关于CDH集群spark的三种安装方式简述
一、spark的命令行模式
1.第一种进入方式:执行 pyspark进入,执行exit()退出
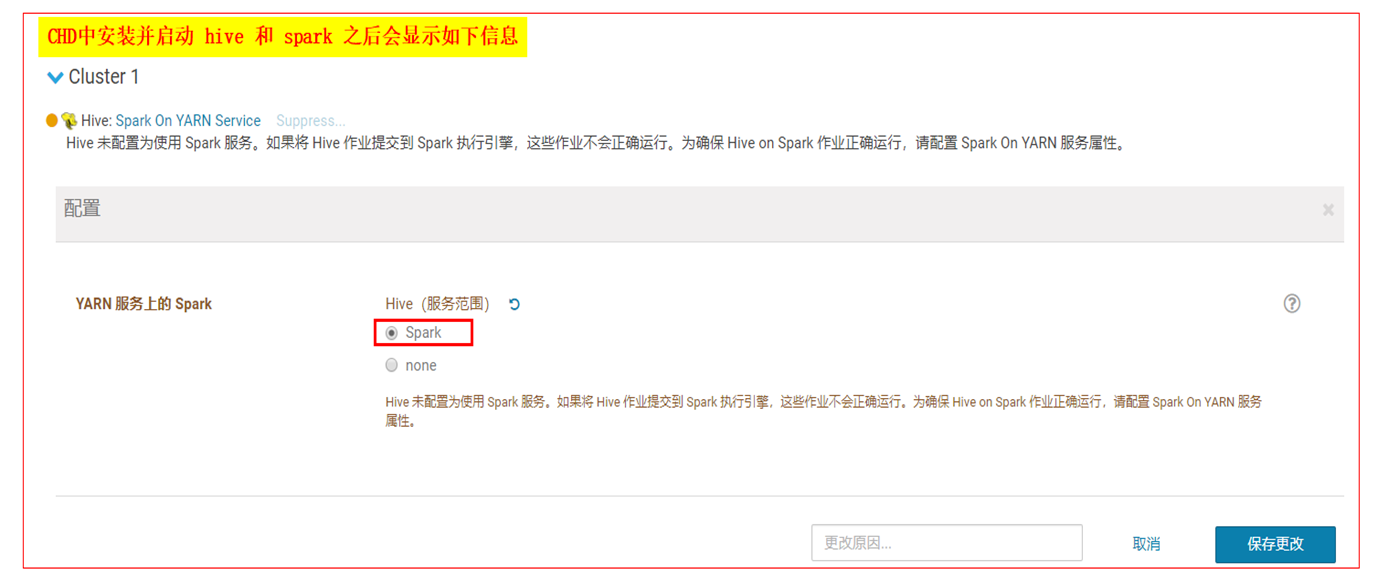
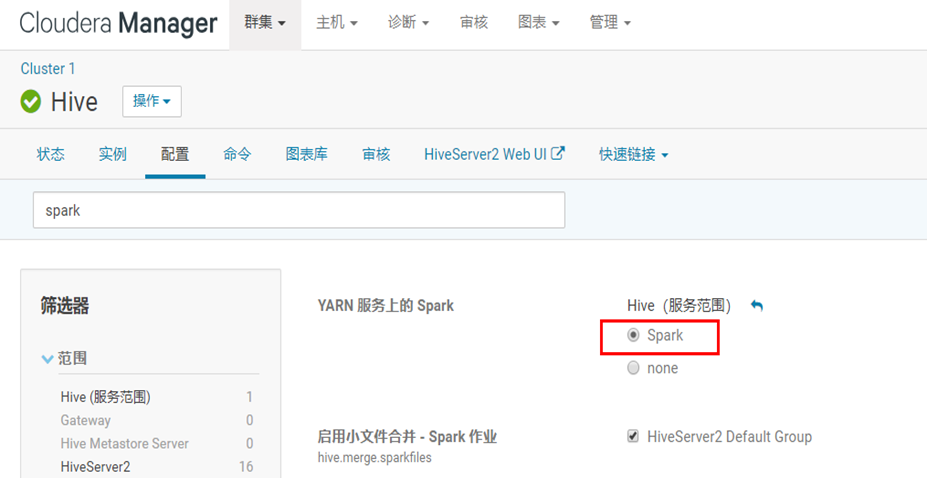
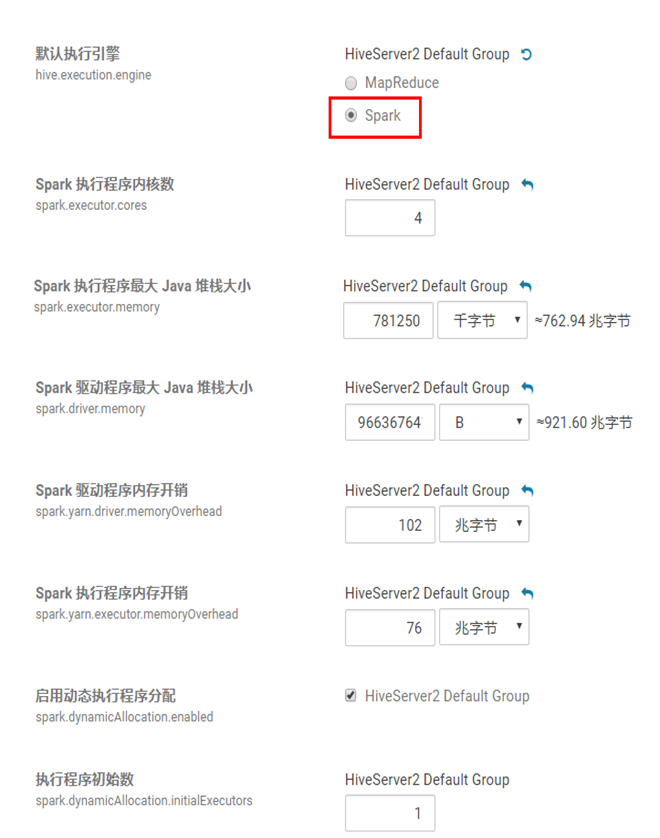
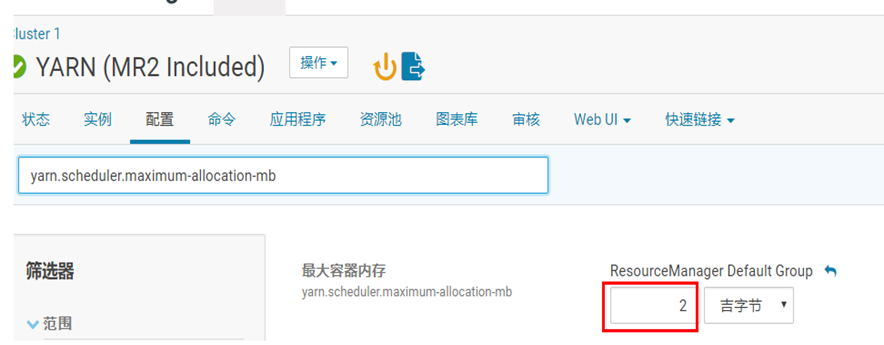
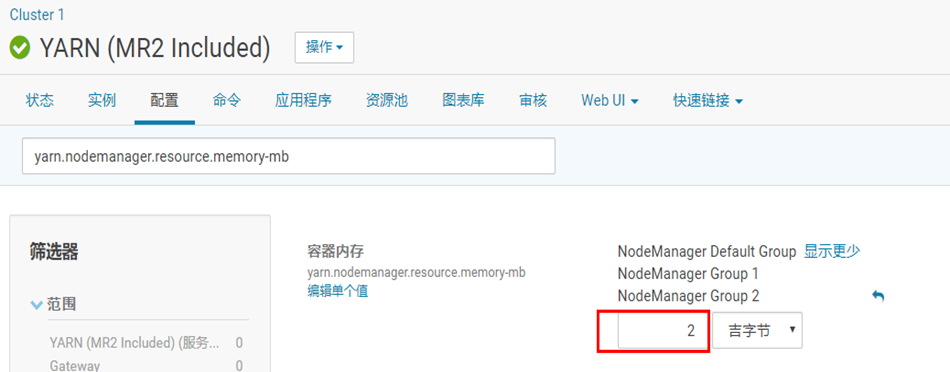
注意报错信息:java.lang.IllegalArgumentException: Required executor memory (1024+384 MB) is above the (最大阈值)max threshold (1024 MB) of this cluster!
表示 执行器的内存(1024+384 MB) 大于最大阈值(1024 MB)
Please check the values of 'yarn.scheduler.maximum-allocation-mb' and/or 'yarn.nodemanager.resource.memory-mb'

2.初始化RDD的方法
本地内存中已经有一份序列数据(比如python的list),可以通过sc.parallelize去初始化一个RDD。
当执行这个操作以后,list中的元素将被自动分块(partitioned),并且把每一块送到集群上的不同机器上。
import pyspark
from pyspark import SparkContext as sc
from pyspark import SparkConf
conf=SparkConf().setAppName("miniProject").setMaster("local[*]")
#任何Spark程序都是SparkContext开始的,SparkContext的初始化需要一个SparkConf对象,SparkConf包含了Spark集群配置的各种参数(比如主节点的URL)。
#初始化后,就可以使用SparkContext对象所包含的各种方法来创建和操作RDD和共享变量。
#Spark shell会自动初始化一个SparkContext(在Scala和Python下可以,但不支持Java)。
#getOrCreate表明可以视情况新建session或利用已有的session
sc=SparkContext.getOrCreate(conf)
# 利用list创建一个RDD;使用sc.parallelize可以把Python list,NumPy array或者Pandas Series,Pandas DataFrame转成Spark RDD。
rdd = sc.parallelize([1,2,3,4,5])
rdd 打印 ParallelCollectionRDD[0] at parallelize at PythonRDD.scala:195
# getNumPartitions() 方法查看list被分成了几部分
rdd.getNumPartitions() 打印结果:2
# glom().collect()查看分区状况
rdd.glom().collect() 打印结果: [[1, 2], [3, 4, 5]]
二、可直接执行 spark-shell,也可以执行 spark-shell --master local[2]
多线程方式:运行 spark-shell --master local[N] 读取 linux本地文件数据 。通过本地 N 个线程跑任务,只运行一个 SparkSubmit 进程,利用 spark-shell --master local[N] 读取本地数据文件实现单词计数master local[N]:采用本地单机版的来进行任务的计算,N是一个正整数,它表示本地采用N个线程来进行任务的计算,会生成一个SparkSubmit进程

 浙公网安备 33010602011771号
浙公网安备 33010602011771号