
Abstract
1 Introduction
基于神经网络的图像压缩方法最近已成为一个活跃的研究领域。 这些方法利用了常见的神经网络架构,如卷积自动编码器、循环神经网络等用于压缩和重建RGB图像,并且在感知指标上表现优于JPEG2000甚至BPG,这些指标包括结构相似性指数(SSIM)和多尺度结构相似性指数(MS-SSIM)。 实质上,这些方法将图像$x$编码为某个特征图(压缩表示),随后将其量化为一组符号$z$。 然后将这些符号(无损地)压缩为比特流,解码器从该比特流重建与$x$相同尺寸的图像$\hat x$参见图1和图2(a))。
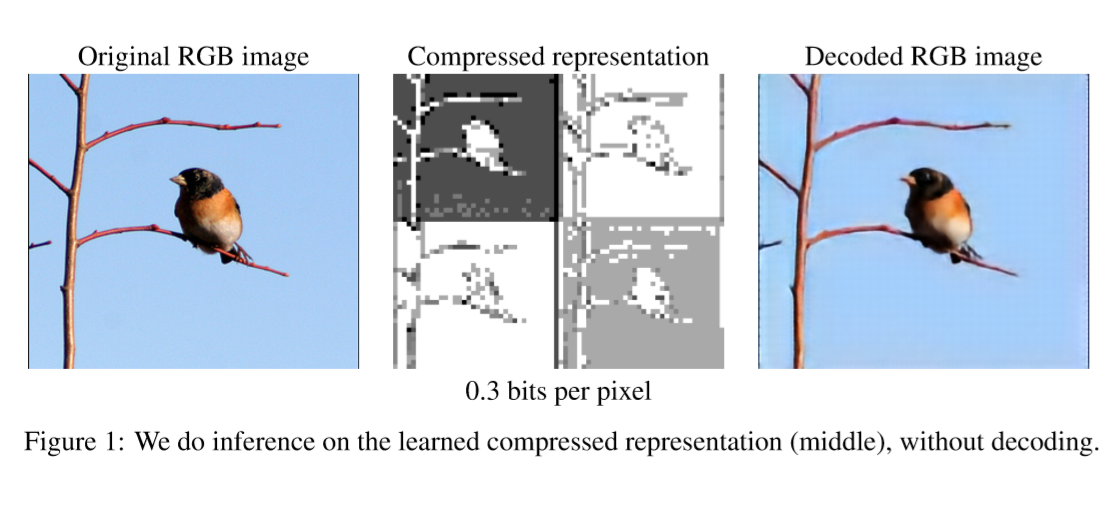
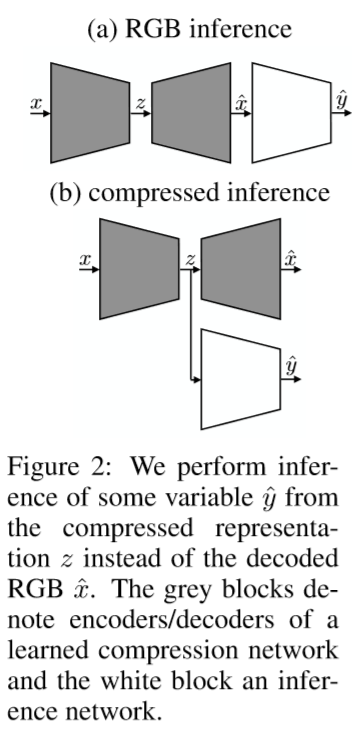
除了出色的压缩性能外,学习的压缩算法可以与工程压缩算法形成对比 - 可轻松适应特定的目标域,如立体图像,医学图像或航空图像,从而在目标域上实现更好的压缩率。 在本文中,我们探索了学习压缩算法与工程压缩算法相比的另一个有希望的优势,即它们在不重建的情况下产生的学习和推理的压缩表示的可用性(见图2)。 具体而言,不是从(量化的)压缩表示中重构RGB图像并将其馈送到网络以进行推理(例如,分类分类),而是使用通过重构RGB图像的构造来进行网络化。
这种方法背后的基本原理是通常用于学习压缩的神经网络体系结构(特别是编码器)与通常用于推理的神经网络体系结构相似,因此学习的图像编码器原则上能够提取与推理任务相关的特征。 编码器可以纯粹通过压缩任务的训练来学习与推理相关的特征,并且可以通过联合训练压缩和推理任务来强制学习这些特征。
学习用于图像压缩的编码器的优点是显而易见的,这样的编码器在处理之前(例如,在云处理中)传输图像的情况(例如,来自移动设备图像)中产生包含与推理相关的特征的压缩表示,因为它节省了RGB图像的重建以及部分的图像的特征提取,因此加速处理过程。 典型的用例是云照片存储应用程序,其中每个图像在上载后立即处理以用于索引和搜索目的。
我们的贡献可归纳如下:
我们考虑来自压缩图像表示的两种不同的计算机视觉任务,即图像分类和语义分割。具体而言,我们使用(Theisetal。,2017)中描述的图像压缩自动编码器,并使ResNet(Heetal。,2015)以及DeepLab(Chen等,2016)从压缩表示中进行推理。
实验表明来自压缩表示的图像分类基本上与解压缩图像(在解压缩图像上重新训练之后)一样准确,同时比重建图像和应用原始分类器需要少于1.5倍-2倍的运算。
进一步的结果表明,压缩表示的语义分割与中等压缩率的解压缩图像一样准确,而在较高的压缩率下更准确。这表明学得的压缩算法可能会以这些较高的速率学习语义特征或改善本地化。压缩表示的分割比解压缩图像的分割需要的运算少得多。
当联合训练图像压缩和分类时,我们观察到SSIM和MS-SSIM的增加,同时,改进了分割和分类准确性。
我们的方法仅需要对原始图像压缩和分类/分割网络进行微小更改,并在相应的训练过程中稍作更改。
在本文的其余部分安排如下。 我们在第2节中概述了相关工作。在第3节中,我们介绍了我们使用的深度压缩架构,在第4节中,我们提出了一种适用于压缩表示的ResNet变体(He et al。,2015)。 我们分别在第4节和第5节中提出了对压缩表示的图像分类和语义分离的评估方法,以及压缩RGB图像的基线。 在第6节中,我们讨论了压缩表示中图像压缩和分类的联合训练。 最后,我们将在第7节讨论我们的发现。
2 Related Work
在文献中,有一些例子是从工程编解码器压缩的图像中提取的特征中学习。在(Hahn等人,2014; Aghagolzadeh&Radha,2015)中研究了压缩高光谱图像的分类。最近,Fu&Guimaraes(2016)提出了一种基于离散余弦变换(DCT)的算法,在将图像馈送到神经网络之前对图像进行压缩,据报道,训练速度提高2到10倍,图像分类精度损失较小。 Javed等人(2017)直接在压缩域中提供了关于文档图像分析技术的批判性的回顾。据我们所知,之前没有考虑过由学习的图像压缩算法产生的压缩表示的推断。
在视频分析的背景下,提出了直接从压缩视频推断的不同方法(使用工程编解码器获得),参见(Babu等人,2016)的概述。压缩视频流的时间结构自然适用于许多推理任务的特征提取。例子包括视频分类(Biswas&Babu,2013; Chadha等,2017)和行动识别(Yeo等,2008; Kantorov&Laptev,2014)。
我们提出了一种方法,该方法在学习的特征表示之上进行推理,因此与使用自动编码器进行无监督特征学习具有直接关系。 Hinton和Salakhutdinov(2006)提出了一种使用自动编码器的维数降低方案,以学习可用于分类和回归的可靠图像特征。 Vincent等人(2008)提出了更鲁棒的维数降低,Rifai等人(2011)通过使用去噪自动编码器和分别惩罚学习表示的雅可比行列式来获得更鲁棒/稳定的特征。 Masci等人。 (2011)提出卷积自动编码器来学习分层特征。
最后,来自学习和工程压缩算法的压缩工件将损害推理算法的性能。在(Dodge&Karam,2016)中研究了JPEG压缩伪像对使用神经网络的图像分类的影响。
3 Learned Deeply Compressed Representation
3.1 Deep Compression Architecture
对于图像压缩,我们使用(Theis等人,2017)中提出的卷积自动编码器和使用标量量化的(Agustsson等人,2017)中描述的训练过程的变体。 有关详细信息,请参阅附录A.1。 我们在此注意到卷积自动编码器的编码器产生尺寸为w / 8×h / 8×C的压缩表示(特征图),其中w和h是输入图像的空间维度,并且通道C的数量是 与速率R相关的超参数。对于空间维度为224×224的输入RGB图像,编码器和解码器的计算复杂度分别为3.56×10^9和2.85×10^9 FLOP。
4 Image Classification From Compressed Representations
4.1 Resnet For RGB Images
对于RGB图像的图像分类,我们使用ResNet-50(V1)架构(He et al,2015)。 它分解为bottleneck残差单元,其中每个单元具有相同的计算成本,而与输入张量的空间维度无关(除了空间子采样的块和根块之外)。网络是全卷积的,其结构如表1,其输入空间维度为224×224。
遵循He等人的建筑配方。 (2015年),我们调整了14x14(conv4 x)块的数量,以获得ResNet-71,这是ResNet-50和ResNet-101之间的中间架构(见表1)。
4.2 Resnet For Compressed Representations
对于空间维度为224×224的输入图像,压缩网络的编码器输出尺寸为28×28×C的压缩表示,其中C是通道数。 我们提出了ResNet架构的一个简单变体,以使用此压缩表示作为输入。 我们将此变体称为cResNet-k,其中c代表“压缩表示”,k是网络中卷积层的数量。 这些网络是通过简单地“切除”常规的RGB ResNet的前面部分构建的。我们只需删除root block和空间尺寸大于28×28的残差层。为了调整层数k,我们 再次遵循He et al。(2015)的结构方案,仅调整14×14(conv4 x)残差块的数量。
采用这种方法,我们得到3种不同的体系结构:(i)cResNet-39是ResNet-50,如上所述去除了前11层,显着降低了计算成本; (ii)然后通过添加14×14残差块来获得cResNet-51和(iii)cResNet-72,以分别匹配ResNet-50和ResNet-71的计算成本(参见表1的最后一栏)。
对于空间维度为28×28的输入,表1给出了这些体系结构及其计算复杂性的描述。

4.3 Benchmark
我们使用ILSVRC2012的ImageNet数据集(Russakovsky等,2014)来训练我们的图像分类网络和我们的压缩网络。 它包括128万个训练图像和50k验证图像。 这些图像分布在1000个不同的类中。 对于图像分类,我们报告了用于RGB图像的224×224 center crop和用于压缩表示的28×28 center crop的验证集上的前1个分类准确度和前5个分类准确度。
4.4 Training Procedure
给定训练好的的压缩网络,我们在训练分类网络时保持压缩网络固定,无论是从压缩表示开始还是从重建的压缩RGB图像开始。 对于压缩表示,我们将固定编码器的输出(压缩表示)作为cResNets的输入(不需要解码器)。在对重建的压缩RGB图像进行训练时,我们将固定编码器解码器(RGB图像)的输出提供给ResNet。 这是针对3.1节中报告的每个操作点完成的。
对于训练,我们使用He et.al.(2015) 的标准超参数和略微修改的预处理程序。 详见附录A.4。 为了加速训练,我们以比He et .al快3.75倍的速度衰减学习速度。
4.5 Classification Results
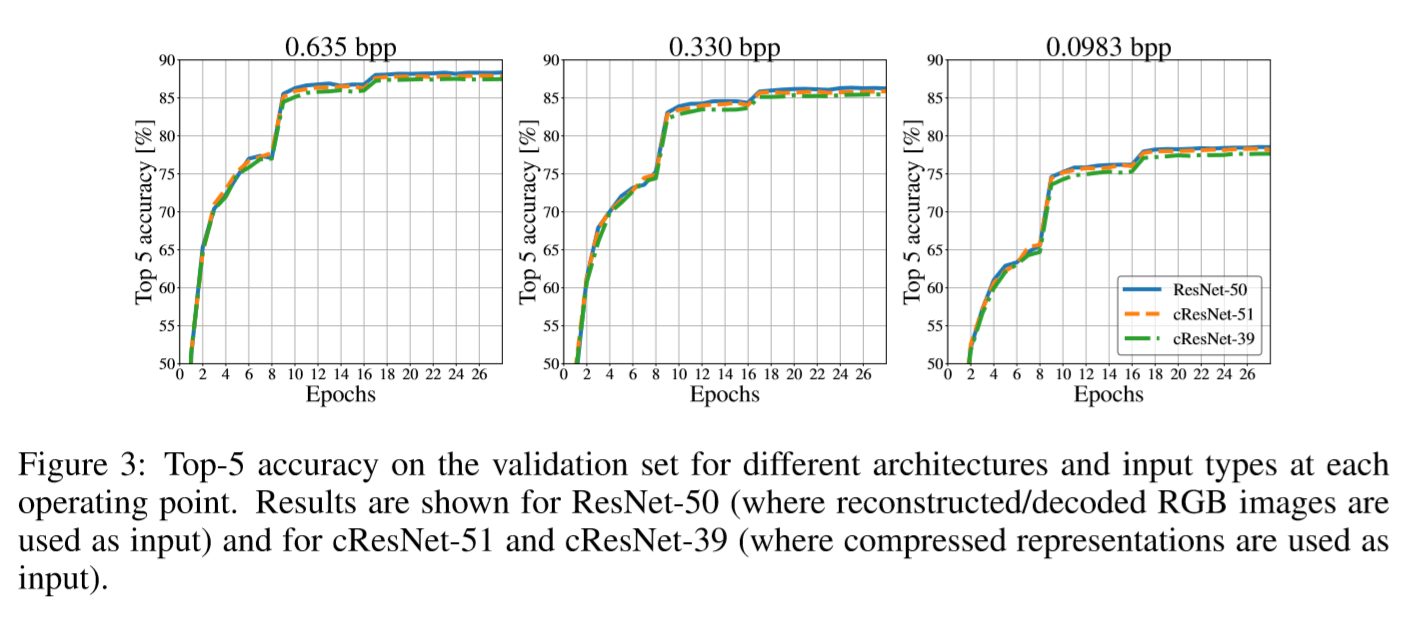
图2和图3中列出了关于操作点的不同结构的分类结果的结果,分别从压缩表示和相应的重建压缩RGB图像进行分类。 图3显示了ResNet-50,cResNet-51和cResNet-39的验证曲线。 对于具有相同计算复杂度的2种分类架构(ResNet-50和cResNet-51),0.635 bpp压缩操作点的验证曲线几乎一致,ResNet-50的性能稍好一些。 随着速率(bpp)变小,性能差距变小。 表2显示了不同体系结构融合时的分类结果。 在0.635 bpp的工作点,ResNet-50在前5个精度方面的性能仅比cResNet-51高0.5%,而对于0.0983 bpp的工作点,这个差异仅为0.3%。
使用相同的预处理和相同的学习速率设计,但从原始未压缩的RGB图像开始,产生89.96%的top-5 accuracy。 从0.635 bpp压缩操作点的压缩表示获得的top-5 accuracy(87.85%)甚至与原始图像准确度相当,并显着降低的存储成本。 具体而言,ImageNet数据集在0.635 bpp时需要24.8GB的存储空间而不是原始版本的144GB,减少了5.8倍。
为了显示计算增益,我们将top-5 accuracy绘制为图6中0.0983 bpp压缩工作点的计算复杂度的函数。这通过使用不同体系结构的分类来完成,每个体系结构都具有相关的计算复杂性。然后将这些架构中的每一个的前top-5 accuracy绘制为其计算复杂度的函数。对于压缩表示,我们为体系结构cResNet-39,cResNet-51和cResNet-72执行此操作。对于重建的压缩RGB图像,我们使用ResNet-50和ResNet-71架构。观察固定的计算成本,重建的压缩RGB图像的性能提高约0.25%。
考虑固定的分类成本,压缩表示的推断成本约为0.6x10^9 FLOP。然而,当在固定的分类性能下考虑解码成本时,来自重建的压缩RGB图像的推断比压缩表示的推断成本高2.2x10^9 FLOP。
5 Semantic Segmentation From Compressed Representations
5.1 Deep Method
对于语义分割,我们使用基于ResNet的Deeplab架构(Chen et al,2016),在DeepLab-ResNet-TensorFlow中的代码基础上调整后实现。第4.1和4.2节中的cResNet和ResNet图像分类架构重新使用atrous convolutions,其中滤波器是上采样的,而不是对特征图进行下采样。这样做是为了增加它们的感受野并防止对特征图进行过度的的二次取样,如(Chen等,2016)所述。对于分割任务,ResNet架构被重构,使得输出特征映射具有比原始RGB图像小8倍的空间维度(而不是像分类那样二次采样32倍)。使用cResNets时,输出特征图具有与输入压缩表示相同的空间维度(而不是像分类那样对子样本进行二次采样)。这导致压缩表示和重建RGB图像具有大小相当的特征图。最后,这些分类架构的最后1000路分类层被一个不稳定的空间金字塔池(ASPP)取代,其中四个并行分支的速率为{6,12,18,24},这提供了最终的像素分类。
5.2 Benchmark
用于语义分割的PASCALVOC-2012数据集(Everingham et al.(2015))用于图像分割任务。 它有20个对象前景类和1个背景类。 该数据集包括1464个训练图像和1449个验证图像。 在每个图像中,每个像素都被标记为20个对象中的一类。原始数据集还进行了数据增强,增加了由Hariharan等人(2011)提供的额外标注。因此最终数据集有10,582个用于训练的图像和1449个用于验证的图像。 所有性能都是用所有类的逐像素交并比(IoU)测量的,或者是验证集上的平均交并比(mIoU)。
5.3 Training Procedure
cResNet / ResNet网络在ImageNet数据集上使用第4.4节中描述的关于图像分类任务的程序进行预训练,编码器和解码器按照第4.4节进行固定。 然后使用空洞卷积(dilated convolutions)cResNet-d / ResNet-d对架构进行调整,并在语义分段任务上进行调整。
对于分割任务架构的训练,我们使用与Chen等人(2016)相同的设置。 采用附录A.5中描述的略有修改的预处理程序。
5.4 Segmentation Results
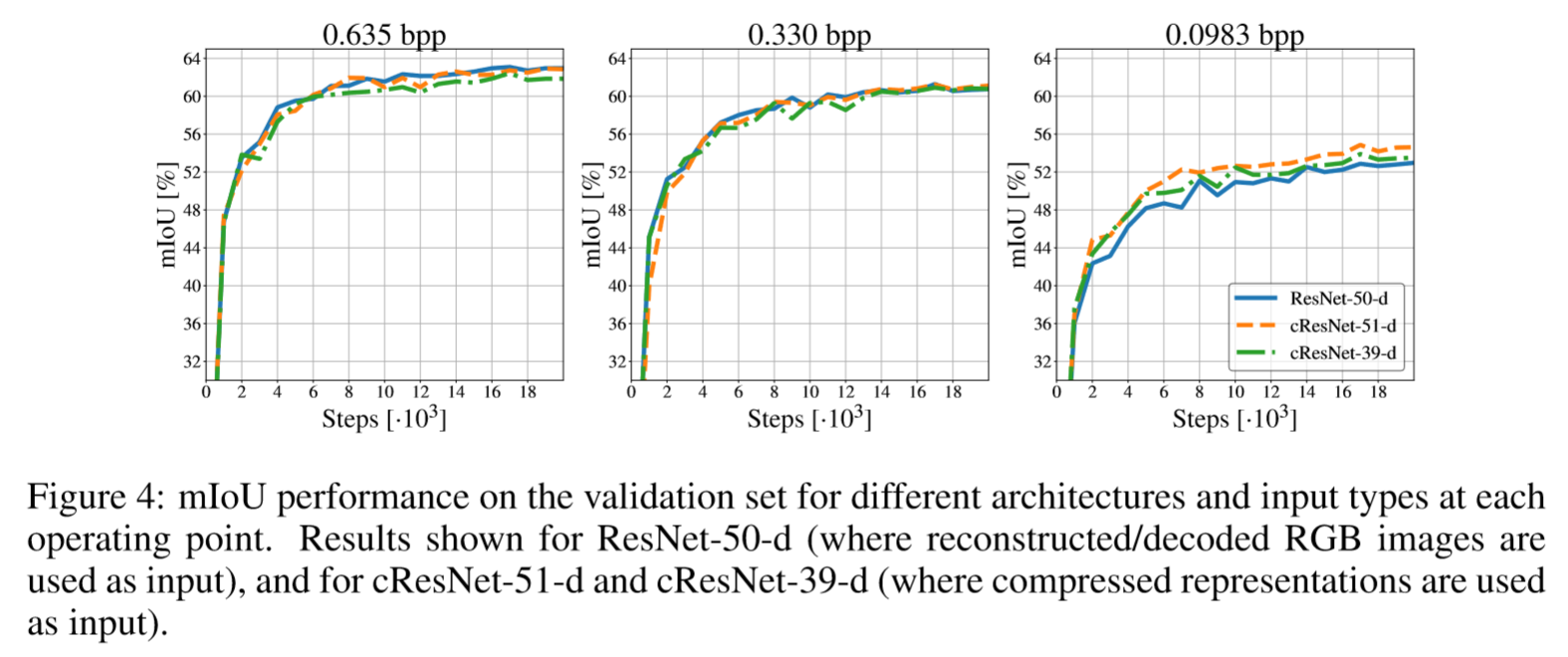
表2和图4列出了用于在每个操作点处进行语义分割的不同体系结构的结果,包括压缩表示的分割和对应的重建压缩RGB图像的分割。与分类不同,对于语义分割,ResNet50-d和cResNet-51-d在0.635 bpp的压缩操作点上表现同样出色。 对于0.330bpp的操作点,来自压缩表示的分割执行稍好,0.37%,在0.0983bpp的操作点处,来自压缩表示的分割比重建的压缩RGB图像执行明显好得多,为1.65%。
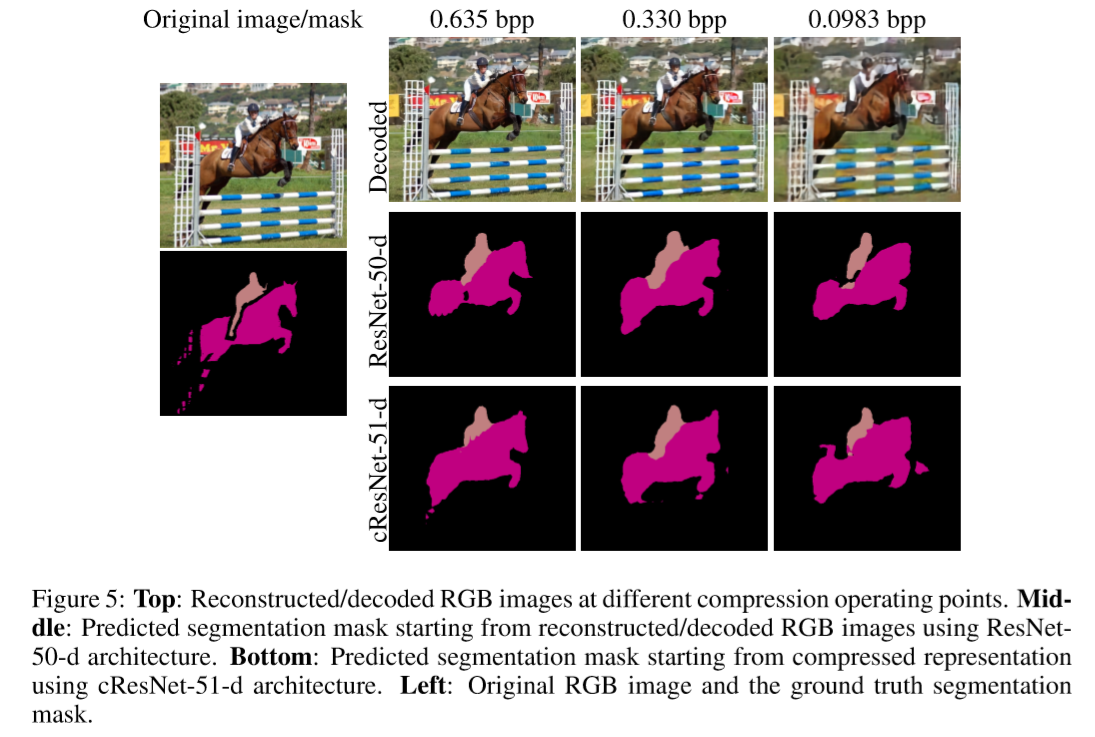
图5展示了在每个工作点的cResNet-51-d和ResNet-50-d架构的可视化预测分割。 除了分割,它还显示原始的未压缩RGB图像和重建的压缩RGB图像。 这些图像突出了这些分割特征中具有挑战性的特征,但仍然可以使用压缩表示来完成。这些图像还表明压缩会影响分割,因为降低每像素比特数(bpp)会逐渐消除图像中的细节。 将重建的RGB图像的分割与视觉上的压缩表示的分割进行比较,它们的表现相似。 更多视觉示例见附录A.6。
6 Joint Training For Compression And Image Classification
6.1 Formulation
为了同时训练压缩和分类,我们将压缩网络和cResNet-51架构相结合。 在图2 b)中可以看到此设置的概览,其中所有部件,编码器,解码器和推理网络同时被训练。压缩表示被馈送到解码器以优化均方重建误差并且被馈送到cResNet-51网络以使用交叉熵损失来优化分类。组合损失函数采用如下形式:
\[{L_c} = \gamma \left( {MSE\left( {x,\hat x} \right) + \beta \max \left( {H\left( q \right) - {H_t},0} \right)} \right) + {l_{ce}}\left( {y,\hat y} \right)\]
其中,用于压缩的 loss 项$$MSE\left( {x,\hat x} \right) + \beta \max \left( {H\left( q \right) - {H_t},0} \right)$$,与仅用于压缩的网络训练的Loss相同(见等式1)。${l_{ce}}$是分类的交叉熵,$\gamma$控制了压缩 loss 和分类 loss 之间的 trade-off。
当训练cResNet-51网络进行图像分类时,如第4.4节所述,压缩网络是固定的(在按照第3.1节的描述进行过训练之后)。 在进行联合训练时,我们首先从第3节和第4节中描述的训练状态初始化压缩网络和分类网络。初始化后,两个网络联合起来同时进行微调。 我们从训练状态初始化,我们的学习速率变很小(learning rate schedule is short ),并且不会从初始状态过多地扰乱权重,所以我们称之为微调。 所用超参数的详细说明和训练流程见附录A.8。
为了控制分类精度的变化不仅仅是由于(1)更好的压缩操作点或(2)cResNet训练时间更长的事实,我们采取以下措施。 我们仅通过使用上述流程对压缩网络微调获得一个新的操作点。 然后,我们在这个新的操作点上训练cResNet-51。 最后,保持压缩网络固定在新的操作点,我们根据上面的训练计划训练cResNet-51 9个epochs。 这个过程控制(1)和(2),我们用它来和联合微调进行对比。
为了获得分割结果,我们采用联合训练的网络,通过压缩操作点,并采用联合微调的方法训练分类网络用于分割(cResNet-51-d)。 然后按照第5.3节中的方式进行训练。 因此,5.3节的不同之处仅在于预先训练好的网络。
6.2 Joint Training Results
首先,我们观察到如第6.1节所述联合训练压缩和分割网络并不会显着影响压缩性能。 更详细地说,联合训练将感知度量MS-SSIM和SSIM上的压缩性能提高了一小部分,并略微降低了PSNR(这几个指标都是越高越好),见附录A.7。
在图7中,我们展示了对网络进行finetuing时(使用cResNet-51),分类和分割度量如何变化(使用cResNet-51)。 可以看出,分类和分割结果在finetuning过程中从基线“向上移动”。 如果仅对压缩网络进行微调,对分类任务的性能略有提高,但对分割任务几乎没有任何改进。 然而,当联合训练时,分类的改进更大,对分割有了显着的改进。 有趣的是,对于0.635 bpp的工作点,分类性能类似于联合训练网络和仅训练压缩网络,但是当使用这些操作点进行分割任务时,差异是相当大的。
考虑到0.0983 bpp的工作点并观察图6中计算复杂性的改进,我们可以看到与仅训练压缩网络相比,联合训练网络使分类性能提高了2%,这个性能提升需要额外75%的cResNet-51计算复杂度。 以类似的方式,在联合训练网络之后的分割任务性能在mIoU中比仅训练压缩网络好1.7%。 使用图6将其转换为计算复杂度,通过向网络添加层来获得此性能改进需要cResNet-51的额外40%的计算复杂度。
7 Discussion
我们提出并探索了直接从学习的压缩表示开始而不需要解码的推理,用于两个基本的计算机视觉任务:图像的分类和语义分割。
在我们的实验中,我们偏离了Theis等人(2017)提出的最新的深度压缩架构,并表明所获得的压缩表示可以很容易地提供给标准的现有DNN架构的变体,同时实现与处理解码/重建RGB图像的未修改DNN架构相当的性能(见图6)。 特别是,为了获得我们的结果,只需要对原始压缩和分类/分割网络的训练过程和超参数进行微小的改变。
所提出的无需解码的深度压缩图像理解方法的主要优点如下:
运行时间:我们的方法节省了解码时间和DNN推理时间,因为使用压缩表示的DNN模型的深度可以比使用解码的RGB图像的模型深度更小,但性能相当。
内存:消除重建图像的需要是一项壮举,具有应用于专用硬件(如汽车行业)的实时内存受限设备的巨大潜力。我们的模型具有较浅的DNN模型和很好的压缩率(低bpp),并具有良好的性能。
鲁棒性:该方法成功验证了图像分类和语义分割,而特定DNN模型的变化极小,这使我们相信该方法可以扩展到大多数相关的图像理解任务,例如目标检测或 structure-from-motion。
协同作用:压缩和推理DNN模型的联合训练使压缩质量和分类/分割精度得到协同改进。
性能:根据我们的实验和所取得的最佳性能,压缩表示是作为图像理解任务的最常用的解码图像的有前途的替代方案。
与此同时,这种方法有一些缺点:
复杂性:与目前的标准压缩方法(如JPEG,JPEG2000)相比,我们使用的深度编码器和学习过程使时间和内存复杂度增加。 然而,对于深度压缩的研究尚处于起步阶段,而JPEG等技术已经成熟。 最近,Rippel&Bourdev(2017)已经表明,深度压缩算法可以实现与GPU上的标准压缩算法相同或更高的压缩/解压缩速度。 随着越来越多的设备配备专用的深度学习硬件,深度压缩可能变得司空见惯。
性能:所提出的方法特别适用于较高的压缩率(低bpp)以及内存约束和存储至关重要场景。 中等和低bpp压缩率也是深度压缩算法明显优于标准压缩率的情形。
将我们从压缩表示学习的方法扩展到其他计算机视觉任务是未来工作的一个有趣方向。 此外,获得对图像压缩网络学习的特征/压缩表示的更好理解可能导致在无监督/半监督学习的背景下的有趣应用。
