python 5
正则表达式
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配。
字符组
普通字符包括没有显式指定为元字符的所有可打印和不可打印字符。这包括所有大写和小写字母、所有数字、所有标点符号和一些其他符号。
| 字符 | 描述 |
|---|---|
| [ABC] | 匹配 [...] 中的所有字符,例如 [aeiou] 匹配字符串 "google runoob taobao" 中所有的 e o u a 字母。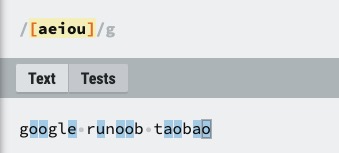 |
| [^ABC] | 匹配除了 [...] 中字符的所有字符,例如 [^aeiou] 匹配字符串 "google runoob taobao" 中除了 e o u a 字母的所有字母。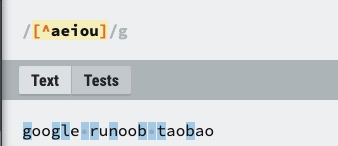 |
| [A-Z] | [A-Z] 表示一个区间,匹配所有大写字母,[a-z] 表示所有小写字母。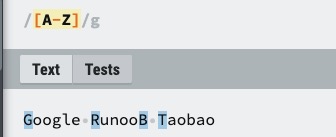 |
特殊符号
| 字符 | 描述 |
|---|---|
| . | 匹配除换行符以外的任意字符 |
| \w | 匹配数字、字母、下划线(后续筛选变量名可能用到) |
| \d | 匹配任意的数字 |
| \t | 匹配一个制表符(tab键) |
| ^ | 匹配字符串的开始 |
| $ | 匹配字符串的结尾 |
| \W | 匹配非字母或数字或下划线 |
| \D | 匹配非数字 |
| a I b | 匹配a或者b 管道符就是or(或)的意思 |
| () | 给正则表达式分组 不影响正则匹配 |
| [] | 字符组的概念(里面所有的数据都是或的关系) |
| [^] | 上箭号出现在了中括号的里面意思是取反操作 |
量词
注意量词默认都是贪婪匹配(尽可能多的匹配)
| 字符 | 描述 |
|---|---|
| * | 重复零次或者多次(默认就是多次:越多越好) |
| + | 重复一次或者多次(默认就是多次:越多越好) |
| ? | 重复零次或者一次(默认就是一次:越多越好) |
| 重复n次 | |
| 重复最少n次最多多次(越多越好) | |
| 重复n到m次(越多越好) |
复杂正则的编写
# 校验用户身份证号码
身份证号码是一个长度为15或18个字符的字符串,如果是15位则全部由数字组成,首位不能为0;如果是18位,则前17位全部是数字,末位可能是数字或x
^[1-9][0-9]{14}
^[1-9][0-9]{16}[0-9x]
# 校验邮箱、快递单号、座机号...
"""很多常见的正则校验符号 不需要我们编写 直接百度查找即可"""
ps:百度的前提是自己能够看懂别人写的大致意思
^[1-9]\d{13,16}[0-9x]$
^[1-9]\d{14}(\d{2}[0-9x])?$
^([1-9]\d{16}[0-9x]|[1-9]\d{14})$
取消转义
'''
方法1:首先加"\"匹配该特殊字符本身,然后在转义字符(即"\")前加"\"
方法2:在特殊字符前加"\\"(或者使用[])
'''
\n \n False
\\n \n True
\\\\n \\n True
在python中还可以在字符串的前面加r取消转义 更加方便
贪婪匹配与非贪婪匹配
| 正则 | 待匹配的文本 | 结果 |
|---|---|---|
| {scp}alert(123) | 1条 |
贪婪匹配:以最后一个花括号的出现作为结束标志
| 正则 | 待匹配的文本 | 结果 |
|---|---|---|
| {scp}alert(123) | 2条 |
非贪婪匹配:以第一个花括号的出现作为结束标志
量词默认都是贪婪匹配,如果想修改为非贪婪匹配,只需要在量词的后面加?即可,贪婪非贪婪通常都是利用左右两边的条件作为筛选依据
re模块
# 在python中无法直接使用正则 需要借助于模块
1.内置的re模块
2.第三方的其他模块
import re
1.findall()
ret = re.findall('a', 'eva jason yuan') # 返回所有满足匹配条件的结果,放在列表里
print(ret) #结果 : ['a', 'a']
"""
findall默认是分组优先展示
正则表达式中如果有括号分组 那么在展示匹配结果的时候
默认只演示括号内正则表达式匹配到的内容!!!
也可以取消分组有限展示的机制
(?:) 括号前面加问号冒号
"""
ret = re.findall('a(b)c', 'abcabcabcabc')
print(ret) # ['b', 'b', 'b', 'b']
ret = re.findall('a(?:b)c', 'abcabcabcabc')
print(ret) # ['abc', 'abc', 'abc', 'abc']
2.search()
ret = re.search('a', 'eva jason yuan').group()
print(ret) #结果 : 'a'
# 函数会在字符串内查找模式匹配,只到找到第一个匹配然后返回一个包含匹配信息的对象
# 该对象可以通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。
'''针对search和match有几个分组(即有多少个括号) group方法括号内最大就可以写几'''
ret = re.search('a(b)c', 'abcabcabcabc')
# 一个分组
print(ret.group()) # abc
print(ret.group(0)) # abc
'group()的默认值为0'
print(ret.group(1)) # b
ret = re.search('a(b)(c)', 'abcabcabcabc')
print(ret.group(1)) # b 可以通过索引的方式单独获取分组内匹配到的数据
print(ret.group(2)) # c
# 分组之后还可以给组起别名
ret = re.search('a(?P<name1>b)(?P<name2>c)', 'abcabcabcabc')
print(ret.group('name1')) # b
print(ret.group('name2')) # c
3.match()
ret = re.match('a', 'abc').group() # 同search,不过仅在字符串开始处进行匹配,如果没有则直接返回None
print(ret)
#结果 : 'a'
# 该对象可以通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则直接报错。
4.finditer()
ret = re.finditer('\d', 'ds3sy4784a') #finditer返回一个存放匹配结果的迭代器
print(ret) # <callable_iterator object at 0x10195f940>
print(next(ret).group()) #查看第一个结果
print(next(ret).group()) #查看第二个结果
print([i.group() for i in ret]) #查看剩余的左右结果
5.compile()
obj = re.compile('\d{3}') #将正则表达式编译成为一个 正则表达式对象,规则要匹配的是3个数字
ret = obj.search('abc123eeee') #正则表达式对象调用search,参数为待匹配的字符串
print(ret.group()) #结果 : 123

