
内联函数、引用、汇编
内联函数
内联函数是一种特殊的 C++ 函数,编译器会将它的代码直接插入到调用它的位置,而不是像普通函数那样进行函数调用。这可以减少函数调用的开销,从而提高性能。
#include <iostream>
using namespace std;
int func(int v1, int v2) {
return v1 + v2;
}
inline int func1(int v1, int v2) {
return v1 + v2;
}
int main() {
func(1, 2);
func1(3, 4);
return 0;
}
内联函数的优点
- 提高性能:内联函数可以减少函数调用的开销,从而提高性能。
- 减少代码大小:内联函数可以减少代码大小,因为编译器不会生成额外的函数调用指令。
- 提高可读性:内联函数可以提高可读性,因为函数代码直接出现在调用它的位置。
使用场景
- 函数体积小
- 函数需要经常使用
引用
引用是 C++ 中一种强大的机制,它允许你以一种高效且类型安全的方式间接访问变量。引用与指针类似,但它们有以下几个关键区别:
- 引用必须初始化:引用必须在声明时或之后立即初始化。
- 引用不能重新绑定:一旦引用被初始化,它就不能再指向其他变量。
- 引用与它所引用的变量共享存储空间:对引用的修改也会修改它所引用的变量。
- 引用比指针更安全,
引用是一种“弱化的指针”,相当于给变量起别名。
举例说明引用的使用
#include <iostream>
using namespace std;
//指针
void swap_point(int* a, int* b) {
int tmp = *a;
*a = *b;
*b = tmp;
}
//引用,相当与给变量取别名!
void swap_ref(int& a, int& b) {
int tmp = a;
a = b;
b = tmp;
}
int main() {
int s1 = 1, s2 = 2;
int s3 = 3, s4 = 4;
swap_point(&s1, &s2);
cout << "s1 = " << s1 << ",s2 = " << s2 << endl;
swap_ref(s3, s4);
cout << "s3 = " << s3 << ",s4 = " << s4 << endl;
getchar();
return 0;
}
汇编分析
main函数

指针传值

引用传值

从以上可以看出,引用和指针本质一样,只是前者加了一些限制与简化,例如与const结合可以达到保护内存空间的效果,可以方便的直接操作某些变量的内存,而不需要通过取地址给指针、指针解引用等操作。
所有栈中的数据要进行计算,必须放到CPU的寄存器中,同样,函数的返回值也是存放在寄存器中的。
32位下指针变量占4字节,64位下指针变量占8字节。为了进一步证明它们本质一样,下面进行大小验证。
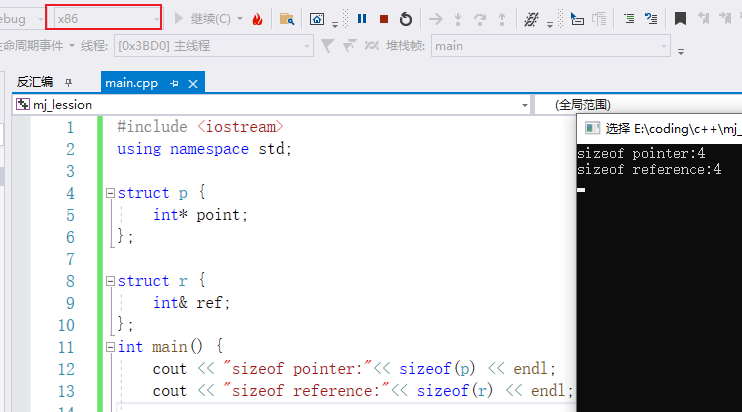
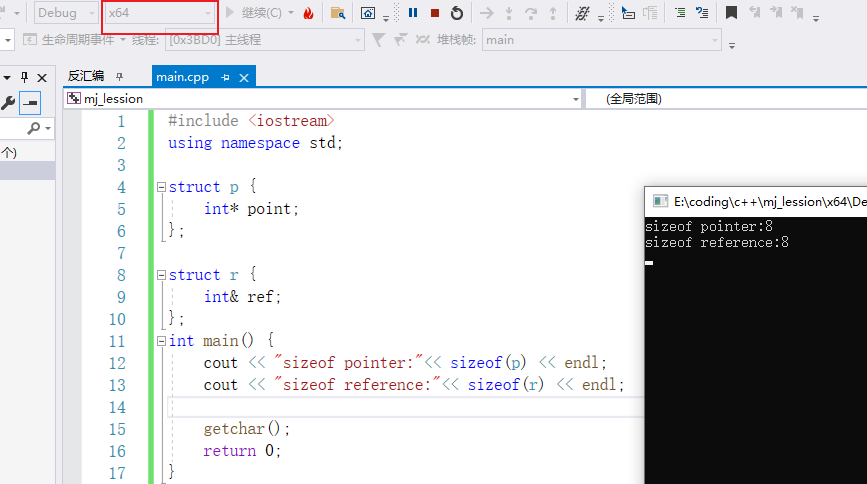
为什么要把引用变量放到结构体里面计算大小?
如果这样写,绝对是错误的。

前面说过,ref可以看作是变量的别名,那么输出语句可以这样理解,把a的大小,一个int输出了,明显得不到引用变量的大小。
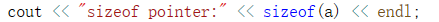
为了进一步说明引用的本质就是指针,再看一个例子
int a = 10;
int& ref = a;
ref = 20;
----
C7 45 F4 0A 00 00 00 mov dword ptr [a],0Ah ;int a = 10;
8D 45 F4 lea eax,[a] ;int& ref = a;
89 45 E8 mov dword ptr [ref],eax
8B 45 E8 mov eax,dword ptr [ref] ;ref = 20;
C7 00 14 00 00 00 mov dword ptr [eax],14h
--------------------------------------------------
int b = 10;
int* p = &b;
*p = 20;
---
C7 45 DC 0A 00 00 00 mov dword ptr [b],0Ah ;int b = 10;
8D 45 DC lea eax,[b] ;int* p = &b;
89 45 D0 mov dword ptr [p],eax
8B 45 D0 mov eax,dword ptr [p] ;*p = 20;
C7 00 14 00 00 00 mov dword ptr [eax],14h
因为CPU架构的原因,每次需要操作内存空间时,需要提前将内存地址放到寄存器中。
汇编
两种格式
Intel 格式和 AT&T 格式是两种不同的汇编语言语法,用于 x86 架构的处理器。
Intel 格式由英特尔公司开发,是 x86 汇编语言最常见的语法。它使用以下约定:
- 指令助记符写在操作数之前。
- 寄存器使用单字母缩写(例如,
eax、ebx)。 - 内存地址使用方括号(例如,
[eax])。
AT&T 格式由贝尔实验室开发,主要用于 Unix 和类 Unix 系统。它使用以下约定:
- 指令助记符写在操作数之后。
- 寄存器使用百分号符号(例如,
%eax、%ebx)。 - 内存地址使用圆括号(例如,
(%eax))。
以下是用 Intel 格式和 AT&T 格式编写的相同汇编代码:
Intel 格式:
mov eax, 10
add eax, 5
AT&T 格式:
movl $10, %eax
addl $5, %eax
QuickStart
- CPU做计算时,必须先将值读入寄存器,然后再从寄存器中读取,不能直接操作内存
- RAX、RBX、RCX、RDX 是 64位下的通用寄存器,大小与指针大小一样,64位下占8字节
[]里存放的都是地址- word 占2 字节, dword 占4 字节, qword 占8 字节
- 函数调用:call 函数地址 ——> jmp 真实函数地址 。
这是因为在汇编函数调用中,call 指令实际上不会跳转到函数的真实地址。相反,它执行以下操作:1. 将函数的返回地址压入堆栈。2. 跳转到函数的真实地址。
所以我们在汇编中调试call,执行的第一步实际上是push eip压栈操作,继续单步走到jmp,再走一步就到了函数真实地址。
- mov dword ptr [ebp - 8] , 3 (操作数、操作内存单位、变量指针标识符、地址、值)
- xor异或, xor eax,eax 多用于寄存器清零
- inc op 相当于 op++
- 函数调用call之前的push都是在传参
- ESI(源索引寄存器)和EDI(目标索引寄存器)在x86架构中经常被用于处理字符串和内存复制操作。

