02 线性表 | 数据结构与算法
1. 线性表
- 线性表的定义
- 特点:
- 存在唯一一个被称为第一个的数据元素
- 存在唯一一个被称为最后一个的数据元素
- 除了第一个元素之外,其他的数据元素都有唯一一个直接前驱
- 除了最后一个元素之外,其他的数据元素都有唯一一个直接后驱
- 定义:是由
- 逻辑特征
- 有限性:数据元素的个数是有限的
- 相同性:数据元素的元素类型是相同的
- 相继性(线性性):
- 基本操作
- 求线性表的长度
Lenlist(L) - 获取线性表中的元素
GetElem(L , i) - 通过值来查找线性表当中的元素
SearchElem(L , Val) - 插入元素
InsertElem(L , i , Elem) - 删除元素
DeleteElem(L , i)
- 求线性表的长度
- 特点:
- 线性表的存储结构设计
-
连续存储结构(数组)
- 存储方式:依次将元素存放进连续的存储空间中
- 顺序表示:
- 存储特点:逻辑上相邻的元素,物理结构上也相邻
- 连续存储的优缺点
- 优点
- 顺序表的存储结构简单
- 随机存储,按位置取值速度快
- 存储效率高,无需增加逻辑关系的占用空间
- 缺点
- 删除插入速度慢
- 预先分配内存大
- 优点
-
-
链式存储结构
- 存储方式:用一组任意的存储单元存储线性表中的数据元素,通过每个结点的指针将数据元素连接在一起
- 单链表:具有一个指针,指向后继元素
- 双链表:前驱指针
*prev和后继指针*next
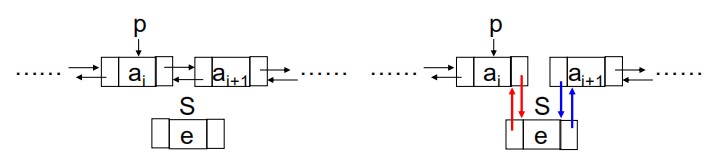
- 连续设计和连接设计的对比
Parameters 连续设计 链接设计 表的容量 固定,不易扩充 灵活,易扩充 存取操作 随机访问存取,速度快 顺序访问存取,速度慢 时间 插入、删除操作费时间 访问元素费时间 空间 估算长度,浪费空间 实际长度
- 链接存储设计的数组实现
data next data1 1 2 max_size - 1 -1 - 结点:
- 初始化
- 结点
node的分配
- 结点
node的回收
- 静态链表查找算法
2.
-
合并有向链表
-
反转链表
- 就地反转
反转箭头为:
- 递归:处理好
k之后,将k-1的箭头倒转;
__EOF__

本文作者:RadiumGalaxy
本文链接:https://www.cnblogs.com/RadiumGalaxy/p/16750343.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!
本文链接:https://www.cnblogs.com/RadiumGalaxy/p/16750343.html
关于博主:评论和私信会在第一时间回复。或者直接私信我。
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!
标签:
Courses


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 分享一个免费、快速、无限量使用的满血 DeepSeek R1 模型,支持深度思考和联网搜索!
· 基于 Docker 搭建 FRP 内网穿透开源项目(很简单哒)
· ollama系列01:轻松3步本地部署deepseek,普通电脑可用
· 按钮权限的设计及实现
· 25岁的心里话