数据挖掘——流数据分析实训
中软国际《分布式计算框架》机试题
实训项目 : 数据挖掘——流数据分析实训
项目源码获取:
https://pan.baidu.com/s/1glq3tKyl3InURMrjeVCa7g 提取码:zaj5
注意事项:考试时间120分钟,满分100分。
请创建以自己姓名命名的文件夹,并创建以题号命名的子文件夹,对试题答案进行分类。
请不要在试卷上涂写与试题无关的标记。
(一) 编程题(共100分)
1.某公司2018年第一季度职员工资数据, 格式如下: (40分)
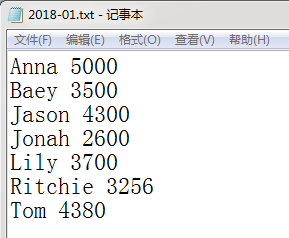
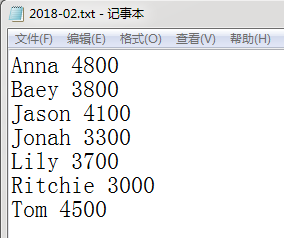

1)成功连接HDFS服务;(10分)
2)若/salaryInput目录不存在,创建这个目录;(10分)
3)成功上传职员工资数据文件到HDFS分布式文件系统中存储。(20分)
2.分析HDFS中/salaryInput目录下的职员工资数据 (60分)
1)计算第一季度每位职员的季度总工资;(10分)
2)计算第一季度每位职员的月度平均工资;(10分)
3)计算第一季度每位职员的月度最大工资;(10分)
4)计算第一季度公司所发的工资总数;(15分)
5)计算出第一季度工资最高的职员姓名。(15分)
提示:每个小题可以单独使用一个MR程序来计算,部分小题可以使用一个MR程序一起计算。
解题实现思路:
一、集群信息
主节点 IP MAC地址
cMaster 192.168.1.120 00:50:56:29:3F:6E
cSlave01 192.168.1.121 00:50:56:21:DC:BB
二、项目说明
1、package:
com.hdfs 第1题 com.salary 第2题
2、Class:
testHDFS 1) 成功连接HDFS服务;
CreateFolder 2) 若/salaryInput目录不存在,创建这个目录;
UploadFile 3) 上传职员工资数据文件到HDFS分布式文件系统中存储。
Quarterly_wage_everyone 1、计算第一季度每位职员的季度总工资
Average_monthly_everyone 2、计算第一季度每位职员的月度平均工资
Max_monthly_everyone 3、计算第一季度每位职员的月度最大工资
Quarterly_wage_total 4、计算第一季度公司所发的工资总数
Quarterly_name_maxwage 5、计算出第一季度工资最高的职员姓名
三、具体实现思路
1-1 testHDFS :
需求:连接HDFS服务
思路:要想连接HDFS,需要正确写对连接参数。通过操作HDFS上的文件,可直接证明能成功连接HDFS服务
实现: 首先以root用户,尝试性地加载hdfs API访问链接,往HDFS上新建/myfile1文件,并追加适当内容;
再读取/myfile1文件信息的块大小、文件大小和文件所属者等信息,最后删除该文件。测试HDFS服务系统的连接性。
1-2 CreateFolder:
需求:若/salaryInput目录不存在,创建这个目录。
实现思路:FileSystem实例对象有delete()和mkdirs()方法。
1-3 UploadFile :
需求:上传职员工资数据文件到HDFS分布式文件系统中存储。
思路:FileSystem实例对象有copyFromLocalFile()方法可快速实现。
实现:通过参数连接HDFS系统,先定义本地需上传文件的文件路径,再设置上传到HDFS的目标路径,最后可通过copyFromLocalFile方法进行上传。
2-1 Quarterly_wage_everyone:
需求:1)计算第一季度每位职员的季度总工资。
思路:通过切块和合并,可将三个文本中相同名字对应的数值相加,要转换类型。
实现: 内嵌Quarterly_wage_everyoneMapper和Quarterly_wage_everyoneReducer静态类Quarterly_wage_everyoneMapper内部类继承 Mapper<LongWritable,Text,Text,IntWritable>,Quarterly_wage_everyoneReducer内部类继承Reducer<Text,IntWritable,Text,IntWritable>
先在main()方法中设置传入和传出文件的路径等信息,Quarterly_wage_everyoneMapper 将输入的数据首先按行进行分割,再按每行空格划分,最后将分割的
name和scoreInt传入Quarterly_wage_everyoneReducer类。Reducer通过int sum在Iterator<IntWritable> iterator循环基础上,累加iterator.next().get()数据
最后将key和累加和进行输出。
2-2 Average_monthly_everyone:
需求:2)计算第一季度每位职员的月度平均工资。
思路:通过切块和合并,可将三个文本中相同名字对应的数值相加再除以三个月,要转换类型。
实现: 内嵌Average_monthly_everyoneMapper和Average_monthly_everyoneReducer静态类,
Average_monthly_everyoneMapper内部类继承Mapper<LongWritable,Text,Text,IntWritable>,Average_monthly_everyoneReducer内部类继承 Reducer<Text,IntWritable,Text,IntWritable>先在main()方法中设置传入和传出文件的路径等信息,Average_monthly_everyoneMapper 将输入的数据首先按行进行分割,再按每行空格划分,最后将分割的name和scoreInt传入Average_monthly_everyoneReducer类。Reducer在Iterator<IntWritable> iterator循环基础上,通过int sum累加iterator.next().get()数据,以及让int count自加,再通过sum / count方法计算平均工资。最后将key和累加和进行输出。
2-3 Max_monthly_everyone:
需求:3)计算第一季度每位职员的月度最大工资。
思路:可将三个文本中,相同名字对应的数值进行比较,保留最大值即可。
实现: 内嵌Max_monthly_everyoneMapper和Max_monthly_everyoneReducer静态类,
Max_monthly_everyoneMapper内部类继承Mapper<LongWritable,Text,Text,IntWritable>,Max_monthly_everyoneReducer内部类继承Reducer<Text,IntWritable,Text,IntWritable>先在main()方法中设置传入和传出文件的路径等信息,Max_monthly_everyoneMapper 将输入的数据首先按行进行分割,再按每行空格划分,最后将分割的name和scoreInt传入Max_monthly_everyoneReducer类。Reducer在Iterator<IntWritable> iterator循环基础上,通过int sum承接来自iterator.next().get()数据,将sum的值强制转换成int型。设置最大属性标签int max,同时在迭代循环中比较标签值和强制转换值的大小,通过比较而保留最大的数值,以达到输出最大工资值的目的。
最后将key和累加和进行输出。
2-4 Quarterly_wage_total:
需求:4)计算第一季度公司所发的工资总数。
思路:可在1)的基础上,将各个员工的季度总工资累加求和。
实现: 先在main()方法中设置传入和传出文件的路径等信息,此处为了统计的便捷性,输入的结果为Quarterly_wage_everyone输出的内容。 Quarterly_wage_totalMapper
将输入的数据首先按行进行分割,再按每行空格划分,最后将分割的name和scoreInt传入Quarterly_wage_totalReducer类。Reducer内设Iterator<IntWritable> iterator循环,
通过int sum累加来自iterator.next().get()的数据,将sum的值强制转换成int型,再将key和累加和进行输出结果为temp。至此,第一次运算完成。在main()方法中设置传入的数据
来自上一次运行结果temp,以此重复第一次执行流程。
2-5Quarterly_name_maxwage:
需求:5)计算出第一季度工资最高的职员姓名。
思路:实现的方法各种各样,首先说一下对题目的理解:以第一季度和工资最高为条件进行求职员姓名。其中,包括:
1、以第一季度个人工资和最高为参考;2、以第一季度个人月工资最高为参考。
本例实现前者,以第一季度个人工资和最高为参考。所以对1)的结果先进行排序,再选中最高者输出,运算的思路较为简便。
实现: 总而言之,就是先对数据集进行降序排列,再利用Top N的方式,将排序比重最大的元素输出。
先在main()方法中设置传入和传出文件的路径等信息,此处为了统计的便捷性,输入的结果为Quarterly_wage_everyone输出的内容。SortIntValueMapper类的map()方法将数据集分行,过滤掉尾部空符后转类型,再将分割数据传入下一层。SortIntValueReduce类的reduce()方法对数据单元进行元素自循环,通过定义的Text result变量set()一下toString()的单元素,到此可将处理的数据传出reduce层。到此第一遍运算结束,程序自动进入第二遍处理,即加载Top N过滤。第二遍的运算输入为第一次输出的内容,同时在main()中预加载相应的模块元素,如:指定job的MapperClass为KMap、job的ReducerClass为KReduce;等。显而易见,程序进入KMap层进行map运算,再进行KReduce的reduce运算,具体请详见Quarterly_name_maxwage源码。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号