
团队介绍的词频统计
团队介绍的词频统计
团队介绍
设计、实现一个可以进行学习研究、分享交流的人性化学习网站,为学习者提供资源共享、学术讨论、疑题问答、交友聊天的平台。为了能让学习网站更加人性化、更贴合实际需求,我们在继承传统学习网站学术讨论、资源共享功能的同时,增加了好友聊天、问问、智能语音输入、智能推荐内容等新特性。
代码
import jieba
import collections
import numpy as np
import matplotlib.pyplot as plt
s = "设计、实现一个可以进行学习研究、分享交流的人性化学习网站,为学习者提供资源共享、学术讨论、疑题问答、交友聊天的平台。为了能让学习网站更加人性化、更贴合实际需求,我们在继承传统学习网站学术讨论、资源共享功能的同时,增加了好友聊天、问问、智能语音输入、智能推荐内容等新特性。"
s1 = seg_list = jieba.cut(s, cut_all=False, HMM=True)
l = list()
for c in s1: # 将分词结果放进list里
if c not in ('、',',','。','的','一个','可以','为','进行','提供'): # 删除符号、无实际意义的词
l.append(c)
count = collections.Counter(l)# 词频统计
key = list()
val = list()
for a,b in count.most_common(8): #查看前8个高频词
key.append(a)
val.append(b)
print(a,b)
plt.axes(aspect=1) # set this , Figure is round, otherwise it is an ellipse
plt.pie(x=val, labels=key, explode=None,autopct='%3.1f %%',
shadow=True, labeldistance=1.1, startangle = 90,pctdistance = 0.6
)#画饼图
plt.show()
词频统计结果
学习 4
网站 3
人性化 2
资源共享 2
学术讨论 2
聊天 2
智能 2
设计 1
(取最出现频率高的8个词)
词频分布图
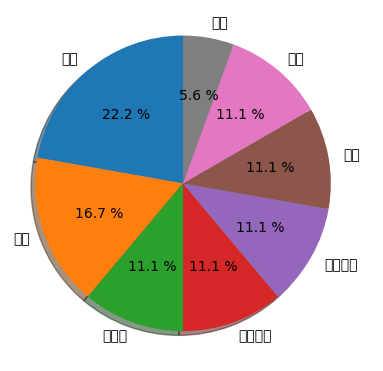
(matplotlib库的中文字体乱码,还没找到有用解决方法)

