

《不浪漫罪名》——王杰
没有花
这刹那被破坏吗
无野火都会温暖吗
无烟花一起庆祝好吗
若爱恋
仿似戏剧那样假
如布景一切都美化
连相拥都参照主角吗
你说我未能定时
令你每天欢笑一次
我没说出一句美丽台词
是你心中一种缺陷定义
流进了眼角里的刺
为何不浪漫亦是罪名
为何不轰烈是件坏事情
从来未察觉我每个动作
没有声都有爱你的铁证
为何苦不浪漫亦是罪名
为何总等待着特别事情
从来未察觉我语气动听
在我呼吸声早已说明
什么都会用一生保证
KMP学习记
时更。
关于前缀
一个在
定义:
一个长度为
后缀同理。
真前/后缀即去掉原字符串其他的前缀。
对于一个字符串,它的前缀函数
例abcabd(下标从1开始)
a与a;
ab与ab;
求解:
暴力做法,复杂度
for(int i=2;i<=len;i++)
{
for(int j=i;j>=1;j--)
{
if(s.substr(0,j)==s.substr(i-j+1,j))
{
pi[i]=j;
break;
}
}
}


例题
输出该串的所有
一切仍如昨日所见
#include <bits/stdc++.h>
const int Ratio=0;
const int N=400005;
int kmp[N],ans[N],cnt,len;
char a[N];
namespace Acheron
{
void Awork()
{
while(std::cin>>a)
{
len=strlen(a);cnt=0;
for(int i=1;i<len;i++)
{
int j=kmp[i-1];
while(j&&a[i]!=a[j])
j=kmp[j-1];
if(a[i]==a[j])
j++;
kmp[i]=j;
}
while(kmp[len-1])
ans[++cnt]=kmp[len-1],kmp[len-1]=kmp[kmp[len-1]-1];
for(int i=cnt;i>=1;i--)
printf("%d ",ans[i]);
printf("%d\n",len);
}
}
}
int main()
{
Acheron::Awork();
return Ratio;
}
上一张思路图
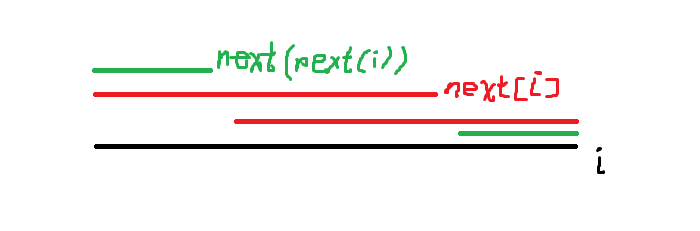
其中,
那么,我们只要在求
也就是说,当
谨慎,但也无需胆怯
#include<bits/stdc++.h>
#define fo(x,y,z) for(register int (x)=(y);(x)<=(z);(x)++)
#define fu(x,y,z) for(register int (x)=(y);(x)>=(z);(x)--)
typedef long long ll;
typedef unsigned long long ull;
namespace Aventurine
{//快读 快写 快换行、空格输出
inline ull qr()
{
char ch=getchar();ull x=0,f=1;
for(;ch<'0'||ch>'9';ch=getchar())if(ch=='-')f=-1;
for(;ch>='0'&&ch<='9';ch=getchar())x=(x<<3)+(x<<1)+(ch^48);
return x*f;
}
inline void qw(int x)
{
if(!x)
return;
qw(x/10);
putchar(x%10+'0');
}
inline void qhh(int x)
{
qw(x);
putchar('\n');
}
inline void qkg(int x)
{
if(x==0)
putchar('0');
else
qw(x);
putchar(' ');
}
}
using namespace std;
using namespace Aventurine;
#define qr qr()
const int Ratio=0;
const int N=1000005;
const int maxi=INT_MAX;
const ll mod=1e9+7;
char a[N];
int len,kmp[N],ans[N];
ll cnt;
namespace Acheron
{
void Akmpprepare()
{
int j=0;
ans[0]=0,ans[1]=1;
fo(i,2,len)
{
while(j&&a[i]!=a[j+1])
j=kmp[j];
if(a[i]==a[j+1])
j++;
kmp[i]=j;
ans[i]=ans[j]+1;
}
}
void Awork()
{
int j=0;
fo(i,2,len)
{
while(j&&a[i]!=a[j+1])
j=kmp[j];
if(a[i]==a[j+1])
j++;
while((j<<1)>i)
j=kmp[j];
cnt=(cnt*(ll)(ans[j]+1))%mod;
}
}
void Aput()
{
printf("%lld\n",cnt);
}
}
int main()
{
int T=qr;
while(T--)
{
scanf("%s",a+1);
len=strlen(a+1);
cnt=1;
Acheron::Akmpprepare();
Acheron::Awork();
Acheron::Aput();
}
return Ratio;
}
KMP
思路
KMP的精髓在于,对于每次失配之后,我们不会从头重新开始枚举,而是根据我们已知的数据,从某个特定的位置开始匹配。
而对于模式串的每一位,都有唯一的特定变化位置,这个在失配之后的特定变化位置可以帮助我们利用已有的数据不用从头匹配,从而节约时间。
具体例子可以自己手搓一个。
两个关键点:
1.我们的失配数组应当建立在模式串意义下,而不是文本串意义下。因为显然模式串要更加灵活,在失配后换位时,可以更灵活简便地处理。
2.移位法则:在模式串
代码
const int Ratio=0;
const int N=1000005;
char a[N],b[N];
int lena,lenb,kmp[N];
namespace Acheron
{
void Akmpprepare()
{//kmp-即失配回跳到哪个位置的数组-初始化
int j=0;
fo(i,2,lenb)
{
while(j&&b[i]!=b[j+1])//模式串自配 判0:回跳到头
j=kmp[j];
if(b[j+1]==b[i])
j++;
kmp[i]=j;
}
}
void Akmpwork()
{
int j=0;
fo(i,1,lena)
{
while(j>0&&b[j+1]!=a[i])//失配回跳
j=kmp[j];
if(b[j+1]==a[i])//匹配成功:对应模式串位置+1
j++;
if(j==lenb)
{
printf("%d\n",i-lenb+1);
j=kmp[j];
}
}
}
void Aput()
{
fo(i,1,lenb)
qkg(kmp[i]);
}
}
int main()
{
scanf("%s%s",a+1,b+1);
lena=strlen(a+1),lenb=strlen(b+1);
Acheron::Akmpprepare();
Acheron::Akmpwork();
Acheron::Aput();
return Ratio;
}
思路
关键点在于想出能将删去后的字符串拼接在一起而且能继续匹配的方法...
对了,用
先正常跑一遍
注意!
一个例子:danhengyinyue,danheng时,完全匹配后栈内没有元素了,这时候应将
if(s.size())
j=akmp[s.top()];
else
j=0;
因为这个被卡掉12pts的我。。。
霄龙现影,破!
const int Ratio=0;
const int N=1000005;
char a[N],b[N],ans[N];
int lena,lenb;
int kmp[N],akmp[N];
std::stack<int>s;
namespace Acheron
{
void Aprepare()
{
int j=0;
fo(i,2,lenb)
{
while(j&&b[i]!=b[j+1])
j=kmp[j];
if(b[j+1]==b[i])
j++;
kmp[i]=j;
}
}
void Awork()
{
int j=0;
fo(i,1,lena)
{
while(j&&a[i]!=b[j+1])
j=kmp[j];
if(a[i]==b[j+1])
j++;
akmp[i]=j;
s.push(i);
if(j==lenb)
{
fo(i,1,lenb)
s.pop();
if(s.size())
j=akmp[s.top()];
else
j=0;
}
}
}
void Aput()
{
int siz=s.size();
fo(i,1,siz)
ans[i]=a[s.top()],s.pop();
fu(i,siz,1)
printf("%c",ans[i]);
}
}
int main()
{
scanf("%s%s",a+1,b+1);
lena=strlen(a+1),lenb=strlen(b+1);
Acheron::Aprepare();
Acheron::Awork();
Acheron::Aput();
return Ratio;
}





【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 地球OL攻略 —— 某应届生求职总结
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 提示词工程——AI应用必不可少的技术
· .NET周刊【3月第1期 2025-03-02】