
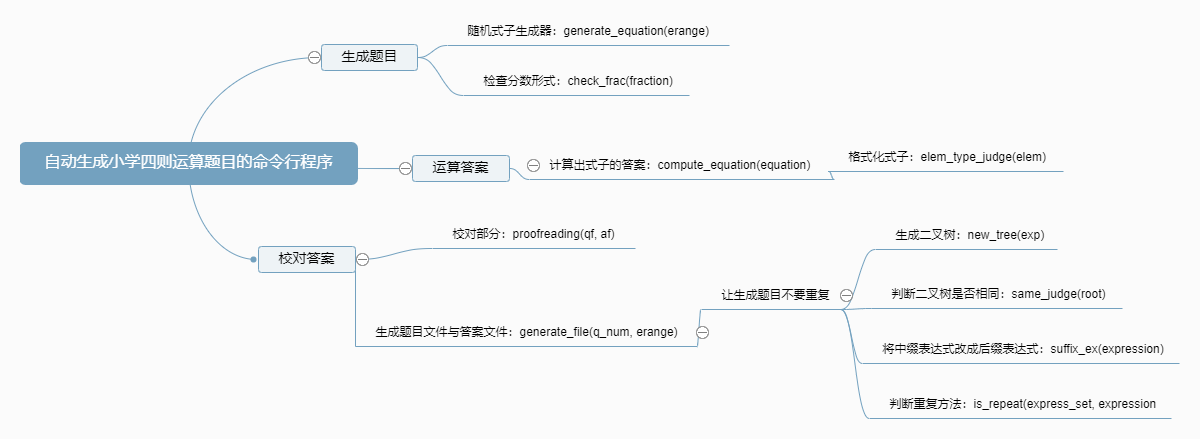
自动生成小学四则运算题目的命令行程序(基于python)
项目|内容
--|:--😐--:
这个作业属于哪个课程|软件工程
这个作业要求在哪里|作业要求
这个作业的目标|自动生成小学四则运算题目的命令行程序
这个作业的成员|3218005395 郭泽纯,3218005397 刘烷婷
Github链接
- GitHub: 作业链接
PSP表格
| 项目 | 内容 | 预估耗时(分钟) | 预估耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 80 |
| Estimate | 估计这个任务需要多少时间 | 150 | 150 |
| Development | 开发 | 600 | 660 |
| Analysis | 需求分析 (包括学习新技术) | 360 | 350 |
| Design Spec | 生成设计文档 | 160 | 180 |
| Design Review | 设计复审 | 30 | 40 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 40 |
| Design | 具体设计 | 60 | 60 |
| Coding | 具体编码 | 60 | 150 |
| Code Review | 代码复审 | 30 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 240 | 300 |
| Reporting | 报告 | 60 | 30 |
| Test Repor | 测试报告 | 60 | 30 |
| Size Measurement | 计算工作量 | 10 | 20 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 20 | 10 |
| total | 合计 | 1890 | 2130 |
效能分析
-
以下是pycharm自带的效能分析工具profile进行效能分析的结果

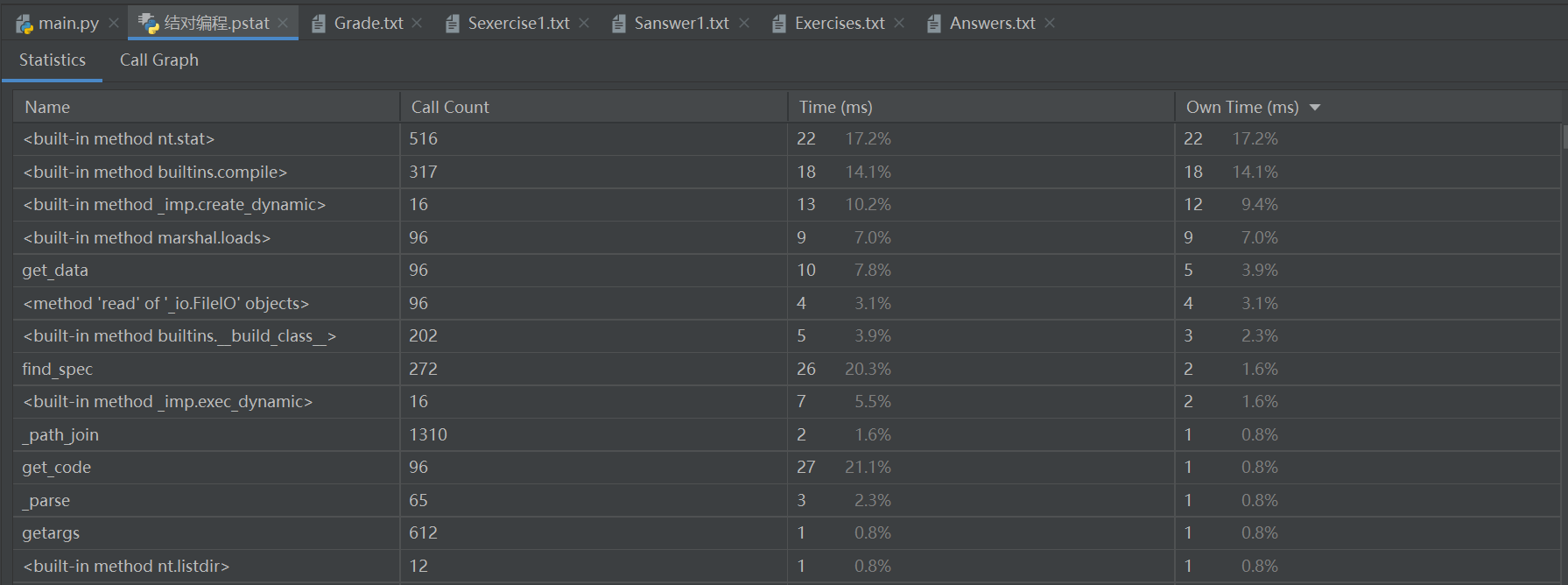
从上述结果中,可以看到,由于在题目查重中,使用了转换逆波兰表达式(suffix_ex(expression)),二叉树排序等算法,程序运行时间较长。经过思考后,很遗憾我们仍找到更优算法去进行优化。希望在积累了更多的项目经验后,我们能将代码进行优化。
设计实现过程及重要代码说明
- 项目文件各功能如下:
文件|功能
--|:--😐--:
main.py|主程序
Exercises.txt|生成的四则运算题目文档
Answers.txt|生成的答案文档
Grade.txt|统计答案对错的数量文档
Sexercises1.txt|给定的的四则运算题目文档
Sanswers1.txt|给定的答案文档
-
本次设计由生成随机四则运算题目,根据生成题目运算出答案,校对生成的答案三个部分组成
-
main函数
- 使用 -n 参数控制生成题目的个数及使用 -r 参数控制题目中数值(自然数、真分数和真分数分母)的范围,实现代码如下:
def main():
try:
# sys.argv[1:5]只读取前四个输入字符 parameter1/parameter2为两个参数
s1, parameter1, s2, parameter2 = sys.argv[1:5]
res = raise_ex(s1, s2)
if res == 1:
n = parameter1
r = parameter2
generate_equation(r)
generate_file(n, r)
print("生成题目成功!请查看 'Exercises.txt' 和 'Answers.txt'\n")
elif res == 2:
e = parameter1
a = parameter2
proofreading(e, a)
print("校对完成!请在 'Grade.txt' 查看结果\n")
except BaseException:
print("Error:输入命令错误,请检查后重新输入")
- 随机式子生成器:generate_equation(erange)
- 设置一个生成题目的函数,使用numpy库,(因为numpy比python列表速度要快得多,numpy数组本身能节省内存,并且numpy在执行算术、统计和线性代数时采 用了优化算法)
通过np.random.randint()来产生随机整数,np.random.rand()来生成随机小数,然后再转化为分数,再添加运算符号,实现代码如下:
- 设置一个生成题目的函数,使用numpy库,(因为numpy比python列表速度要快得多,numpy数组本身能节省内存,并且numpy在执行算术、统计和线性代数时采 用了优化算法)
def generate_equation(erange):
# erange = 20 # 控制题目中数的大小
operator = [' + ', ' - ', ' x ', ' ÷ ']
end_opt = ' ='
# 随机生成自然数和分数的个数,但控制总和不超过4,从此控制题目不超过三个运算符
nnature, nfraction = np.random.randint(1, 3, size=2)
# print(nnature,nfraction)
lnature = [str(x) for x in np.random.randint(1, erange, size=nnature)] # 产生1-erange之间的自然整数
# print(lnature)
# np.random.rand()产生的是0-1之间的小数,产生的个数是根据参数nfraction来定的,round()根据四舍五入来取值,+0.5是为了防止取值后为0
lfloat = [str(round(x + 0.5, 1)) for x in np.random.rand(nfraction)]
lfraction = list()
# decimal.Decimal()把lfloat中字符串类型转化为十进制数据,然后用fractions.Fraction()再次转化为分数,最后通过check_frac来整理为带分 数,添加至lfraction
for fraction in [fractions.Fraction(decimal.Decimal(x)) for x in lfloat]:
lfraction.append(check_frac(fraction))
equation = ''
bag = lnature + lfraction # 将生成的自然整数和分数存在bag里
# print(bag)
len_bag = len(bag)
for it in range(len_bag):
randint = np.random.randint(len(bag))
equation += bag[randint] # 取数
if it < len_bag - 1: # len_bag-1即是it的最大取值,所以当it<len_bag时,后面加随机操作符
equation += operator[randint] # 当it>=len_bag时,把等号补上,式子完成,跳出循环
else:
equation += end_opt
bag.pop(randint) # 当数取出的时候,应该把它从bag里去除
# print(equation)
return equation
- 检查分数形式:def check_frac(fraction)
- 通过判断分子和分母的大小来判断真假分数,遇到假分数则转化为带分数,实现代码如下:
def check_frac(fraction):
if fraction.numerator > fraction.denominator: # 分子大于分母,即假分数
mixed = fraction.numerator // fraction.denominator # 提取带分数前面的整数
if fraction - mixed == 0:
frac_str = '{}'.format(mixed)
else:
frac_str = '{}`{}'.format(mixed, fraction - mixed)
else:
frac_str = str(fraction)
return frac_str
- 计算答案函数:compute_equation(equation)
- 设置一个生成答案的函数,通过对式子进行分割,然后格式化形式,通过eval()函数返回式子答案,实现代码如下:
def compute_equation(equation):
lequation = equation.split(' ') # 将式子进行分割,则遇到空格就截取,分割完成后显示[数字+符号]
# print(lequation)
for it in range(len(lequation)):
etype = elem_type_judge(lequation[it])
if etype == 'f':
if '`' in lequation[it]:
tnum, frac = lequation[it].split('`') # 把带分数分割成整数和分数
# print(tnum,frac)
lequation[it] = '({}+fractions.Fraction(\'{}\'))'.format(tnum, frac)
# print(lequation[it])
else:
lequation[it] = 'fractions.Fraction(\'{}\')'.format(lequation[it])
elif etype == 'n':
lequation[it] = 'fractions.Fraction(\'{}\')'.format(lequation[it])
elif etype == 'o':
if lequation[it] == '÷':
lequation[it] = '/'
if lequation[it] == 'x':
lequation[it] = '*'
elif etype == 'e':
lequation[it] = ''
fequation = ''.join(lequation)
try:
result = eval(fequation)
if result < 0:
return '-1'
else:
# print(check_frac(result))
return check_frac(result)
except ValueError:
print('the equation is wrong')
return '-1'
- 判断重复方法:is_repeat(express_set, expression),实现代码如下:
- 其中包含了将中缀表达式转为后缀表达式(逆波兰表达式)的方法:suffix_ex(expression):
- 然后将得出的结果转为二叉树,并进行排序,生成一个字符串:new_tree(exp)
比较当前表达式与列表中表达式所生成的字符串是否相同,若相同,则说明发生重复:same_judge(root)
def is_repeat(express_set, expression):
a = suffix_ex(expression) # expression转化为后缀表达式
a_tree = new_tree(a) # 再生成二叉树
for it in express_set:
b_suffix = suffix_ex(it) # expression_set的其中一个expression转化为后缀表达式转化为后缀表达式
b_binary_tree = new_tree(b_suffix)
if same_judge(a_tree) == same_judge(b_binary_tree): # 判断两个二叉树是否相同
return True
return False
- 异常处理:raise_ex(s1, s2)
- 简单的异常处理机制,就是在通过命令行输入参数时,除了-n -r还有-e -a这两种标准输入外,其他均视为非法输入,
显示“输入命令错误,请检查后重新输入”,实现代码如下:
- 简单的异常处理机制,就是在通过命令行输入参数时,除了-n -r还有-e -a这两种标准输入外,其他均视为非法输入,
raise_ex(s1, s2):
if s1 == '-n' and s2 == '-r': # 当输入-n xx -r xx 时,即是生成题目和答案的过程
return 1
elif s1 == '-e' and s2 == '-a': # 当输入-e xx -a xx 时,即是校对给定题目和答案的过程
return 2
else:
ex = Exception('Error:参数格式错误!')
raise ex
测试运行
-
生成题目的个数为10,题目中数值(自然数、真分数和真分数分母)的范围10
-
命令行输入 python main.py -n 10 -r 10
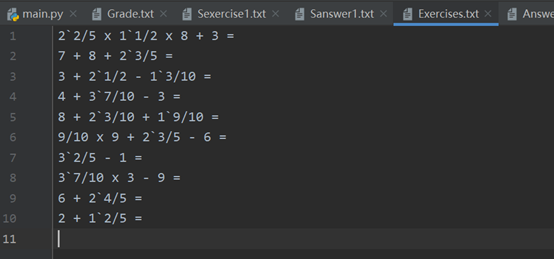
可以生成题目文件 Exercises.txt和答案文件 Answers.txt
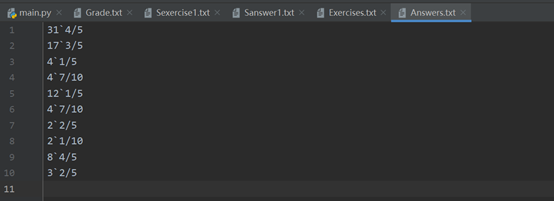
-
命令行输入 python main.py -e 给定的题目文件 -a 给定的答案文件
可以生成校对完成后的文件Grade.txt
全对的情况如下:

-
手动将第三个答案修改(正确答案是4,改为24),可以看到准确给出错误的数量还有哪些题错了,正确的数量还有哪些题做对了也都有给出
其中“:”后面的数字5表示对/错的题目的数量,中括号内的是对/错题目的编号。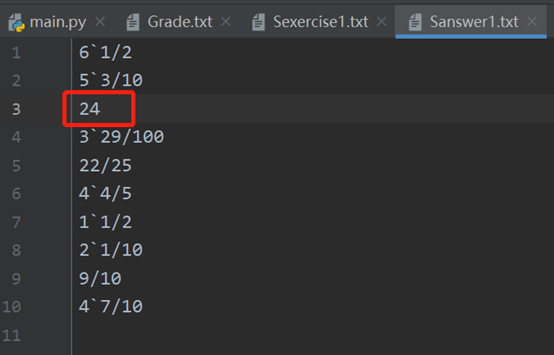

-
若输入的命令行形式有错误,则会触动异常处理机制,输出 Error:输入命令错误。
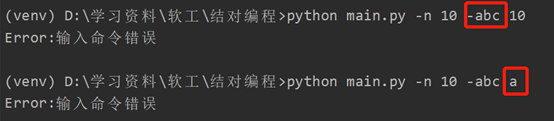
-
-
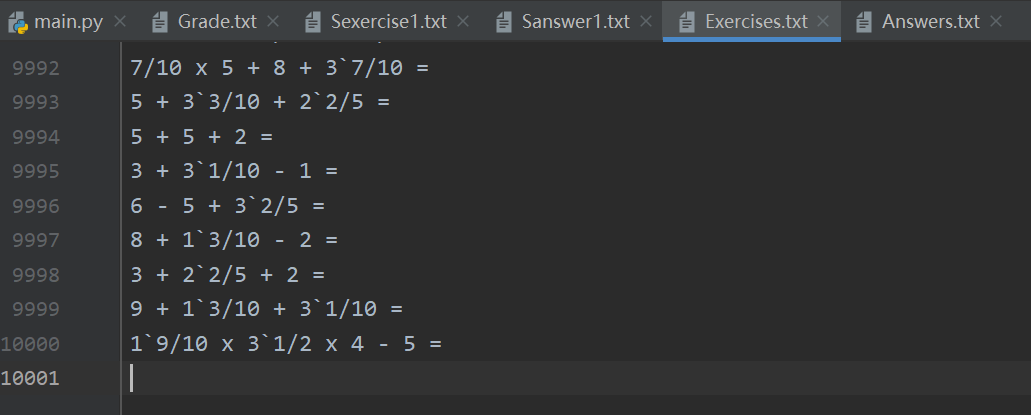
可支持10000条题目与答案的生成:
生成题目的个数为10000,题目中数值(自然数、真分数和真分数分母)的范围最大值为10

项目小结
-
郭泽纯:刚开始看到题目,我感觉这个项目对我自己来说还是蛮有难度的,但想到还有一个队友可以共同完成,心里就踏实了一点。收获颇多,再次让我见到了很多没接触过的知识以及对pycharm的运用更加熟悉,通过借鉴网上的思路以及交流彼此的想法,在两人的共同努力下完成了这个项目,当然还有需要优化的地方。还有之前并没有参加过团队开发,所以这次也让我体会到了团队合作的重要性,相互学习,共同进步。
-
刘烷婷:从项目设计到项目实现的过程中,我深刻体会到结对合作跟单枪匹马编程是不一样的。在两个人的合作中,会有意见相左的地方,这时候就需要磨合;但大部分时候我们都是融洽协作的。在共同进行项目设计后,我们各自认领了不同模块的函数编写任务,在规定时间内完整编写,并进行代码的整合。在编写博客的时候我们也是分别写不同的板块,有什么问题就及时跟对方进行交流,最后完成了博客。我觉得写得还不错!毕竟这是我们合作的成果。这次跟泽纯同学的结对编程很愉快我从中学习到了许多,希望下一次也能跟她合作!

