风控 code 解读 —— 德国信贷风控
code 主要来源于 德国信贷风控数据建模(步骤3:特征工程之变量分箱); p6_风控
p3 分箱
对离散变量和连续变量的操作是不一样的,
首先我们来说连续变量的分箱,连续变量分箱是的input是一个 pd.series,
-
判断是否有缺失值,如果有缺失值,抛弃缺失值。
-
初始化等距分组:
init_equal_bin==> bin_init, 包含两列 【bin_up,bin_low】 -
对初始化的分箱进行映射,
cont_var_bin_map, 最终获取的是一个包含x, y, bin_map的一个 DataFrame -
计算每个分箱下 好坏样本的个数,结果存为 temp_1,包含 【good,bad】
计算每个分箱下 样本的总数,结果存为 temp_2, 合并 temp_1,temp_2; 并和初始化分箱(bin_init)进行merge ==> temp_all -
做分箱上下限的处理; temp_all 中的【bad rate】赋值为 temp_all.index ;
-
最小样本数限制,进行分箱合并,
limit_min_sample, 输入是df_temp_all与 最小样本数 -
合并后的最大箱数与 设定进行比较,分别比较 最大箱数与最小箱数;
如果不满足,进行重新的赋值;如果满足,设置早停条件,将早停条件封装成函数。-
如果满足,分箱约束:最大分箱数限制, 在 nmax 的 for loop下,
select_split_point,这里使用了method,意味着那种方式做分组。Remark:select_split_point中使用啦好几个函数,包括best_split,cal_advantage,这两个都需要用到method -
get new lower, upper, bin, total for sub,然后合并相同的bins,
merge_bin -
存储结果,保存在 data中
-
-
如果存在缺失填补缺失。
对于离散变量,应该如何进行分箱:
-
分离缺失值、非缺失值, 转化数据类型
-
去掉缺失值后,离散变量的类型个数小于5, 不进行分箱;如果满足进行分箱,其中的早停条件设置与连续变量相同。
-
将缺失值的分箱加入上上述结果中。
离散分箱与连续变量分箱有什么不同:最终生成结果的列是不同的,初始化是不同的吗?最终分箱映射的函数是不同的,连续性变量是在某个区间内,离散变量是非缺失值映射到两个
p6_风控
-
首先对离散变量和连续变量进行分类,一种是变量类型,再根据具体的个数进行分类;得到两个集合分别储存离散变量与连续型变量,为什么这么做,因为对他们的分箱处理方法是不一样的。
-
对数据进行分箱处理,分箱所获得的结果是什么样子的?对于每行数据,每个变量属于什么分箱类型,这个可以通过字典映射编码计算对应的打分。
-
在进行WOE编码处理,所得到的结果是什么样子的?对于每行数据,每个变量都要进行WOE编码,可理解为将数据映射到另一个空间中,所得到的
df_train_woe包含很多列,有些列并不是我们想要的,我们可以用df_train_woe[var_woe_name]获取 woe编码。
最后,我们得到的训练集和测试集都是通过WOE编码得到的,其中生成结果中有dict_woe_map(每个分箱结果对应的WOE打分),可以用来计算评分卡。
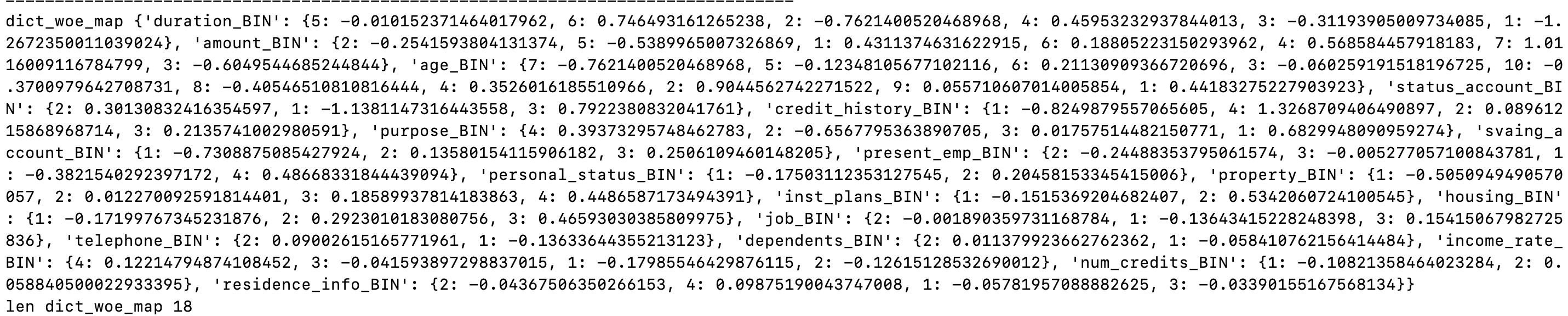
-
进行LR计算,计算评分卡,这是我们需要每行每个变量的评分,如何进行计算?我们需要获得每个变量对应的分组,每组对应的评分,然后对这个结果进行一个
map, 这时需要用到LR模型所求的参数,如何分析模型表现的好坏,通过混淆矩阵,计算TPR(召回率),FPR,AUC(通过ROC进行计算),K-S指标(TPR-FPR)。-
首先通过网格法进行调参,通过LR模型我们可以得到各个变量对应的参数,包括常数项。
-
通过上述参数,我们计算参数A、参数B,这样我们可以用来计算基准分(base point)
-


这里的左式是什么意思?详细推文可以参考【从logit变换到logistic模型】; 【下面公式来源:风控模型—WOE与IV指标的深入理解应用(知乎)】

-
通过
create_sore可以得到df_score,dict_bin_score, 具体计算如下:- 对于第k个变量(除常数项外),得到变量分箱每种类型对应的分数。其中,
df_temp.woe_val为WOE编码得到的dict_woe_map.woe_val。 具体计算就是设置一个容器,储存bins,woe_val,计算每个变量分箱对应的打分,最后按列进行concat\[params\_B \ \ * \ \ df\_temp.woe\_val \ \ * \ \ dict\_params[k] \] - 我们可以得到一个字典
dict_bin_score,对于每个变量,我们可以得到分箱结果对应的分数,这个字典的keys是每个变量,values是一个set,储存这个变量对应的分箱,以及这个分箱对应的评分值。 下面是 DataFrame 格式。

df_score, shape 为 (70,8), 70为18个变量的分箱数总和。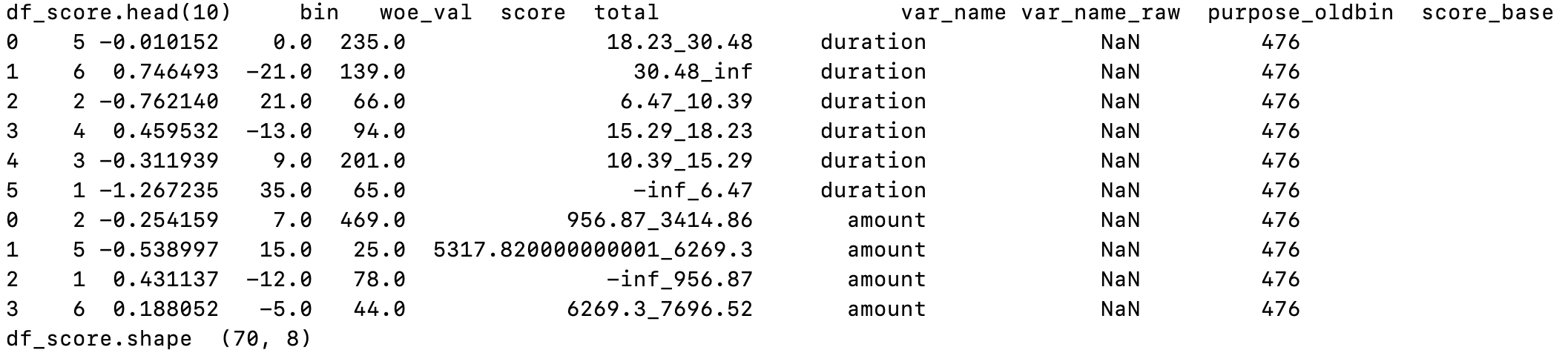
- 对于第k个变量(除常数项外),得到变量分箱每种类型对应的分数。其中,
-
怎么应用
dict_bin_score,cal_score函数对于每个变量,需要对离散变量和连续变量分别进行处理,计算变量每列元素对应的分组,通过pd.map(dict_bin_score[i])函数 对分组与得分进行映射,按列(axis=1)进行拼接。最终得到df_all_score
i = age 时的中间结果:首先得到分箱结果,然后在将分箱结果映射到得分,最后进行concat(axis=1)
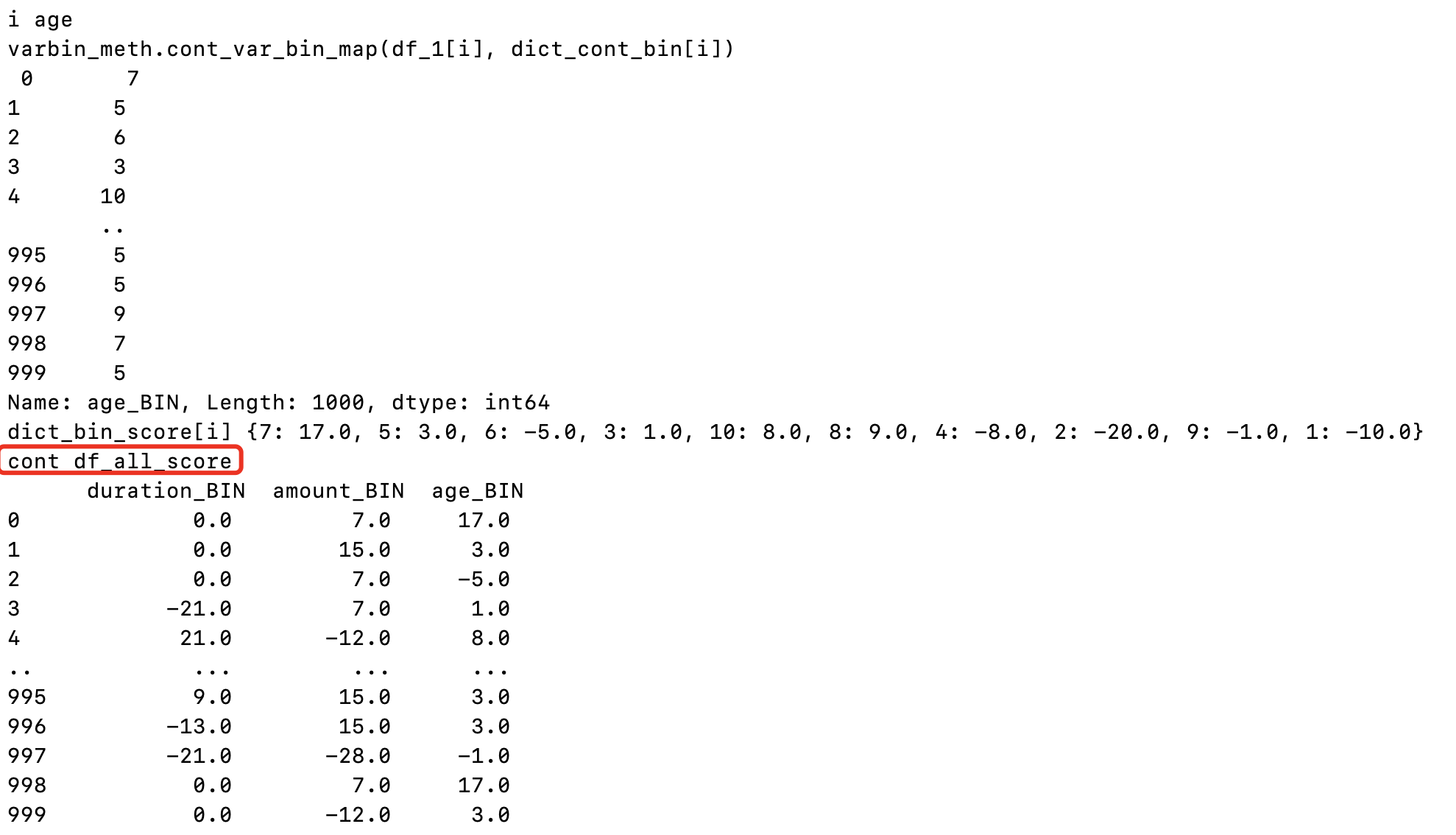
-
Remark:计算评分,如何计算训练集、测试集,以及总体的,在输入上做文章。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号