04 处理器 | 计算机组成原理
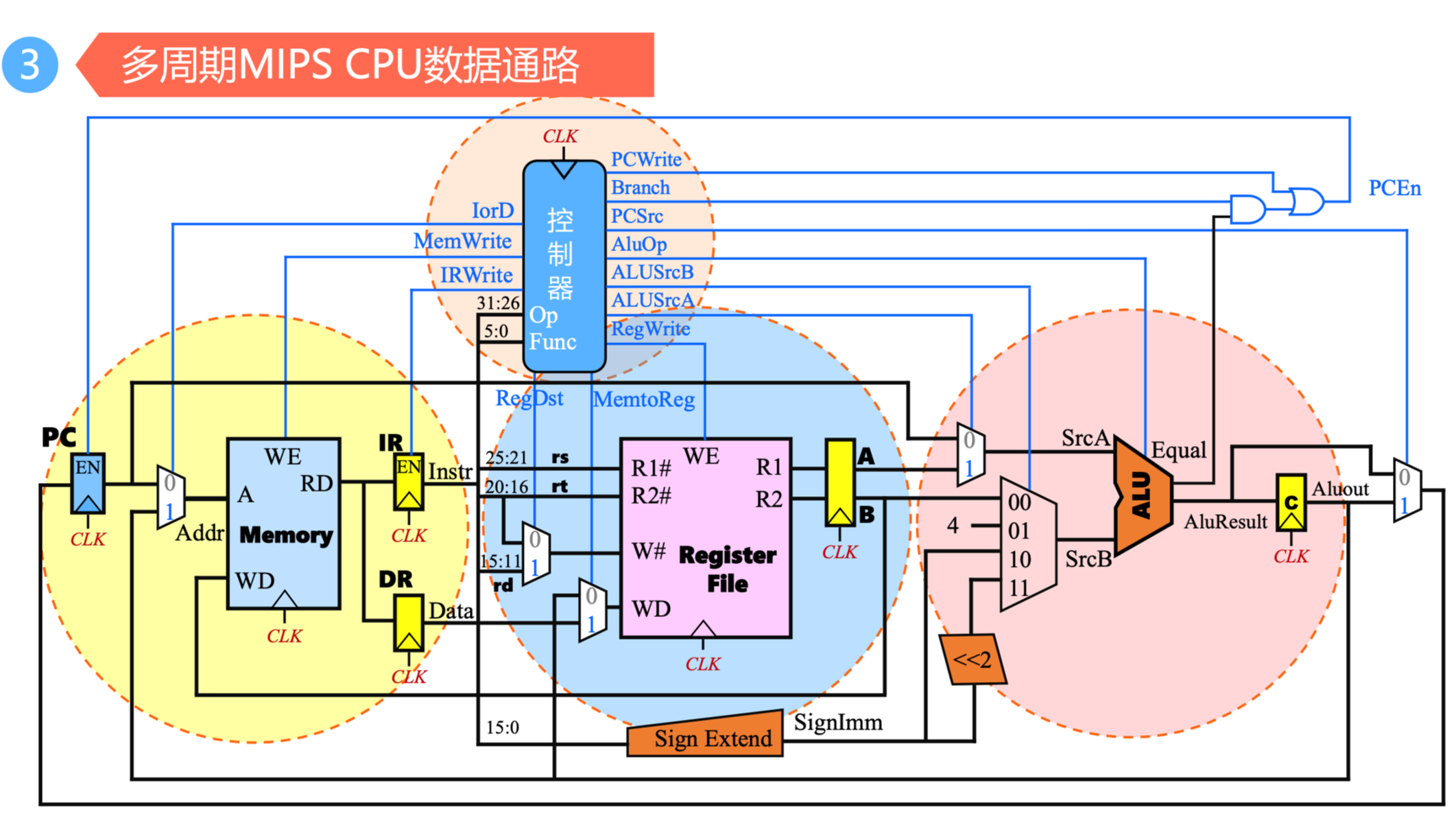 单周期、多周期以及流水线处理器
单周期、多周期以及流水线处理器
1. 概述
- 数据通路:指令执行过程中,数据所经过的路径(包括路径中的部件)
- 控制器:对指令进行译码,生成指令对应的控制信号,控制数据通路的动作,能对指令的执行部件发出控制信号
- 取指令
- 分析指令
- 执行指令
- 确定下一条指令的地址
- 执行环境的建立与保护
2. 逻辑设计规则
1. 数据通路组成
- 组合逻辑元件(操作元件):例如
- 特点
- 其输出只取决于当前的输入
- 所有输入到达后,经过一定的逻辑门延时,输出端改变,并保持到下次改变,不需要时钟信号来定时
- 特点
- 存储元件(状态元件):例如寄存器,指令存储器,数据存储器
- 特点
- 具有存储功能,在时钟控制下输入状态被写到电路中,直到下一个时钟到达
- 输入端状态由时钟决定何时写入,输出端状态随时可读出
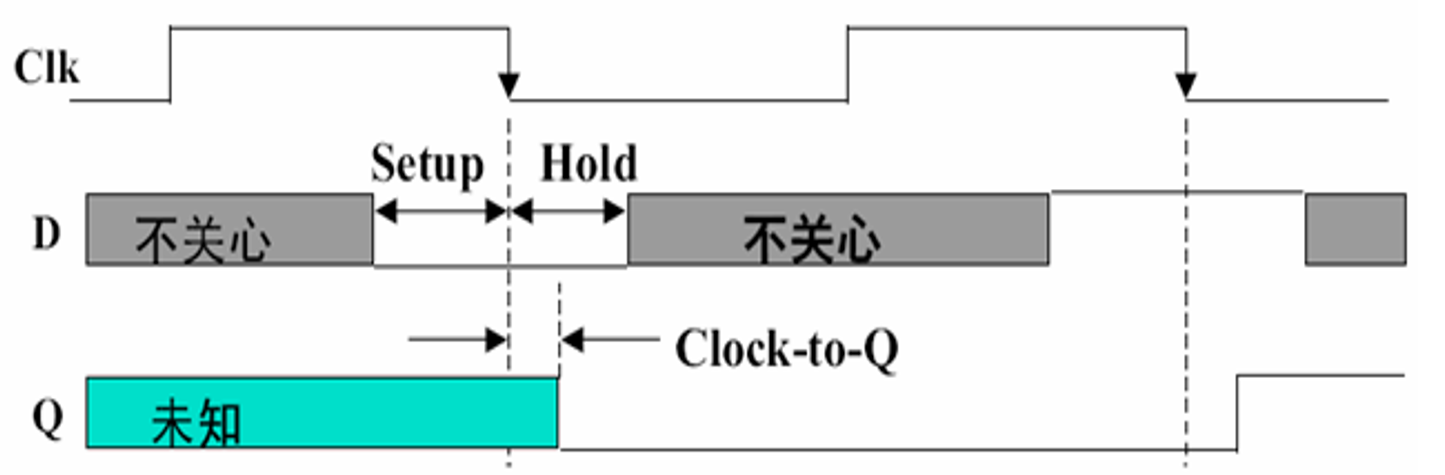
- 定时方式:规定信号何时写入状态元件或何时从状态元件读出,常用边沿触发方式:状态单元中的值只在时钟边沿改变;每个时钟周期改变一次
- 建立时间:在触发时钟边沿之前输入必须稳定
- 保持时间:在触发时钟边沿之后输入必须稳定
- 特点
2. 元件之间的连接方式
- 总线式连接
- 分散式连接
3. 同步系统
- 用专门的时序信号定时操作
- 时序信号规定何时发出什么操作
3. 数据通路的建立
1.
- 取指令
- 将地址移动到下一条指令
- 指令译码
- 计算
- 存储结果返回
- 判断和检测异常事件,若有异常,则自动切换到异常处理程序;检测是否有“中断”请求,有则转中断处理
2. 例:完成7条指令的简单数据通路
- 指令:
Add/Subtract,Or,Load/Store,Branch,Jump - 设计
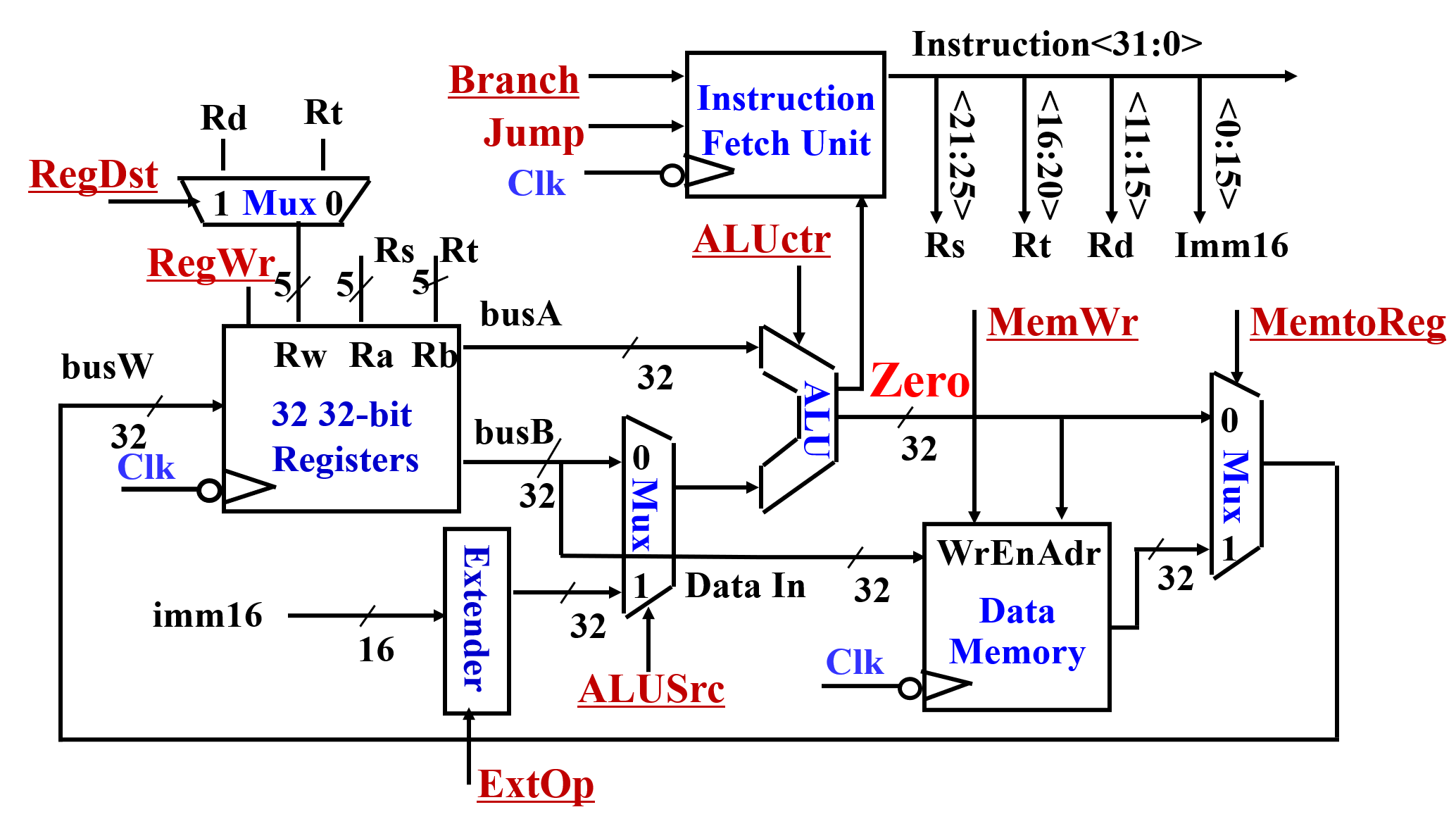
4. 单周期控制器的实现
1. 单周期处理器设计步骤
- 分析每条指令的功能
- 根据指令功能给出所需的元件,考虑如何互连
- 确定每个元件所需的控制信号的取值
- 汇总所有指令涉及到的控制信号,生成一张反映指令与控制信号之间的逻辑关系表
- 根据逻辑关系表得到每个控制信号的逻辑表达式,据此设计控制器电路
2. 单周期处理器
- 时钟周期:以最长指令的执行时间为时钟周期(保证每条指令都可以在单周期内完成)
- 单周期处理器性能不好的原因:单周期设计中,时钟周期对所有指令等长单周期处理器时钟宽度以最复杂指令的执行时间为基准很多指令可以在更短的时间内完成对于单周期处理器,只能改进多数指令的延迟而不能改进最差情况延迟的技术,将无法发挥作用
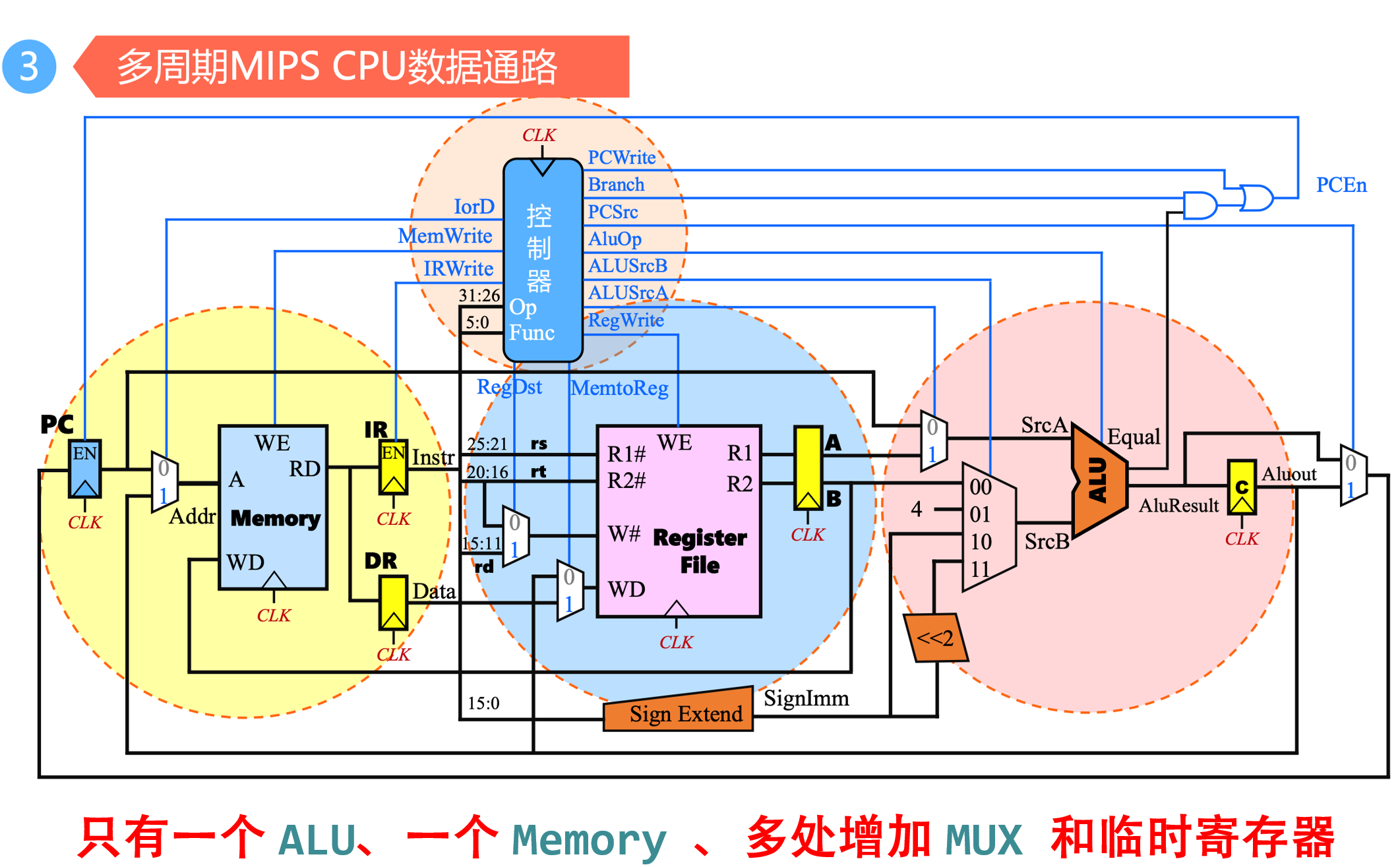
5. 多周期控制器的实现
1. 出现原因
- 为了解决单周期处理器的弊端,则把指令执行分成多个阶段,各阶段在一个时钟周期内完成
2. 阶段
- 取指令
- 指令译码
- 执行指令
- 访存
- 结果写回
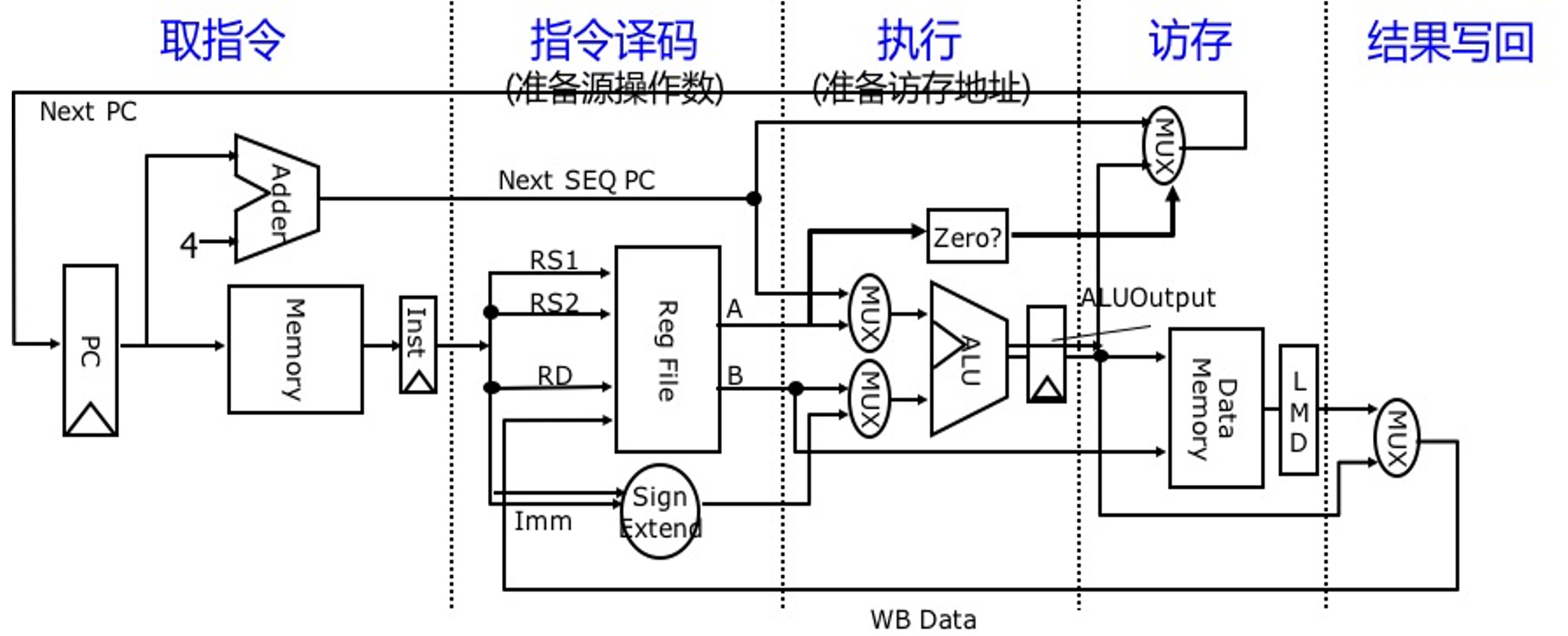
3. 多周期处理器的好处
- 时钟周期短
- 不同指令的周期可以不一样
- 允许功能部件在一条指令的执行过程中被重复利用
4. 多周期处理器设计的关键
- 在一条指令执行过程中,如何决定各个控制信号在不同周期的取值
5. 竞争冒险
- 竞争:在组合电路中,信号经由不同的路径到达某一会合点的时间有先有后的现象
- 冒险:竞争而引起电路输出发生瞬间错误。表现为输出端出现原设计中没有的毛刺
- 竞争冒险:因为信号传输延迟时间不同,而引起输出逻辑错误的现象
- 多时钟周期中,解决竞争问题的方案
- 确认地址和数据在第
- 使写使能信号在一个周期后(即:第
- 在写使能信号无效前地址和数据保持不变
- 确认地址和数据在第
6. 多周期控制器功能描述方式
- 有限状态机:采用组合逻辑设计方法用硬连线路
- 思路:由时钟、当前状态和操作码确定下一状态。不同状态输出不同控制信号值
- 设计控制逻辑,做出多周期处理器的状态转换图
- 微程序:用
6. 流水线
1. 流水线的基本原理
-
流水线
-
本质:提高完成指令执行的 吞吐率(时间维度上的并行)
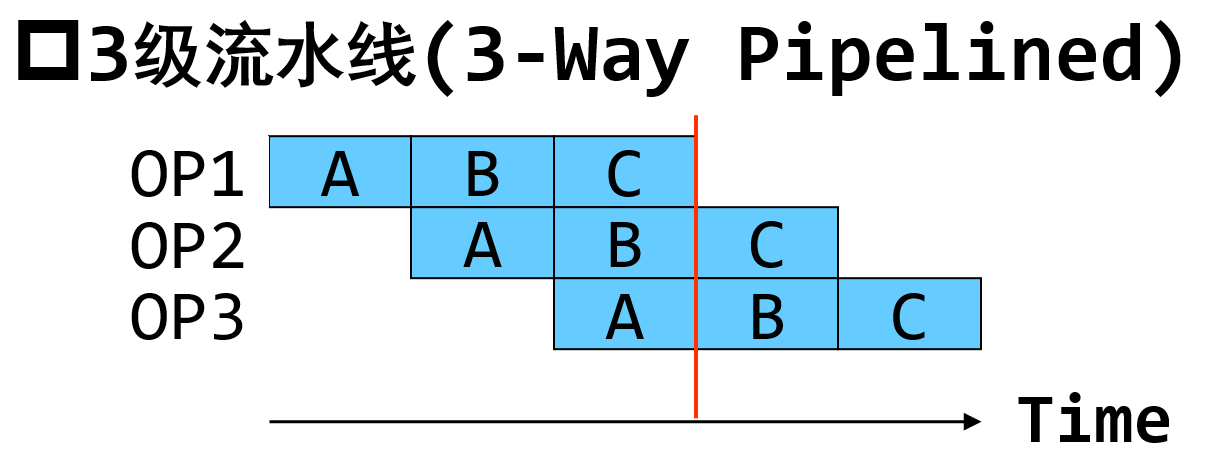
-
流水线级数提高的结果
- 优点:流水线的级数越多,意味着流水线被切得越细,每一级流水线内容的硬件逻辑越少,意味着运行更高的主频。主频越高,流水线的吞吐率越高
- 缺点:流水线过深,边际效益下降
- 每一级流水线都由寄存器组成,更多的流水线级数意味着消耗更多的寄存器,产生更大的面积开销,功耗也会增大,实际时间延迟也会增多
- 流水线的取指阶段不知道条件跳转的结果是否跳转,因此只能进行预测,而到了流水线的末端才能通过实际运算后如果发现真实的结果与预期的结果不一致,意味着预测失败,需要将所有的预取指令全部丢失。流水线越深,则意味着浪费和损失越严重;流水线越浅,则浪费和损失越少
-
流水线的延迟
-
寄存器的开销:每一个模块完成操作以后需要将结果放到指定的寄存器中
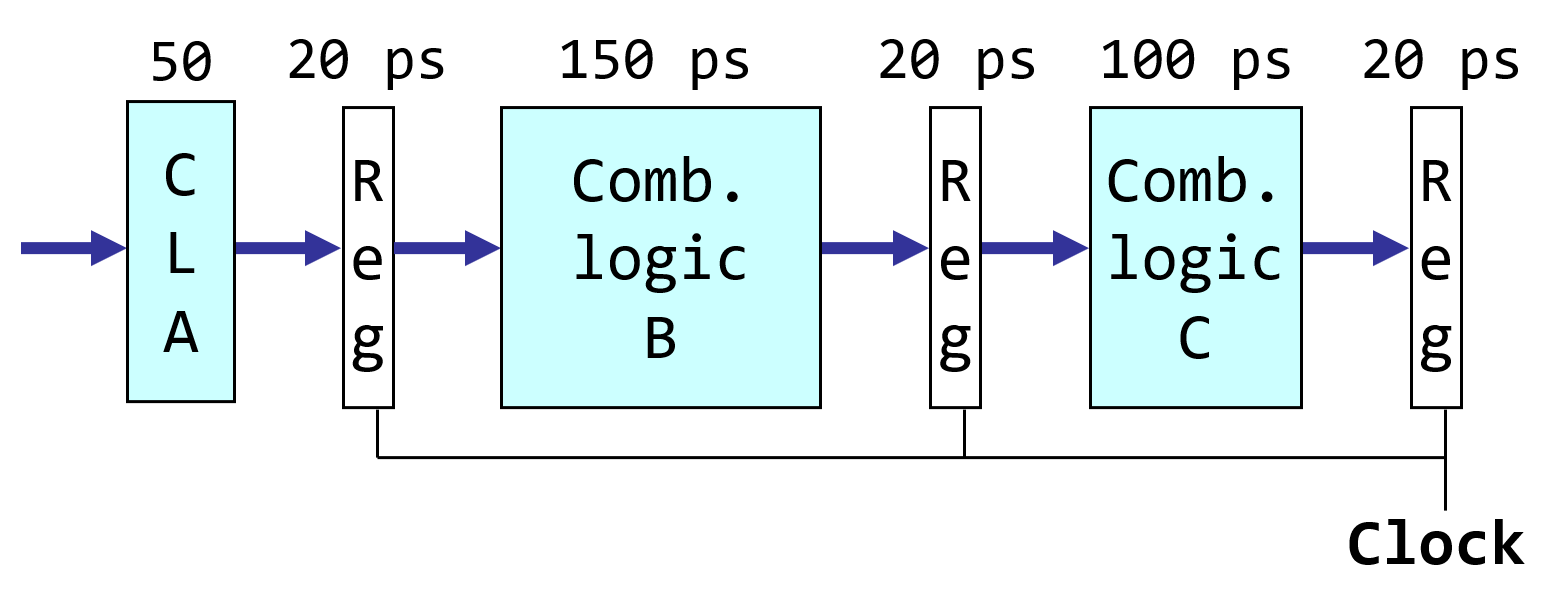
-
非均匀延迟:吞吐率局限于最慢的模块的实践,因此要尽量均匀各模块的时间长度
-
-
流水线的性能
- 单个时钟周期
- 最大加速比
- 单个时钟周期
-
具有什么特征的指令集有利于流水线执行
- 指令长度尽量一致:有利于简化取指令和指令译码操作
- 指令格式少,且源寄存器位置相同:有利于在指令未知时预取操作数
- 只有
- 数据和指令在内存中需要 对齐 存放,有利于减少访存次数和流水线的规整
2. 流水线冒险
-
结构冒险
-
流水线出现多条指令试图同时在一个功能模块上工作的问题
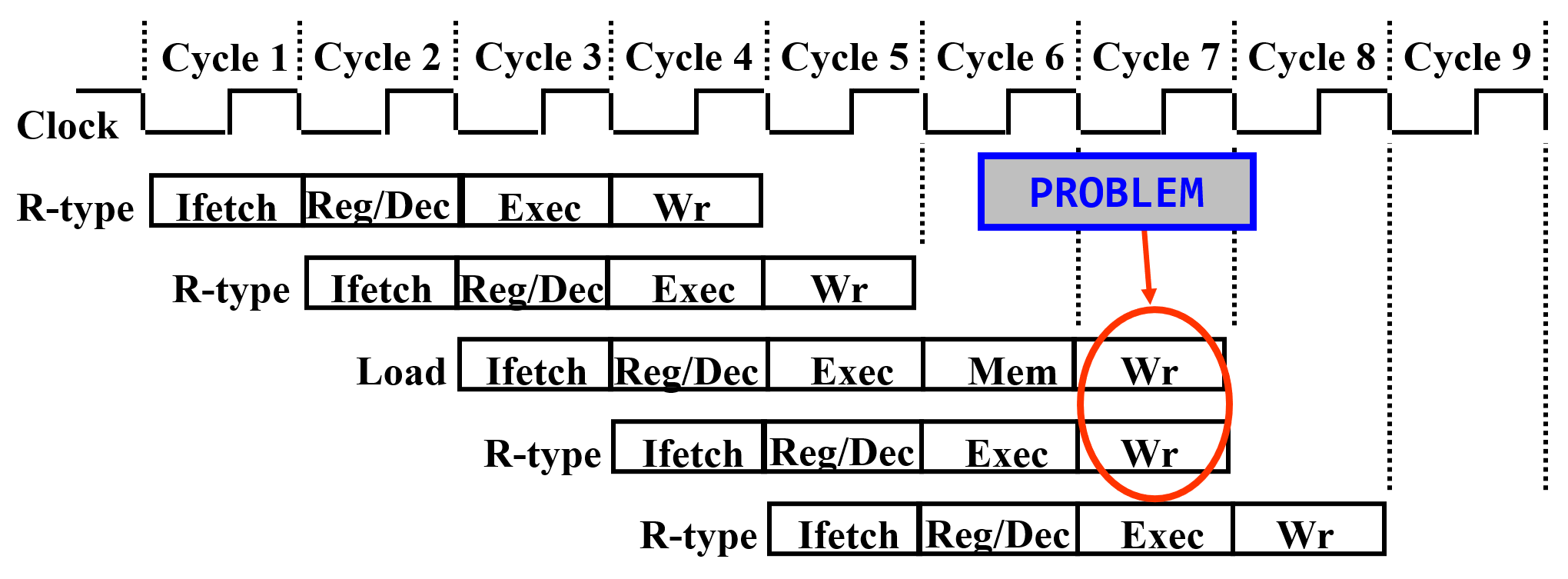
-
解决方法:规定流水线数据通路中功能部件的设置原则为:每个部件在特定的阶段被用
- 将
- 将寄存器读口和写口独立开来
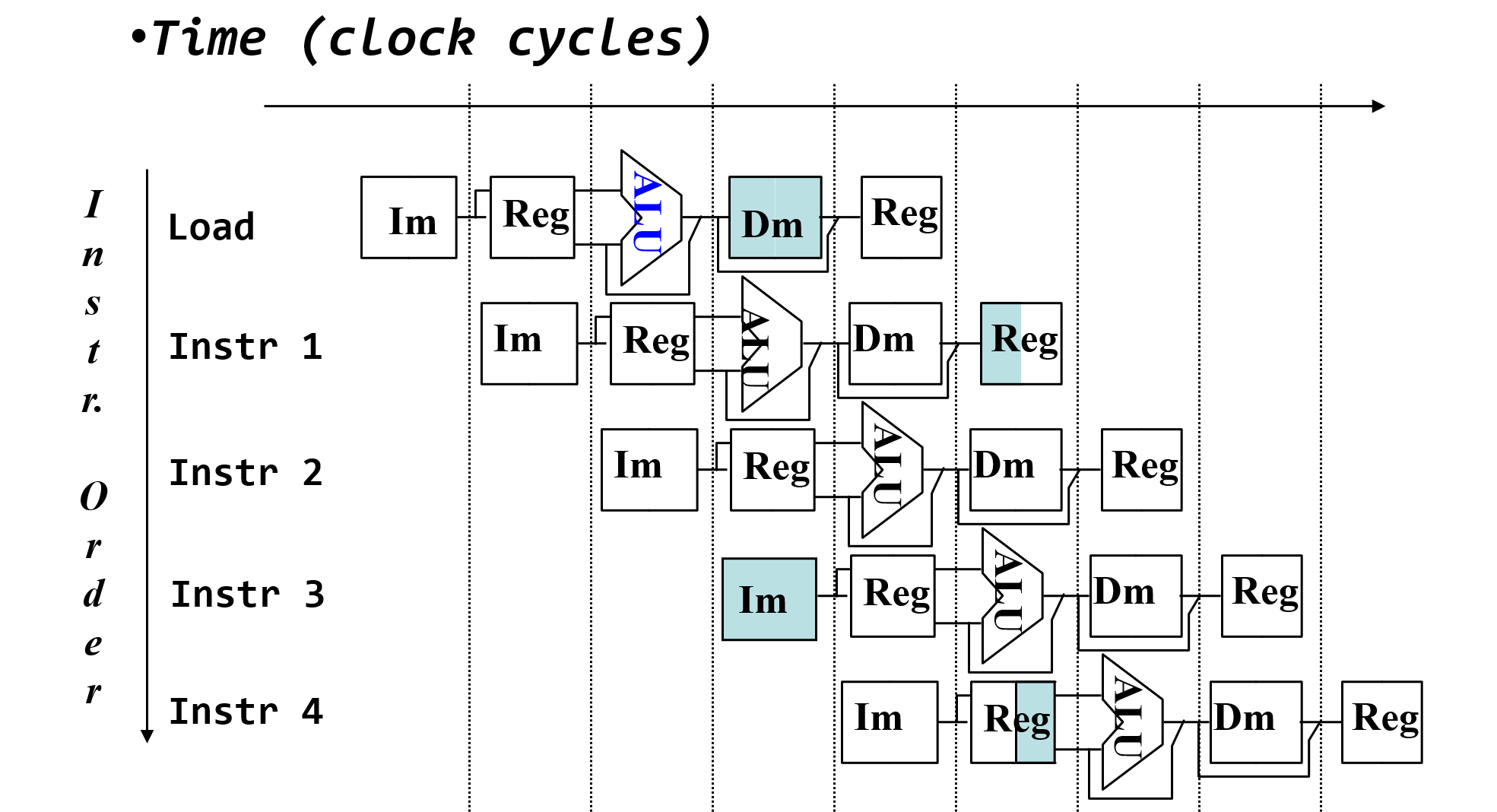
- 将
-
-
控制冒险
-
转移指令或异常处理改变了程序顺序执行流程,而顺序执行指令在目标地址产生之前已被取出
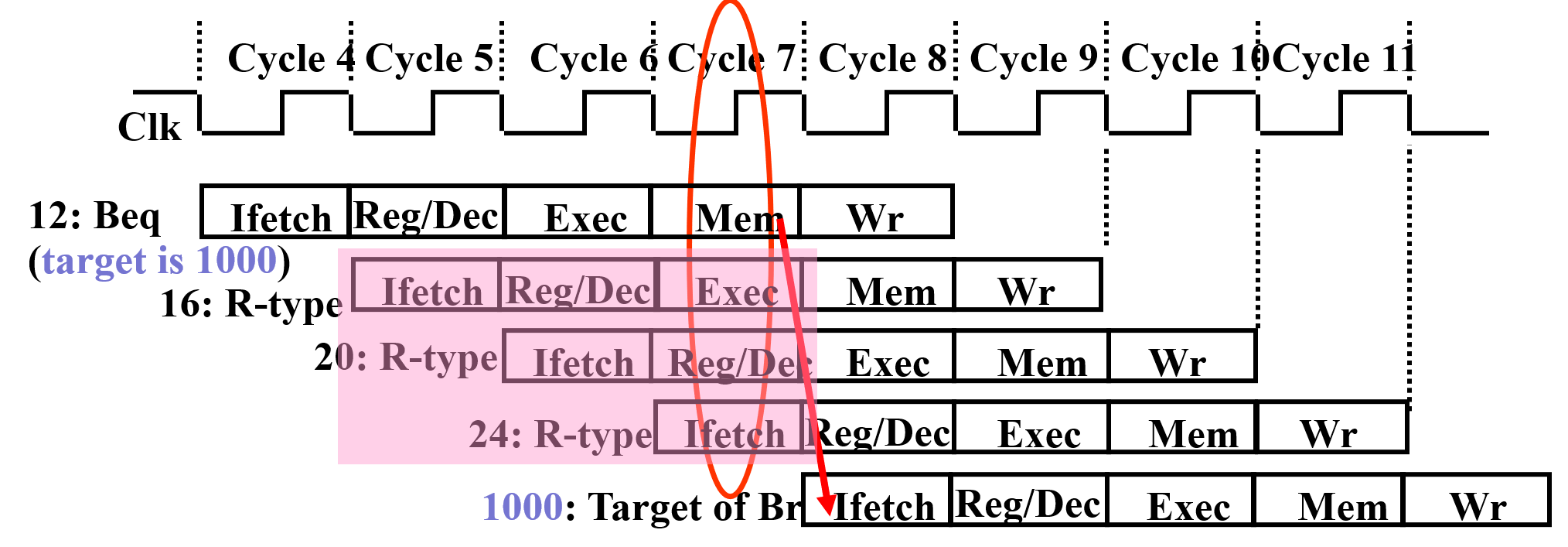
-
解决方法
- 硬件阻塞:硬件上阻塞分支指令后三条指令执行
- 插入无关指令:插入三条
NOP指令 - 分支 预测
- 简单(静态)分支预测:总是预测条件不满足;即:继续执行分支指令的后续指令
可加启发式规则:在特定情况下总是预测满足,其他情况总是预测不满足。如:循环顶(底)部分支总是预测为不满足(满足)。预测准确率可达65%-85% - 动态预测:根据程序执行的历史情况,进行动态预测调整,能达90%的预测准确率
- 基本思想:利用最近转移发生的情况,来预测下一次可能发生的转移;预测后,在实际发生时验证并调整预测;转移发生的历史情况记录在 分支历史记录表
- 注意:采用分支预测时,流水线控制必须确保错误预测指令的执行结果不能生效,能从正确的分支地址处重新启动流水线工作
- 简单(静态)分支预测:总是预测条件不满足;即:继续执行分支指令的后续指令
- 延迟分支:编译优化指令顺序
- 减少分支延迟:在流水线中尽早判断出分支转移是否转移;尽早计算出分支目标地址
- 把分支指令前面与分支指令无关的指令后面执行,也成为延迟转移
-
-
数据冒险
- 后面指令用到前面指令结果,但结果还没产生
- 解决方法
-
硬件阻塞:插入气泡
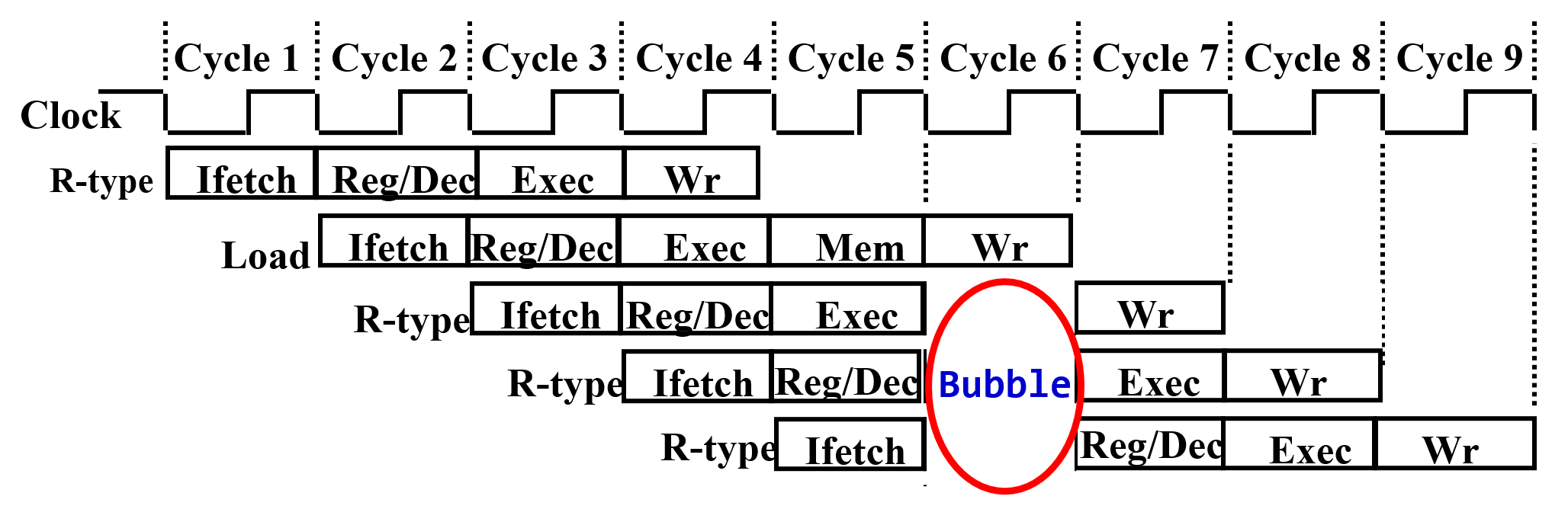
- 缺点:控制相当复杂,需要改变数据通路
-
插入无关指令:加一个
NOP阶段来延迟操作,让流水线中的每条指令都有相同的阶段数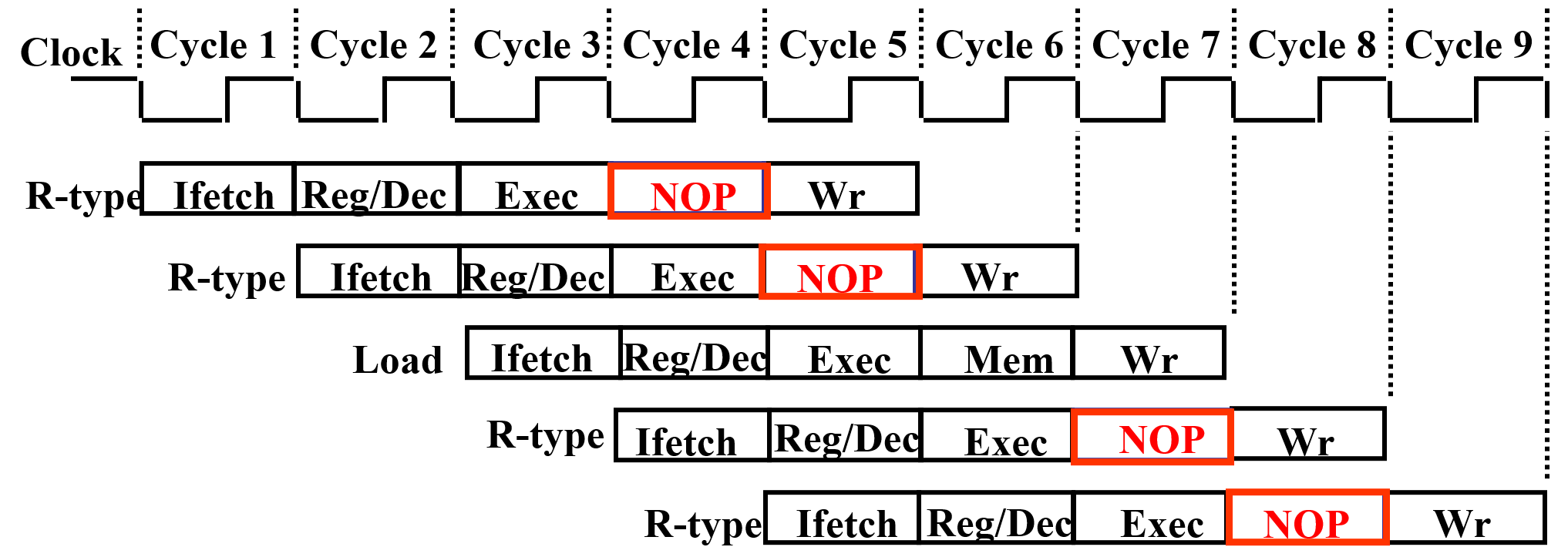
-
数据旁路
- 把数据从流水段寄存器直接取到
- 寄存器写/读口分别在前/后半周期,可以使写入的数据直接被读出
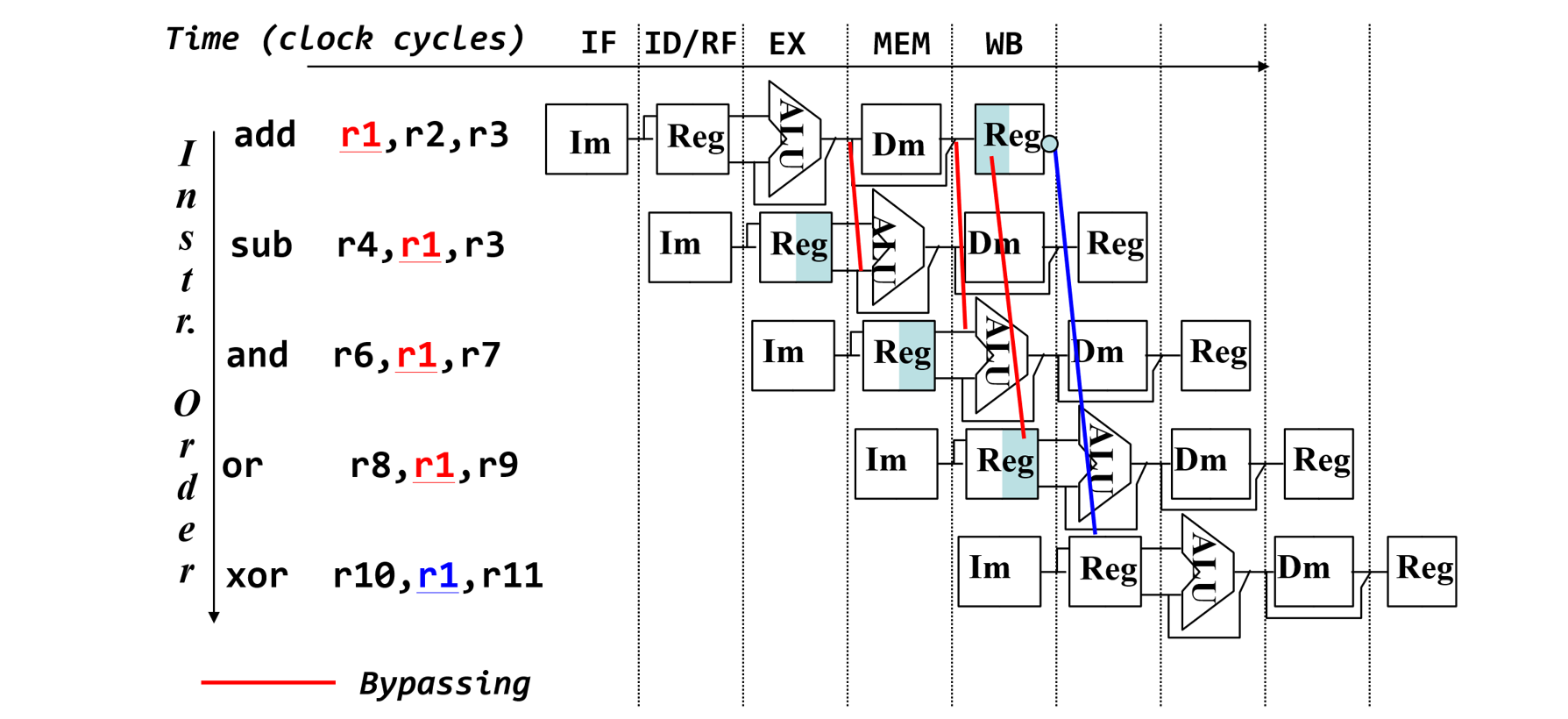
- 把数据从流水段寄存器直接取到
-
编译优化调整指令顺序(指令静态调度)
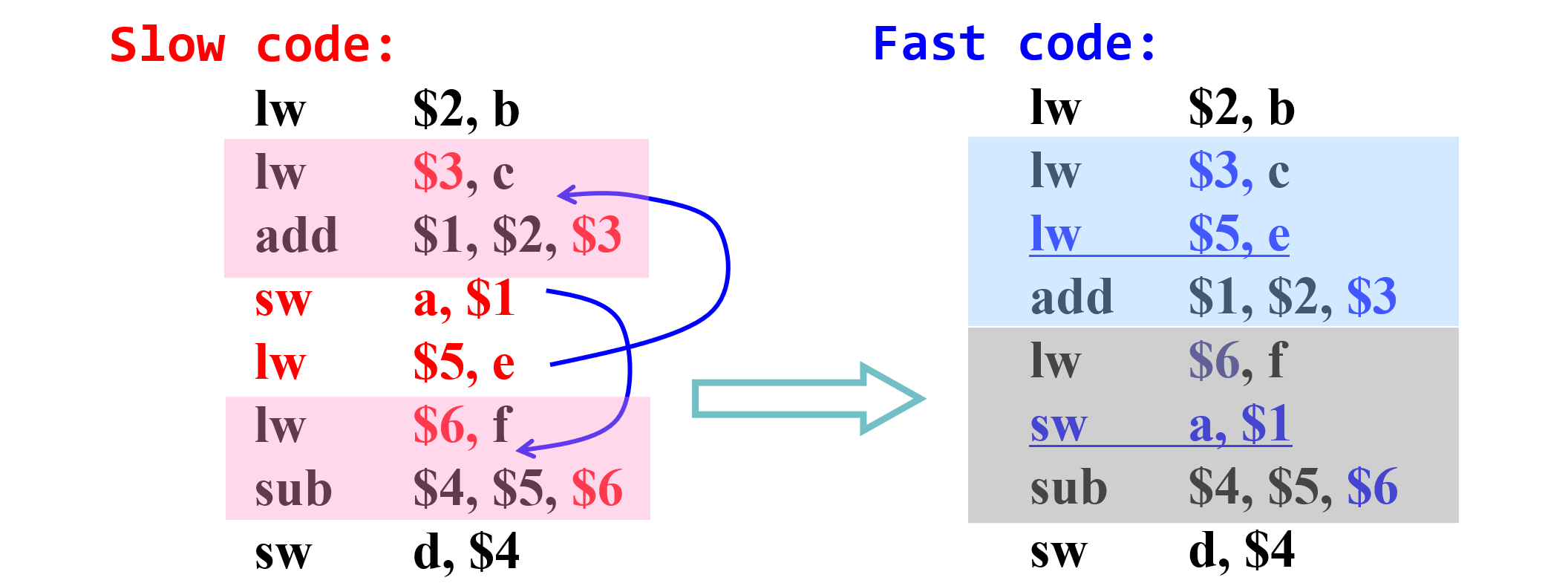
-
__EOF__

本文作者:RadiumGalaxy
本文链接:https://www.cnblogs.com/RadiumGalaxy/p/17105503.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!
本文链接:https://www.cnblogs.com/RadiumGalaxy/p/17105503.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!
标签:
Courses


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 25岁的心里话