深度学习论文笔记
论文笔记
R-CNN
选区域,拉伸,计算特征,用特征训练svm分类器,分类结果计算重复度去重(nms),回归框的位置
相对以前的不同:
暴力搜索所有框变为预选框计算特征
经典方法提取的是人工设定的特征,RCNN用大的识别库训练深度网络提取特征,然后用小的检测库调优参数
缺点:
多个选取框之间很多重叠,单独计算特征会有很多重复计算,浪费时间
训练过程是多级流水线,卷积神经网络特征训练,SVM分类器训练,检测框回归训练
SPPNET
R-CNN中,多个选区框的尺寸不同,resize再提取特征既费时,效果也没有那么好
提出金字塔pooling针对不同尺寸的图,在CNN后面加上一个特殊池化层,池化为4x4,2x2,1x1的几个特征,然后拼接起来,变成21*深度的固定尺寸的特征,并且包含有空间位置信息(与图片缩放的区别是什么?图片缩放会产生图像的畸变,但是feature map的pooling只是整合了空间信息)
能反向传播?(pooling的时候记录max的location,这个location的导数为1)
多尺寸训练?
Fast R-CNN
分类和框回归化为同级,一起训练,而之前是先训练分类器,再训练框回归
全联接层,用截断SVD近似全联接层的矩阵,速度加快
Faster R-CNN
区域推荐同样用神经网络实现(原来的选择推荐算法在CPU实现,而用神经网络可以用GPU实现
参考边界框金字塔,多尺度锚点
用一个固定大小的滑动窗口,每次计算可以计算k个推荐区域,分别输出k个区域的物体概率和不是物体的概率,和k个预测区域的4个坐标

利用feature map上一个格子的信息去推断这k个anchor的前景背景的confidence和回归偏移量
平移不变特性,因为计算方式固定,不受位置影响,图像平移,相应的proposal也会平移
RPN与fast RCNN共享特征,好处是节省时间而且分类器学习到的feature会帮助proposal选择
交替训练,联合训练
FPN
对小物体检测有明显的提升
解决问题,高层特征信息丰富,但是位置模糊,底层特征信息少,但是位置准确
之前也有用高底层融合之后对特征进行预测,但是FPN每一层分别预测,并且高层会影响低层特征
改进CNN特征提取方式,高层特征反过来对底层特征进行影响
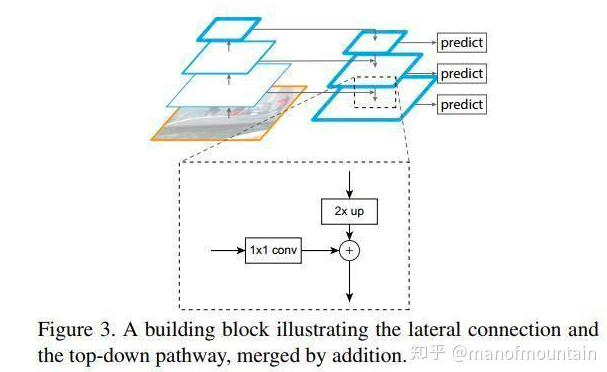
FCN
反卷积层(调整卷积参数,使得卷积之后图像变大,添加padding减小stride
转置矩阵,卷积操作可以转化为矩阵乘法,那么,如果这个矩阵进行转置,就可以把输出的大小变为输入的大小,可以完成“反”卷积的操作,通常初始化为双线性插值
跳级结构,为了预测每个像素的分类,将前面层次(位置更精确)的信息用来辅助,融合,边长为1/8放大到原图大小预测每个像素的类别

Mask R-CNN
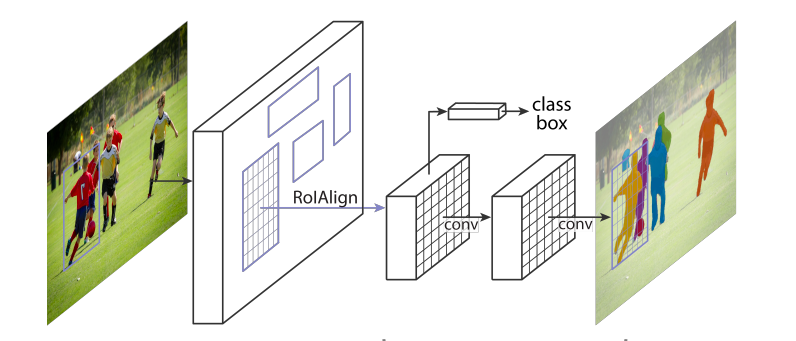
ROI pooling会有像素级别的偏移,会对分割造成影响,而差值算法ROI Align用插值算法回避了这个问题
为什么可以分出相同分类的不同个体,因为gt里面的mask只有框内主体的,网络会学习怎么只标记主体的mask
Batch Normalization
Internal Covariate Shift
学习过程中,每一层的权重都在更新,而上层更新权重之后,数据经过这一层之后的数据分布就会改变(方差,均值等),那么下一层就要适应这样的改变,导致学习速度的下降
那么就有了白化操作,每一层进行均值和方差的规范化,但是计算成本高,而且改变了网络每一层的分布
BN是对每一个特征进行规范化,而不是全层一起规范化,减小计算量,并且在规范化之后再加一个可学习的线形变换,一定程度上恢复原有数据的分布
BN的好处是不依赖输入的分布,做完规范化之后分布都是均值为0方差为1的特征,然后通过线性变换改变均值和方差
Deep Mask
目的是识别出目标单一个体的mask,用来做region proposal的
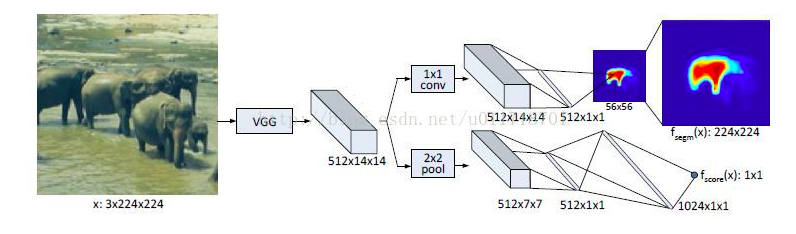
一个mask分支一个scroe分支,为了减少计算量,mask分支会计算出一个小的w0*h0的mask然后upsample成原图大小,scroe分支输出表示中心位置是否有物体
对于全图识别,用滑动窗口多次运用这个网络,给出mask和scroe,判断中心是否有物体和哪些像素属于这个物体
缺点,计算量大,不能共享特征,每个窗口都要重新计算全联接
InstanceFCN

平移不变特性对于实例分割是个不好的特性,所以引入相对位置作为变量,训练多个分类器,然后对于每个分类器只取对应分区的分数拼接起来,相当于训练多个分类器来识别一个物体的不同相对位置
局部一致性,对于一个像素而言,窗口滑动几个像素,预测结果应该相当接近,对于Deep Mask每次移动一个像素,计算的结果都不一样
IFCN相当于取了折中,一个块大小以内预测值不会变化
FCIS
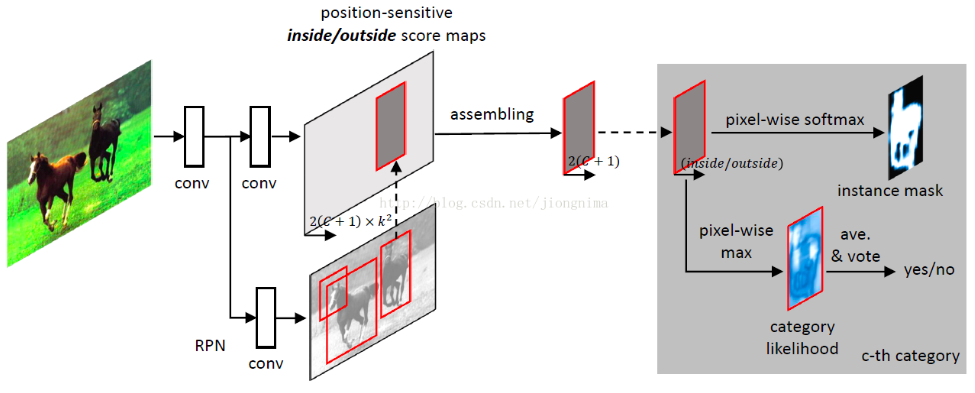
对于RPN计算出来的所有anchor计算inside/outside score,用两个scroe加起来拼成整张图片,根据图片是否接近全1来判断框是否正确
Focal Loss
在交叉殇里,gt中比重大(易区分)的种类的loss可能会冲散比重小(难区分)的种类,于是在loss中对于样本比例进行加权
具体情况是因为one-stage的方法里选取很多框去算分,而two-stage里先过一个RPN,使得背景框没有那么多所以背景框比重少

FCOS
以前基于anchor的detector,受anchor的限制太大,泛化性差,对于不同的物体不同的场景,可能要不同的anchor的ratio和scale来学习
用anchor-free的方法来预测,预测上下左右边框的位置,但是这样有一点问题,对于物体重叠的情况,不确定要回归哪一个框,而且在gt框学习回归的框会降低性能,于是引入了一个center-ness,score计算时乘上center-ness,降低偏离物体中心的预测框的分值
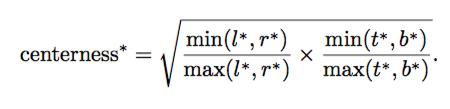
Anchor-base的方法没有这个问题大概是因为anchor就是以这个点为中心取不同大小长宽比例的anchor

FCOS可以用作one-stage的detector也可以作为two-stage的RPN来使用
Dense Box
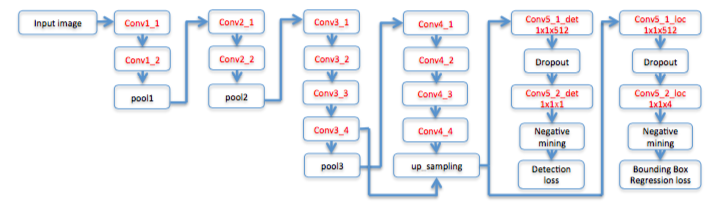
主要用于人脸检测
conv3_4和conv4_4有一次特征融合
在正样本与负样本之间有ignore,负样本点距离2以内有正样本那么这个负样本会被ignore
60x60点featuremap中取36个loss最高的负样本,36个随机负样本,72个随机正样本训练
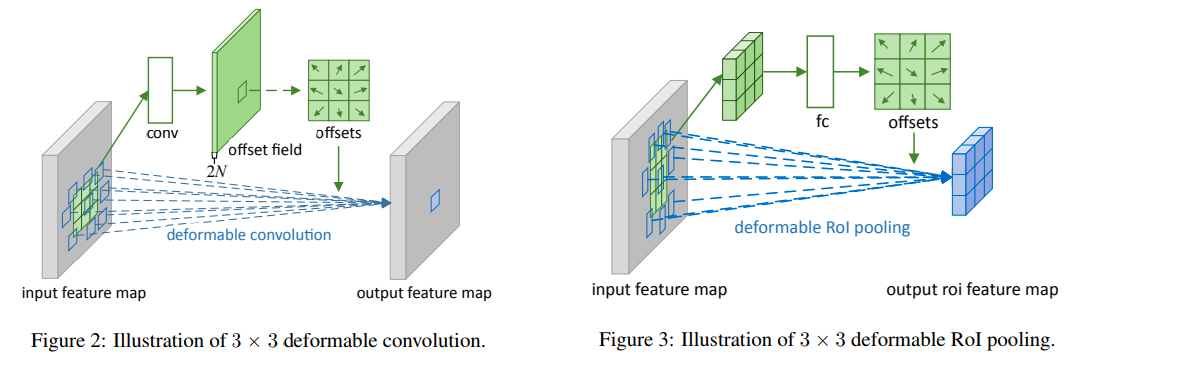
Deformable Convolutional Networks
可变形的感受野,卷积的位置加上偏移(可学习),用双线性插值算卷积

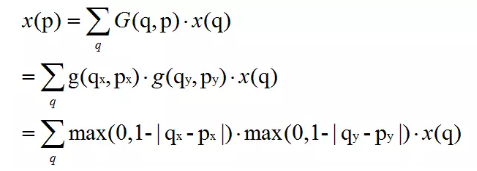
P为偏移的位置,q为所有整数坐标,因为插值的4个坐标是相邻的4个整数点,所以双线性插值的分母被约去
具体计算为先过一个卷积计算偏移量,然后再计算带偏移的卷积
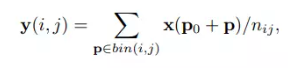
传统ROI Pooling计算每个区域的平均值
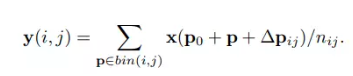
可变形的则加上偏移量再计算平均值
具体计算过程是先计算没有偏移的k*k的pooling值,然后过一个fc层计算出k*k*2的每一层的偏移,然后再计算一次偏移的pooling值
听上去很合理,根据特征来决定去下一步取什么位置的特征,可以比较好的适应物体大小的不同带来的问题,但其实还有问题,感受野的实际计算量并没有变,只是位置变了,大小物体本质差距还是存在,对物体大小的效果相当于一个有形变的resize
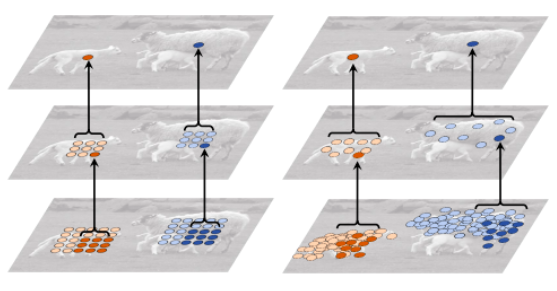
论文中提到的采样点变多了,但是实际上那些采样点是整数点的加权和,而且每一次卷积之后会有激活函数,不能简单的说采样点变多了
效果不错,涨点明显

Training Region-based Object Detectors with Online Hard Example Mining
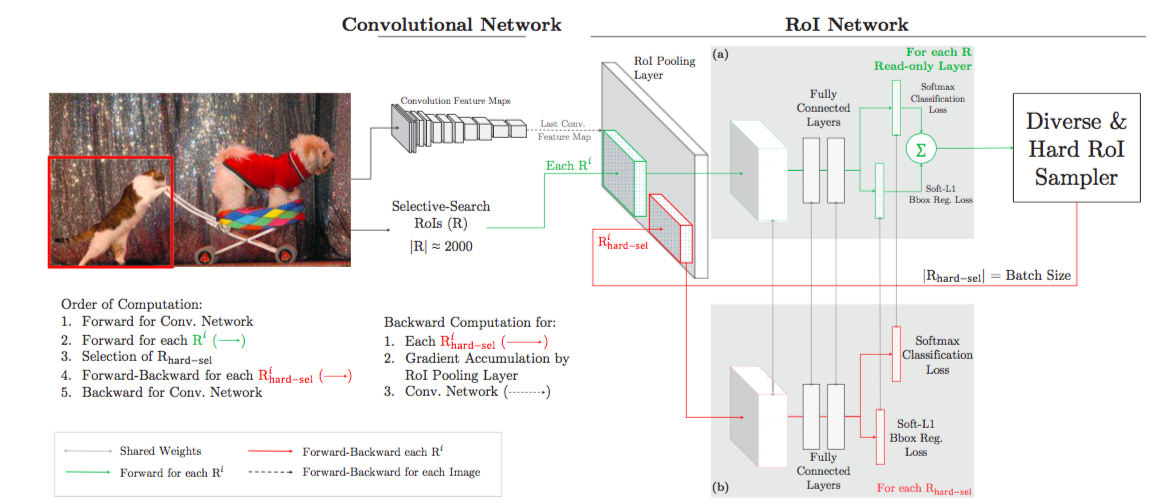
样本不均衡带来训练的困难,由于ROI过多,实际正样本较少,导致正样本和负样本比例失衡,所以先计算一遍loss,然后按照loss排序选择进行BP的样本,保证正样本与负样本比例为1:3
虽然这样训练能解决正负样本比例失衡的问题,但是忽略了小loss的贡献,易分类的虽然loss小,但是数量多,累加起来比大loss大影响大,直接舍去不太合理,focal loss降低易分类样本的loss更为合理
Beyond Skip Connections: Top-Down Modulation for Object Detection
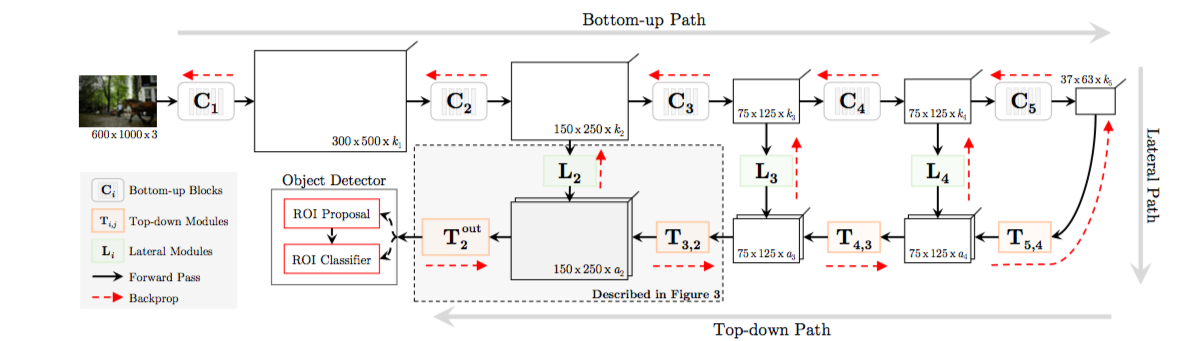
FPN同时期的工作,FPN只是简单的将通道数对齐然后大小对齐然后直接相加,但是FPN多层同时预测
而top-down中间的网络可以是复杂的网络,可以用resnet,googlenet等复杂卷积,而融合方法并不是直接相加,而是concat然后通过conv来结合,网络自己学习该怎么融合
FPN是多层一起出ROI,而top-down只用了最后一层出ROI
逐步训练
新加一个TDM训练一次,再加一个TDM再训练一次
Relation Networks for Object Detection
计算各个roi之间的relation进行加权,relation计算用了feature map和位置信息
learn to nms,计算relation代替原有的nms操作
ScratchDet: Training Single-Shot Object Detectors from Scratch
现在很多网络的训练都是基于pretrain的backbone然后再上面fine-tuned
这样存在一些问题,提取的效果虽然很好,但是并不一定适应你实际应用的场景
再者,提取特征的方式固定之后,对后面的网络是一种限制,要适应特征提取的方式
但是从头开始训练的问题是,需要的时间太长了,所以用BN来加快收敛
Soft Sampling for Robust Object Detection
标注的质量影响网络学习的表现,对于漏标注而言,可以降低离gt太远的背景的权重

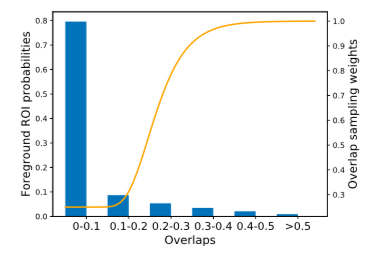
作用就是专注于gt周围的信息来训练,以改善漏标注情况的训练
个人觉得实际意义不大,通常训练的数据标注都比较完善
An Analysis of Scale Invariance in Object Detection – SNIP
介绍了一种多尺度训练的方法,将ROI都resize成一个合适的大小然后对网络进行训练,网络结构也改变,根据ROI的大小选择从不同分辨率的图片提取特征
与以前不同的是,以前的特征提取方法是一样的,最后通过ROIpooling来将统一特征大小,这样会让网络强行学习不同尺度的物体的特征提取,一定程度上降低了网络的表现
SNIPER: Efficient Multi-Scale Training
针对SNIP的改进,SNIP用多个尺度的图片来训练神经网络比较慢,而且很多大小不合理的ROI在训练中被ignore有效训练数据占比小

于是采用新的方法来选取训练数据,选一个固定大小的框(论文里是512x512),然后图片会进行放缩,用滑动窗口的方式选取chips,使得所有gt都被框入且chip较少
这样进入训练的图片数据相比之前的多个尺度来说要小很多
选取完之后直接训练的话会导致正样本太多,fp增多,所以训练了一个比较简陋的RPN网络来出框(包含fp的概率较大),然后在上面选取nagetive chips(过滤掉gt)
个人认为是利用了数据集平均框数比较少的特性,然后比较好奇评测的时候的策略

Cascade R-CNN: Delving into High Quality Object Detection
在RPN网络后面连着接好几个box regression和classifier,每一层都计算loss,每一层的iou threshold逐层增加

在更好的回归框的基础上再继续训练,以得到更好的效果
Soft-NMS – Improving Object Detection With One Line of Code
将原来的NMS操作修改一下,不是直接删除框,而是将分数缩减,一定程度上对corwd的检测有帮助,但是并不本质,有些情况涨点,有些情况掉点,因为iou并不能完全反映两个框框中的物体是否是同一个

CornerNet: Detecting Objects as Paired Keypoints

 浙公网安备 33010602011771号
浙公网安备 33010602011771号