树的层数/Get the number of layers in the tree 15 def getTreeDepth(myTree): 16 maxDepth=0 17 firstStr=list(myTree.keys())[0] 18 secondDict=myTree[firstStr] 19 for key in secondDict.keys(): 20 #利用type函数判断子节点是否为字典型 21 if type(secondDict[key]).__name__=='dict': 22 thisDepth=1+getTreeDepth(secondDict[key]) 23 else: 24 thisDepth=1 25 if thisDepth>maxDepth: 26 maxDepth=thisDepth 27 return maxDepth
4.2 父子节点间插入文本信息
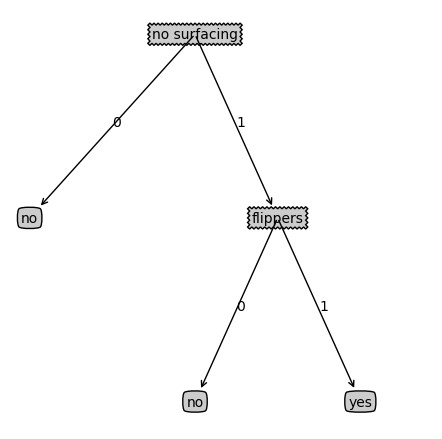
1 def plotTree(myTree,parentPt,nodeTxt): 2 numLeafs=getNumLeafs(myTree) 3 depth=getTreeDepth(myTree) 4 firstStr=list(myTree.keys())[0] 5 cntrPt=(plotTree.xoff+(1.0+float(numLeafs))/2.0/plotTree.totalW,plotTree.yoff) 6 plotMidText(cntrPt,parentPt,nodeTxt) 7 plotNode(firstStr,cntrPt,parentPt,decisionNode) 8 secondDict=myTree[firstStr] 9 plotTree.yoff = plotTree.yoff - 1.0/plotTree.totalD 10 for key in secondDict.keys(): 11 if type(secondDict[key]).__name__ == 'dict': 12 # 递归绘制树 13 plotTree(secondDict[key], cntrPt, str(key)) 14 else: 15 # 更新x的偏移量,每个叶子结点x轴方向上的距离为 1/plotTree.totalW 16 plotTree.xoff = plotTree.xoff + 1.0 / plotTree.totalW 17 # 绘制非叶子节点 18 plotNode(secondDict[key], (plotTree.xoff, plotTree.yoff), \ 19 cntrPt, leafNode) 20 # 绘制箭头上的标志 21 plotMidText((plotTree.xoff, plotTree.yoff), cntrPt, str(key)) 22 plotTree.yoff = plotTree.yoff + 1.0 / plotTree.totalD 23 24 # 绘制决策树,inTree的格式为{'no surfacing': {0: 'no', 1: {'flippers': {0: 'no', 1: 'yes'}}}} 25 def createPlot(inTree): 26 # 新建一个figure设置背景颜色为白色 27 fig = plt.figure(1, facecolor='white') 28 # 清除figure 29 fig.clf() 30 axprops = dict(xticks=[], yticks=[]) 31 # 创建一个1行1列1个figure,并把网格里面的第一个figure的Axes实例返回给ax1作为函数createPlot() 32 # 的属性,这个属性ax1相当于一个全局变量,可以给plotNode函数使用 33 createPlot.ax1 = plt.subplot(111, frameon=False, **axprops) 34 # 获取树的叶子节点 35 plotTree.totalW = float(getNumLeafs(inTree)) 36 # 获取树的深度 37 plotTree.totalD = float(getTreeDepth(inTree)) 38 # 节点的x轴的偏移量为-1/plotTree.totlaW/2,1为x轴的长度,除以2保证每一个节点的x轴之间的距离为1/plotTree.totlaW*2 39 plotTree.xoff = -0.5 / plotTree.totalW 40 plotTree.yoff = 1.0 41 plotTree(inTree, (0.5, 1.0), '') 42 plt.show()
4.3 结果
5 分类
5.1 分类函数
1 # 决策树分类函数/Decision tree classification function 2 def classify(inputTree,featLabels,testVec): 3 firstStr=list(inputTree.keys())[0] 4 secondDict=inputTree[firstStr] 5 featIndex=featLabels.index(firstStr)#index返回查找对象的索引位置,如果没有找到对象则抛出异常 6 for key in secondDict.keys(): 7 if testVec[featIndex]==key: 8 if type(secondDict[key]).__name__=='dict': 9 classLabel=classify(secondDict[key],featLabels,testVec) 10 else: 11 classLabel=secondDict[key] 12 return classLabel
5.2 决策树的存储
序列化对象可以在磁盘上保存对象,使用python模块pickle序列化对象。
1 # 决策树的存储/Decision tree storage 2 def storeTree(inputTree,filename): 3 import pickle 4 fw=open(filename,'w') 5 pickle.dump(inputTree,fw) 6 fw.close() 7 8 def grabTree(filename) 9 import pickle 10 fr=open(filename) 11 return pickle.load(fr)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号