[Python]基于CNN的MNIST手写数字识别
目录
一、背景介绍
1.1 卷积神经网络
1.2 深度学习框架
1.3 MNIST 数据集
二、方法和原理
2.1 部署网络模型
(1)权重初始化
(2)卷积和池化
(3)搭建卷积层1
(4)搭建卷积层2
(5)搭建全连接层3
(6)搭建输出层
2.2 训练和评估模型
三、结果
3.1 训练过程
3.2 测试过程
四、讨论与结论
一、背景介绍
1.1 卷积神经网络
近年来,深度学习的概念非常火热。深度学习的概念最早由Hinton等人在2006年提出。基于深度置信网络(DBN),提出非监督贪心逐层训练算法,为解决深层结构相关的优化难题带来希望,随后提出多层自动编码器深层结构。此外Lecun等人提出的卷积神经网络(Convolutional Neural Networks / CNNs / ConvNets)是第一个真正多层结构学习算法,它利用空间相对关系减少参数数目以提高训练性能。Alex在2012年提出的AlexNet网络结构模型引爆了神经网络的应用热潮,并赢得了2012届图像识别大赛的冠军,使得CNN成为在图像分类上的核心算法模型。
1.2 深度学习框架
随着深度学习研究的热潮持续高涨,各种开源深度学习框架也层出不穷,其中包括TensorFlow、Caffe2、Keras、CNTK、Pytorch、MXNet、Leaf、Theano、DeepLearning4等等。Google、Microsoft、Facebook等巨头都参与了这场深度学习框架大战。目前,由谷歌推出的TensorFlow和Facebook推出的Pytorch、Caffe2较受欢迎。下面将简单介绍这三种框架的特点。
Caffe全称为Convolutional Architecture for Fast Feature Embedding,是一个被广泛使用的开源深度学习框架(在TensorFlow出现之前一直是深度学习领域GitHub star最多的项目)。Caffe的主要优势包括如下几点:
-
容易上手,网络结构都是以配置文件形式定义,不需要用代码设计网络。
-
训练速度快,能够训练state-of-the-art的模型与大规模的数据。
-
组件模块化,可以方便地拓展到新的模型和学习任务上。
Caffe的核心概念是Layer,每一个神经网络的模块都是一个Layer。Layer接收输入数据,同时经过内部计算产生输出数据。设计网络结构时,只需要把各个Layer拼接在一起构成完整的网络。Caffe2是caffe的升级版,在各方面均有一定提升。
2017 年初,Facebook 在机器学习和科学计算工具 Torch 的基础上,针对 Python 语言发布了一个全新的机器学习工具包 PyTorch。一经发布,这款开源工具包就受到了业界的广泛关注和讨论,经过几个月的发展,目前 PyTorch 已经成为从业者最重要的研发工具之一。其最大的特点是支持动态图的创建。其他主流框架都是采用静态图创建,静态图定义的缺陷是在处理数据前必须定义好完整的一套模型,能够处理所有的边际情况。比如在声明模型前必须知道整个数据中句子的最大长度。相反动态图模型能够非常自由的定义模型。同时,PyTorch继承了Torch,支持Python,支持更加便捷的Debug,所以非常受欢迎。
TensorFlow是相对高阶的机器学习库,用户可以方便地用它设计神经网络结构,而不必为了追求高效率的实现亲自写C++或CUDA代码。它和Theano一样都支持自动求导,用户不需要再通过反向传播求解梯度。其核心代码和Caffe一样是用C++编写的,使用C++简化了线上部署的复杂度,并让手机这种内存和CPU资源都紧张的设备可以运行复杂模型(Python则会比较消耗资源,并且执行效率不高)。除了核心代码的C++接口,TensorFlow还有官方的Python、Go和Java接口,是通过SWIG(Simplified Wrapper and Interface Generator)实现的,这样用户就可以在一个硬件配置较好的机器中用Python进行实验,并在资源比较紧张的嵌入式环境或需要低延迟的环境中用C++部署模型。
TensorFlow的另外一个重要特点是它灵活的移植性,可以将同一份代码几乎不经过修改就轻松地部署到有任意数量CPU或GPU的PC、服务器或者移动设备上。用户能够将训练好的模型方便地部署到多种硬件、操作系统平台上,支持Intel和AMD的CPU,通过CUDA支持NVIDIA的GPU,支持Linux和Mac、Windows,也能够基于ARM架构编译和优化,在移动设备(Android和iOS)上表现得很好。TensorFlow还有功能强大的可视化组件TensorBoard,能可视化网络结构和训练过程,对于观察复杂的网络结构和监控长时间、大规模的训练很有帮助。TensorFlow针对生产环境高度优化,它产品级的高质量代码和设计都可以保证在生产环境中稳定运行,同时TensorFlow广泛地被工业界使用,产生了良性循环,成为了深度学习领域的事实标准。
1.3 MNIST 数据集
除了神经网络理论体系的发展和深度学习框架的推进,数据集的完善同样促进了人工智能领域的发展。MNIST(Mixed National Institute of Standards and Technology database)是一个计算机视觉数据集,它包含70000张手写数字的灰度图片,其中每一张图片包含 28 X 28 个像素点。可以用一个数字数组来表示这张图片。如图1所示。
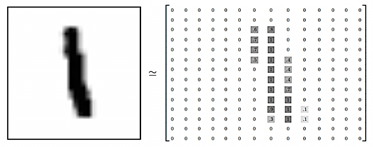
图1 MNIST数据格式
每一张图片都有对应的标签,也就是图片对应的数字,例如上面这张图片的标签就是 1。数据集被分成两部分:60000 行的训练数据集(mnist.train)和10000行的测试数据集(mnist.test)。
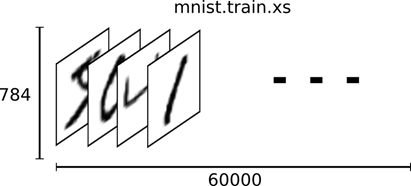
其中:60000 行的训练集分拆为 55000 行的训练集和 5000 行的验证集。60000行的训练数据集是一个形状为 [60000, 784] 的张量,第一个维度数字用来索引图片,第二个维度数字用来索引每张图片中的像素点。在此张量里的每一个元素,都表示某张图片里的某个像素的强度值,值介于 0 和 1 之间。
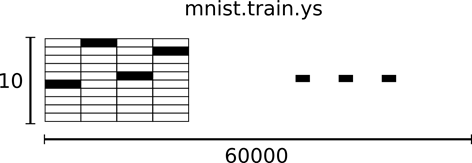
60000 行的训练数据集标签是介于 0 到 9 的数字,用来描述给定图片里表示的数字。称为 "one-hot vectors"。一个 one-hot 向量除了某一位的数字是 1 以外其余各维度数字都是 0。所以在此教程中,数字 n 将表示成一个只有在第 n 维度(从 0 开始)数字为 1 的 10 维向量。比如,标签 0 将表示成 ( [1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0 ] )。因此,其标签是一个 [60000, 10] 的数字矩阵。如图2(a)、(b)所示。
(a)
(b)
图2 MNIST训练集格式
下面将借助于TensorFlow框架,在Mnist数据集的基础上,通过卷积神经网络,进行手写数字识别的仿真测试。
二、方法和原理
2.1 部署网络模型
本次仿真采取一个四层的网络,来实现手写数字0~9的识别。网络结构如下:
|
Convolutional Layer1 + Max Pooling |
|
Convolutional Layer2 + Max Pooling |
|
Fully Connected Layer1 + Dropout |
|
Fully Connected Layer2 To Prediction |
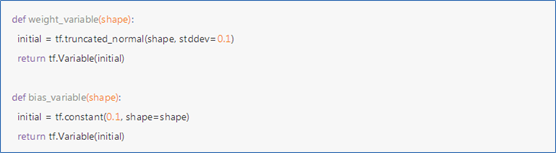
(1)权重初始化
为了创建这个模型,我们需要创建大量的权重和偏置项。这个模型中的权重在初始化时应该加入少量的噪声来打破对称性以及避免0梯度。由于我们使用的是ReLU神经元,因此比较好的做法是用一个较小的正数来初始化偏置项,以避免神经元节点输出恒为0的问题(dead neurons)。为了不在建立模型的时候反复做初始化操作,我们定义两个函数用于初始化。
(2)卷积和池化
TensorFlow在卷积和池化上有很强的灵活性。卷积使用1步长(stride size),0边距(padding size)的模板,保证输出和输入是同一个大小。池化用简单传统的2x2大小的模板做max pooling。为了代码更简洁,把这部分抽象成一个函数。
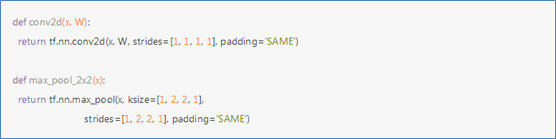
(3)搭建卷积层1
第一层由一个卷积接一个max pooling完成。卷积在每个5x5的patch中算出32个特征。卷积的权重张量形状是[5, 5, 1, 32],前两个维度是patch的大小,接着是输入的通道数目,最后是输出的通道数目。而对于每一个输出通道都有一个对应的偏置量。

接下来将卷积核与输入的x_image进行卷积,并通过relu激活函数,再最大池化处理。

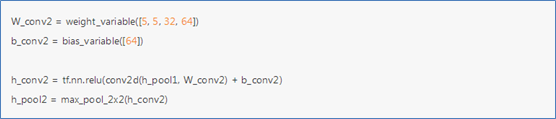
(4)搭建卷积层2
第二层构建一个更深的网络,每个5x5的patch会得到64个特征。卷积核大小5x5x32,数量为64个,构造过程类似上一层。
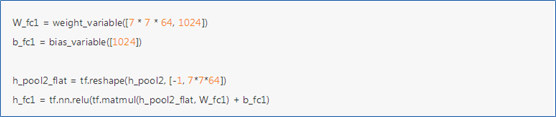
(5)搭建全连接层3
原始图片尺寸是28x28,经过两次的2x2的池化后,长宽尺寸降低到7x7。现在加入一个有1024个神经元的全连接层,将上一层输出的结果Vector化,变成一个向量,将其与权重W_fc1相乘,加上偏置b_fc1,对其使用ReLU。
为了减少过拟合,我们在输出层之前加入dropout。我们用一个placeholder来代表一个神经元的输出在dropout中保持不变的概率。这样我们可以在训练过程中启用dropout,在测试过程中关闭dropout。 TensorFlow的tf.nn.dropout操作除了可以屏蔽神经元的输出外,还会自动处理神经元输出值的scale。所以用dropout的时候可以不用考虑scale。

(6)搭建输出层
最后一层使用全连接层,并通过softmax回归来输出预测结果。softmax模型可以用来给不同的对象分配概率。可以用下面的图解释,对于输入的x_i加权求和,再分别加上一个偏置量,最后再输入到softmax函数中。
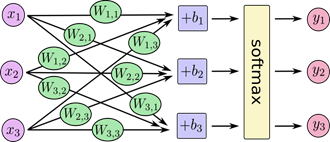
其计算公式为
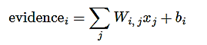

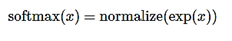
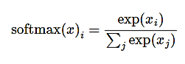

2.2 训练和评估模型
为了训练我们的模型,我们首先需要定义损失函数(loss function),然后尽量最小化这个指标。这里使用的损失函数是"交叉熵"(cross-entropy)。交叉熵产生于信息论里面的信息压缩编码技术,但是它后来演变成为从博弈论到机器学习等其他领域里的重要技术手段。它的定义如下:

计算交叉熵后,就可以使用梯度下降来优化参数。由于前面已经部署好网络结构,所以TensorFlow可以使用反向传播算法计算梯度,自动地优化参数,直到交叉熵最小。TensorFlow提供了多种优化器,这里选择更加复杂的Adam优化器来做梯度最速下降,学习率0.0001。每次训练随机选择50个样本,加快训练速度,每轮训练结束后,计算预测准确度。
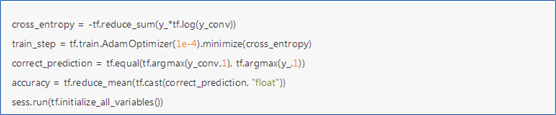
三、结果
3.1 训练过程
在CNN网络训练过程中,通过Tensorflow中的可视化工具Tensorboard,可以跟踪网络的整个训练过程中的信息,比如每次循环过程中的参数变化、损失变化等。
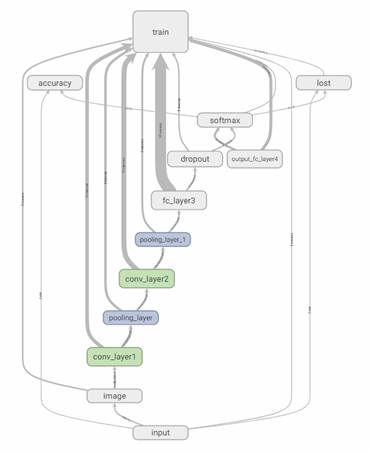
图4 主计算图模型
Tensorboard可以记录与展示以下数据形式:
-
标量Scalars
-
图片Images
-
音频Audio
-
计算图Graph
-
数据分布Distribution
-
直方图Histograms
-
嵌入向量Embeddings
在本次实验的训练过程中,我们将在相关代码处放置节点,统计训练过程中的损失和准确率,同时观察部分训练样本,Tensorboard会把模型训练过程中的各种数据汇总起来,存在自定义的路径与日志文件中,然后在指定的web端可视化地展现这些信息。

图5 训练过程中的精确度
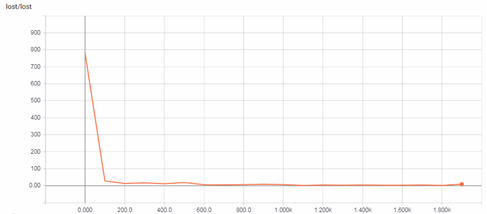
图6 训练过程中的损失
如图4所示,是整个网络的计算图模型。清晰地展示了四层网络之间的关系。
如图5所示,是训练过程中的精确度,随着训练步数的增加,精确度逐渐提升。在迭代将近2000次时,训练准确度稳定在百分之95以上。
如图6所示,是训练过程中的损失,损失是通过交叉熵来衡量。随着训练步数的增加,损失逐渐降低。
结合图5和图6,可以观察到,在训练至100次时,损失达到一个比较小的水平,精确度提高到一个比较高的水平。
3.2 测试过程
训练过程结束后,将验证测试集的预测精确度,结果通过控制台打印输出。

可以观察到,最终的预测准确度是97.45%,总迭代次数2000次,是一个比较理想的结果。根据经验,训练次数超过20000次后,精度将维持在99%以上。
四、讨论与结论
通过2层的CNN网络加上2层的全连接层,能够达到一个不错的预测效果。本次仿真中,使用的激活函数是Relu函数,一定程度上避免了梯度消失和梯度饱和的问题。同时在全连接层加入了dropout,以一定概率舍弃网络中的神经元,这样可以避免一定的偶然性,最后训练得到的网络将会更加健壮,泛化性能更强。
源代码:


1 import tensorflow as tf 2 import input_data # download and extract the data set automatically 3 4 5 def weight_variable(shape): 6 initial = tf.truncated_normal(shape, stddev=0.1) 7 return tf.Variable(initial) 8 9 10 def bias_variable(shape): 11 initial = tf.constant(0.1, shape=shape) 12 return tf.Variable(initial) 13 14 15 def conv2d(x, W): 16 return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME') 17 18 19 def max_pool_2x2(x): 20 return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') 21 22 23 # get the data source 24 mnist = input_data.read_data_sets("MNIST_data/", one_hot=True) 25 26 # input image:pixel 28*28 = 784 27 with tf.name_scope('input'): 28 x = tf.placeholder(tf.float32, [None, 784]) 29 y_ = tf.placeholder('float', [None, 10]) # y_ is realistic result 30 31 with tf.name_scope('image'): 32 x_image = tf.reshape(x, [-1, 28, 28, 1]) # any dim, width, height, channel(depth) 33 tf.summary.image('input_image', x_image, 8) 34 35 # the first convolution layer 36 with tf.name_scope('conv_layer1'): 37 W_conv1 = weight_variable([5, 5, 1, 32]) # convolution kernel: 5*5*1, number of kernel: 32 38 b_conv1 = bias_variable([32]) 39 40 h_conv1 = tf.nn.relu(conv2d(x_image, W_conv1) + b_conv1) # make convolution, output: 28*28*32 41 42 with tf.name_scope('pooling_layer'): 43 h_pool1 = max_pool_2x2(h_conv1) # make pooling, output: 14*14*32 44 45 # the second convolution layer 46 with tf.name_scope('conv_layer2'): 47 W_conv2 = weight_variable([5, 5, 32, 64]) # convolution kernel: 5*5, depth: 32, number of kernel: 64 48 b_conv2 = bias_variable([64]) 49 h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2) # output: 14*14*64 50 51 with tf.name_scope('pooling_layer'): 52 h_pool2 = max_pool_2x2(h_conv2) # output: 7*7*64 53 54 55 # the first fully connected layer 56 with tf.name_scope('fc_layer3'): 57 W_fc1 = weight_variable([7 * 7 * 64, 1024]) 58 b_fc1 = bias_variable([1024]) # size: 1*1024 59 h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64]) 60 h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1) # output: 1*1024 61 62 # dropout 63 with tf.name_scope('dropout'): 64 keep_prob = tf.placeholder(tf.float32) 65 h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob) 66 67 68 # the second fully connected layer 69 # train the model: y = softmax(x * w + b) 70 with tf.name_scope('output_fc_layer4'): 71 W_fc2 = weight_variable([1024, 10]) 72 b_fc2 = bias_variable([10]) # size: 1*10 73 74 with tf.name_scope('softmax'): 75 y_conv = tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2) # output: 1*10 76 77 with tf.name_scope('lost'): 78 cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv)) 79 tf.summary.scalar('lost', cross_entropy) 80 81 with tf.name_scope('train'): 82 train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy) 83 84 with tf.name_scope('accuracy'): 85 correct_prediction = tf.equal(tf.argmax(y_conv, 1), tf.argmax(y_, 1)) 86 accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float")) 87 tf.summary.scalar('accuracy', accuracy) 88 89 merged = tf.summary.merge_all() 90 train_summary = tf.summary.FileWriter(r'C:\Users\Administrator\tf\log', tf.get_default_graph()) 91 92 # init all variables 93 init = tf.global_variables_initializer() 94 95 # run session 96 with tf.Session() as sess: 97 sess.run(init) 98 # train data: get w and b 99 for i in range(2000): # train 2000 times 100 batch = mnist.train.next_batch(50) 101 102 result, _ = sess.run([merged, train_step], feed_dict={x: batch[0], y_: batch[1], keep_prob: 1.0}) 103 # train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5}) 104 105 if i % 100 == 0: 106 # train_accuracy = sess.run(accuracy, feed_dict) 107 train_accuracy = accuracy.eval(feed_dict={x: batch[0], y_: batch[1], keep_prob: 1.0}) # no dropout 108 print('step %d, training accuracy %g' % (i, train_accuracy)) 109 110 # result = sess.run(merged, feed_dict={x: batch[0], y_: batch[1]}) 111 train_summary.add_summary(result, i) 112 113 train_summary.close() 114 115 print('test accuracy %g' % accuracy.eval(feed_dict={x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0})) 116 117 118 # open tensor_board in windows-cmd 119 # tensorboard --logdir=C:\Users\Administrator\tf

 浙公网安备 33010602011771号
浙公网安备 33010602011771号