07 参数估计 | 概率论与数理统计
 参数的各类估计方法
参数的各类估计方法
1. 点估计
1. 点估计
- 点估计问题:设总体
- 点估计:设总体
- 点估计常用方法
- 矩估计法
- 极大似然估计法
2. 矩估计法
- 基本思想:用样本矩估计总体矩,因为由大数定律知,样本的
- 方法:设总体
- 常见分布的矩估计量
- 均匀分布
- 指数分布
- (0-1)分布
- 二项分布
- 正态分布
- 泊松分布
- 均匀分布
3. 极大似然估计法
- 基本思想:概率最大的事件最可能出现;参数估计的极大似然法是要选取这样的值来作为参数的估计值,使得当参数取这一数值时,观测结果出现的可能性为最大
- 似然函数
- 离散型:设总体
- 连续型:设总体
- 离散型:设总体
- 最大似然估计:如果存在
- 如何求
- 根据函数的单调性分析
- 对数似然方程:由于
- 常见分布的最大似然估计量
- (0-1)分布
- 正态分布
- 均匀分布
- 指数分布
- 泊松分布
- (0-1)分布
4. 矩估计和极大似然估计的联系和区别
- 极大似然法克服了矩估计法的一些缺点, 它利用总体的样本和分布函数表达形式所提供的信息建立未知参数的估计量, 同时它也不要求总体原点矩存在
- 极大似然估计量一般要解似然方程,而有时解似然方程很困难,只能用数值方法求似然方程的近似解
- 在统计问题中往往先使用最大似然估计法,在最大似然估计法使用不方便时,再用矩估计法
2. 估计量的评选标准
1. 无偏性
- 引入原因:估计量是随机变量,对于不同的样本值会得到不同的估计值. 我们希望估计值在未知参数真值附近摆动,而它的期望值等于未知参数的真值. 这就出现了无偏性这个标准
- 无偏估计量:如果估计量
2. 有效性
- 引入原因:用
- 有效:设
3. 相合性
- 引入原因:无偏性和有效性是在样本容量
- 相合估计量:设
- 定理:若
3. 区间估计
1. 置信区间的概念
- 置信区间:设总体
- 评价置信区间好坏标准
- 精度:
- 置信度:
- 精度:
- 置信度与估计精度
- 估计精度:置信区间的长度
- 置信度与估计精度是一对矛盾的量
- 置信水平高,则区间大,区间精度差
- 置信区间小,则精度高,但置信水平低
- 一般准则:在保证置信度的条件下尽可能提高精度
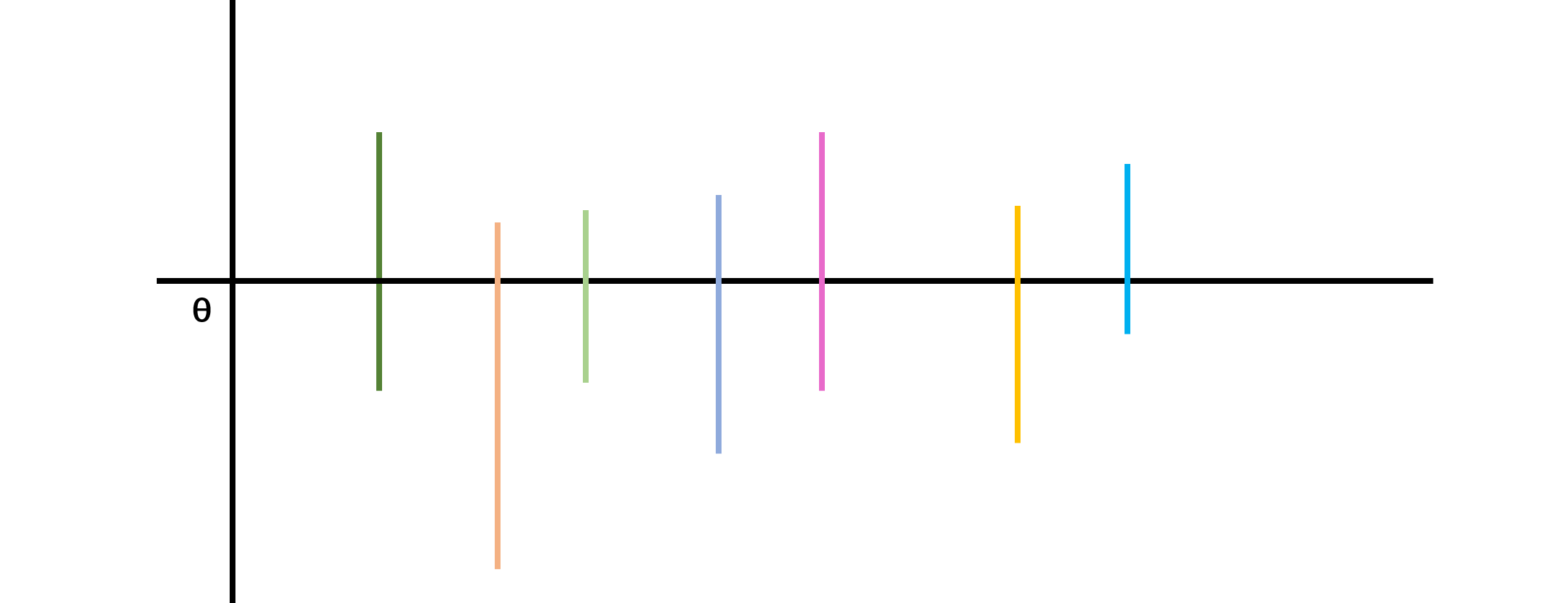
- 估计精度:置信区间的长度
2. 寻求置信区间的方法
- 基本思想:在点估计的基础上,构造合适的含样本及待估参数的函数
- 一般步骤
- 选取未知参数
- 围绕
- 对给定的置信水平
- 对上式作恒等变形,化为
- 选取未知参数
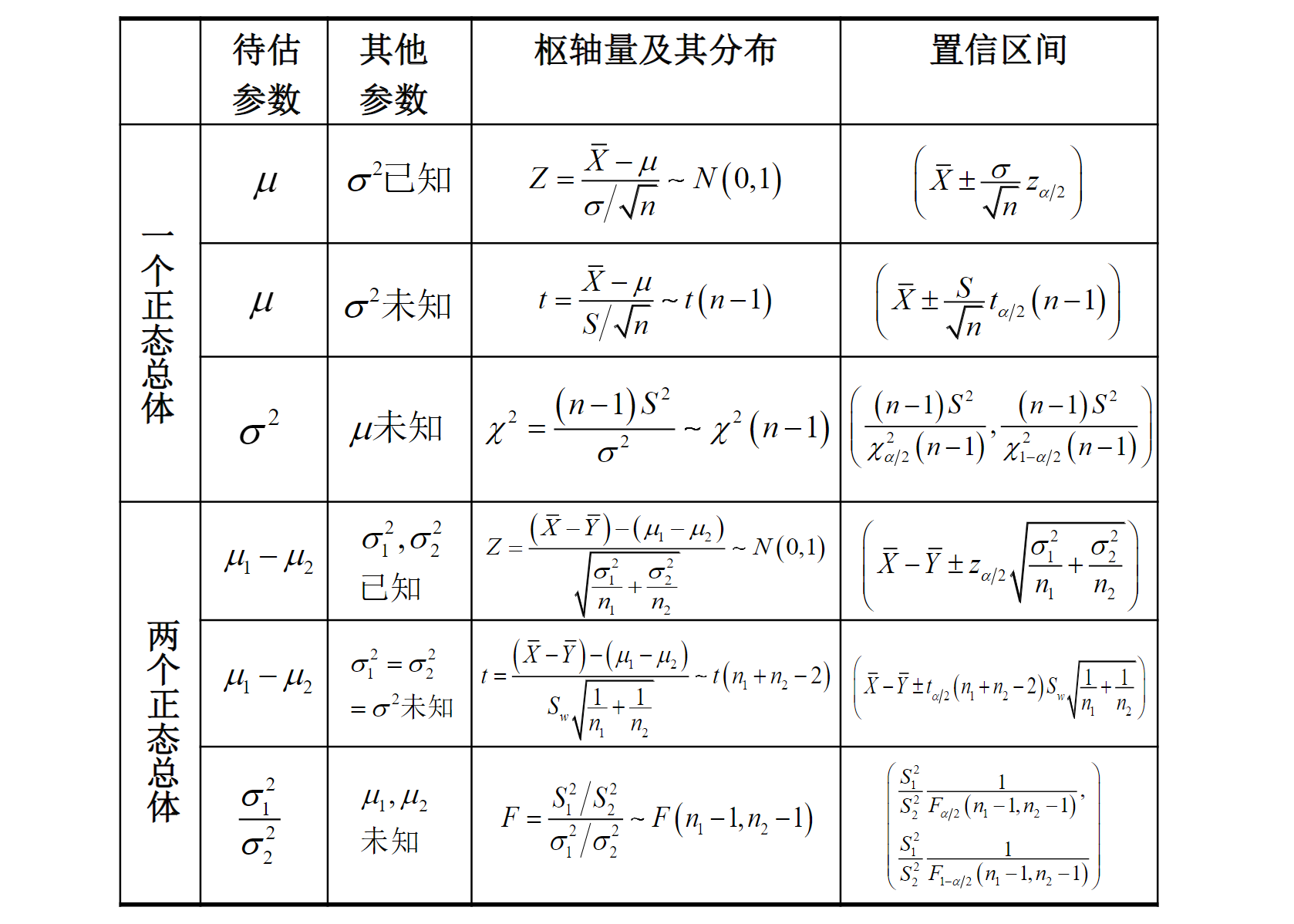
4. 正态总均值与方差的区间估计
1. 单个正态总体
-
均值
-
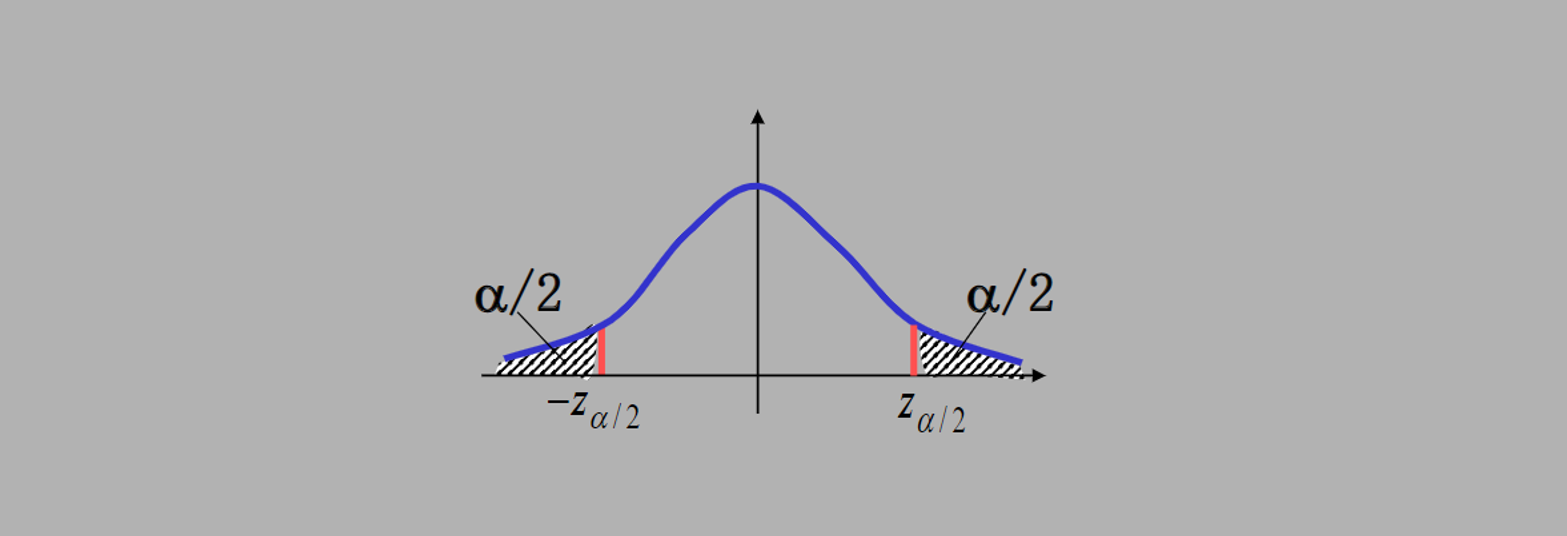
-
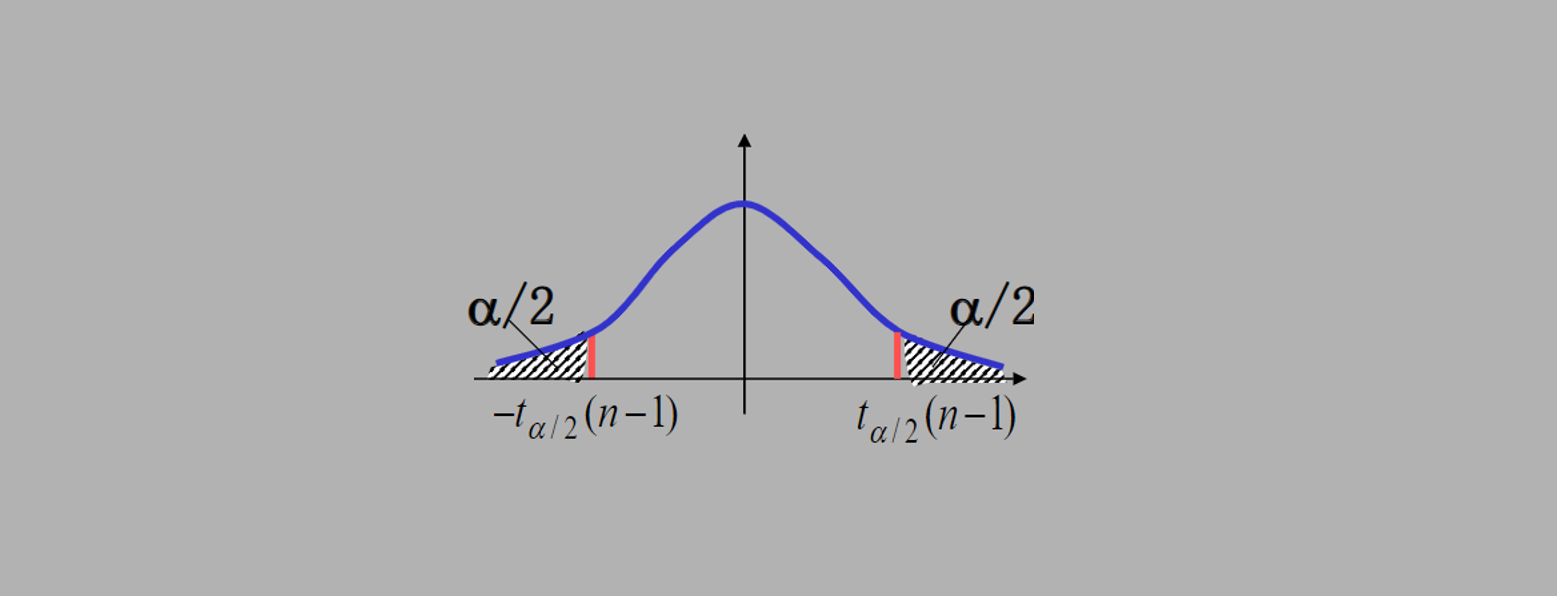
-
-
方差
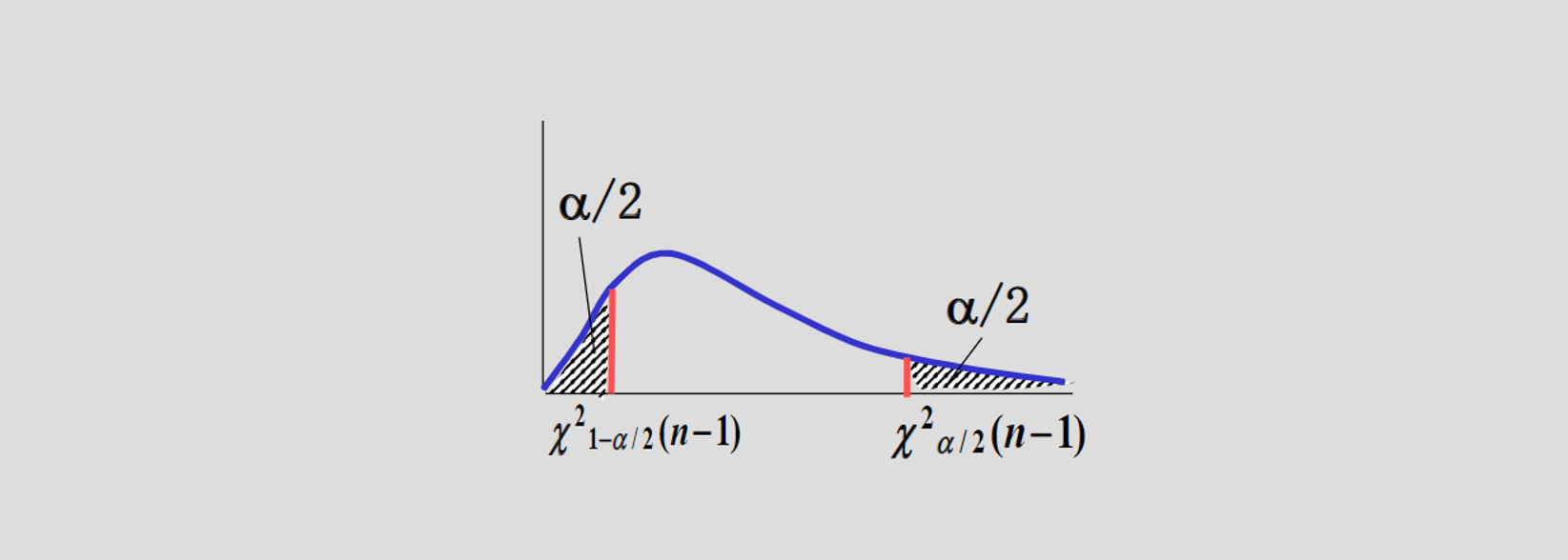
2. 两个正态总体
- 两个总体均值差
- 两个总体方差比
- 置信区间:
- 置信区间:
- 正态总体均值、方差的置信区间总结
5. (0-1)分布参数的区间估计
1. (0-1)分布参数的区间估计
- (0-1)分布参数的区间估计:设总体
由得到,记
6. 单侧置信区间
1. 单侧置信区间
- 单侧置信下限:对于给定值
- 单侧置信上限:对于给定值
2. 常见单侧置信区间

__EOF__

本文作者:RadiumGalaxy
本文链接:https://www.cnblogs.com/RadiumGalaxy/p/16974392.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!
本文链接:https://www.cnblogs.com/RadiumGalaxy/p/16974392.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!
标签:
Courses


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧
· 园子的第一款AI主题卫衣上架——"HELLO! HOW CAN I ASSIST YOU TODAY
· 【自荐】一款简洁、开源的在线白板工具 Drawnix